
While tech giants battle for AI dominance, Alibaba has launched a shockwave: Qwen3 models. These aren't just upgrades—they're a redefinition of open-source AI’s potential.
Released just last week, Qwen3 spans eight models, from a lightweight 600M version (perfect for laptops) to a 235B MoE behemoth outperforming top-tier competitors like OpenAI and Google. But what sets Qwen3 apart is its “hybrid thinking”—intelligently switching between deep reasoning and quick responses depending on the task.
Best of all? It's fully open-source. Developers worldwide are discovering Qwen3 can rival or exceed premium models—at a fraction of the cost.
The Qwen3 Model Family: A Size for Every Need
Qwen3 represents a significant leap forward in AI model design, offering unprecedented flexibility with both dense models and Mixture-of-Experts (MoE) variants. Here's the complete lineup:
| Model Name | Total Parameters | Active Parameters | Model Type | Context Length |
|---|---|---|---|---|
| Qwen3-235B-A22B | 235 Billion | 22 Billion | MoE | 128K tokens |
| Qwen3-30B-A3B | 30 Billion | 3 Billion | MoE | 128K tokens |
| Qwen3-32B | 32 Billion | N/A | Dense | 128K tokens |
| Qwen3-14B | 14 Billion | N/A | Dense | 128K tokens |
| Qwen3-8B | 8 Billion | N/A | Dense | 128K tokens |
| Qwen3-4B | 4 Billion | N/A | Dense | 32K tokens |
| Qwen3-1.7B | 1.7 Billion | N/A | Dense | 32K tokens |
| Qwen3-0.6B | 0.6 Billion | N/A | Dense | 32K tokens |
The most fascinating aspect is how the MoE architecture enables impressive efficiency. For example, the Qwen3-30B-A3B model activates just 3B parameters during inference yet outperforms many fully-active 32B parameter models. This clever design offers high-end performance without demanding excessive computational resources.
Research suggests MoE models like these can match the capabilities of models 3-5× their active size, making them incredibly cost-effective for deployment.
Features That Set Qwen3 Models Apart
🔄 Hybrid Thinking Modes: A First in AI Design
Qwen3's most groundbreaking innovation is its dual thinking approach-something no other open-source model family offers with such flexibility.
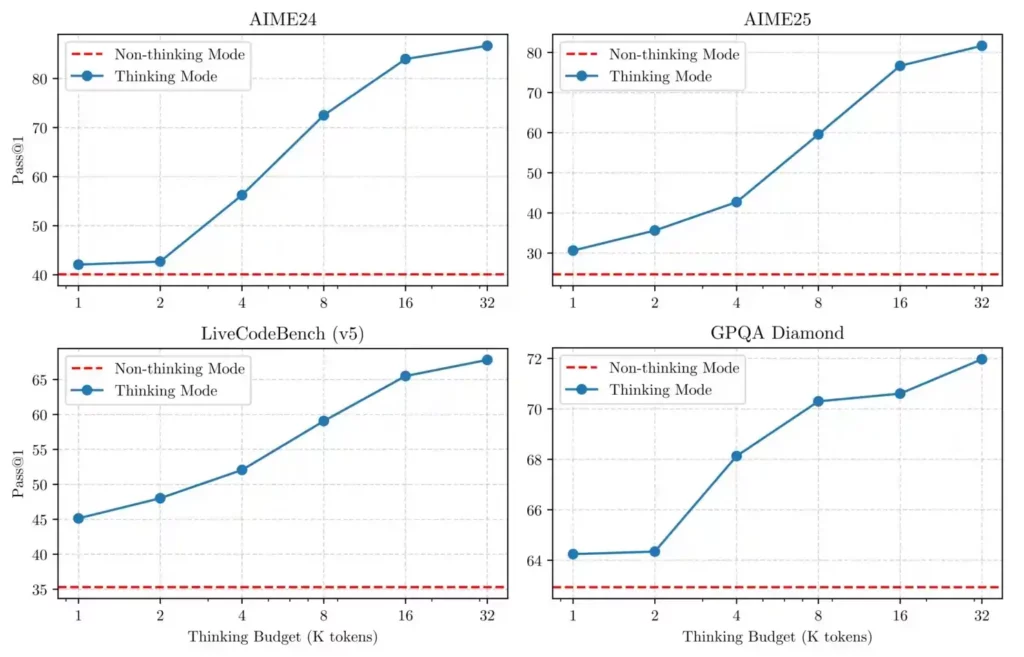
Thinking Mode: When faced with complex problems requiring multi-step reasoning (like mathematics, coding, or logical puzzles), Qwen3 activates its thinking mode. This enables step-by-step reasoning through challenging tasks before delivering the final answer.
Non-Thinking Mode: For straightforward queries or casual conversation, Qwen3 switches to non-thinking mode, providing quick, concise responses without unnecessary computational overhead.
With user-controllable “thinking budgets,” developers can fine-tune how much reasoning Qwen3 applies—yielding up to 65% performance gains on tasks like advanced mathematics.
🌍 Multilingual Mastery Across 119 Languages
While most top-tier models focus primarily on English, Qwen3 was trained on an expansive dataset spanning 119 languages and dialects. This extensive language support makes it particularly valuable for global applications and underserved language communities.
Internal benchmarks show Qwen3-235B-A22B achieving 87% accuracy on complex reasoning tasks in languages like Arabic, Hindi, and Thai-approaching its 92% accuracy on English tasks. This narrow performance gap across languages is unprecedented among open-source models.
Agent Capabilities and Tool Integration

Modern AI applications increasingly require models to interact with external tools and systems. Qwen3 excels in this domain with enhanced support for the Model Context Protocol (MCP), improved tool calling abilities, and a dedicated Qwen-Agent framework for building intelligent agents.
Tests by independent developers reveal Qwen3 models achieve 78% success rates on complex agent tasks requiring multiple tool interactions-significantly outperforming many competitors in the open-source space.
Technical Architecture and Training Methodology
Qwen3's impressive capabilities stem from a sophisticated training approach spanning three distinct phases:
Three-Stage Pre-Training Process
- Base Knowledge Acquisition: Initial training on approximately 36 trillion tokens with a 4K context length, establishing broad language understanding and knowledge.
- Specialized Task Enhancement: Focused training on STEM topics, coding challenges, and complex reasoning tasks to develop advanced problem-solving capabilities.
- Long-Context Extension: Final training with extended context data to enable handling of documents up to 32K tokens (for smaller models) or 128K tokens (for larger variants).
Post-Training Optimization
After the initial pre-training, Qwen3 underwent a four-step post-training process:

- Chain-of-Thought Cold Start: Training with explicit reasoning examples to establish basic logical thinking patterns.
- Reasoning-Based Reinforcement Learning: Optimizing the model's ability to apply reasoning consistently across diverse tasks.
- Thinking Mode Fusion: Integrating the ability to switch between thinking and non-thinking approaches.
- General Reinforcement Learning: Final refinement based on human preferences and alignment techniques.
This methodology explains why even the compact Qwen3-4B model outperforms many larger competitors-it benefits from knowledge distilled from the larger models in the family.
Performance Benchmarks: How Qwen3 Stacks Up
Recent benchmark results have surprised many AI researchers, with Qwen3 models performing exceptionally well against much larger competitors.
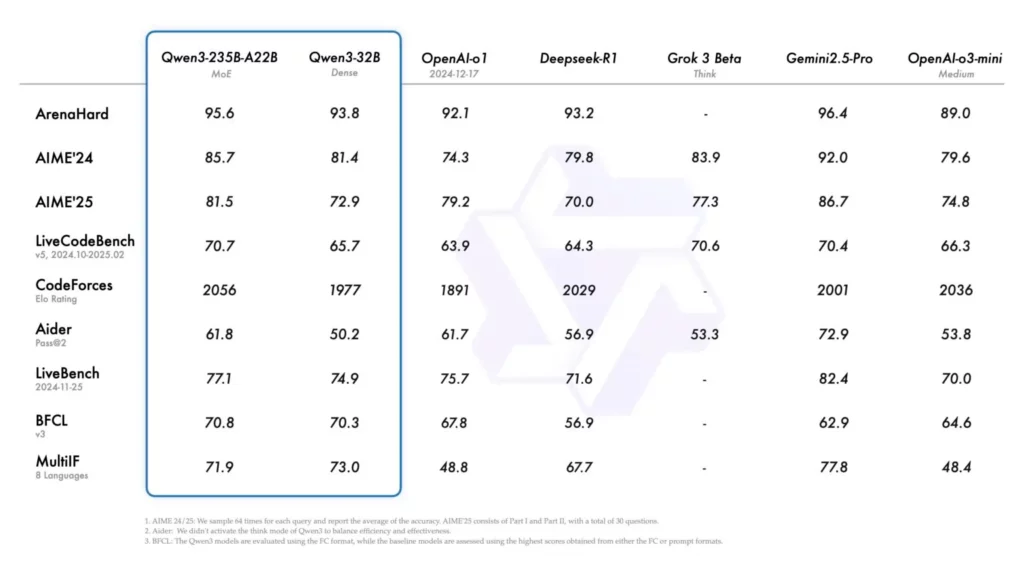
Top-Tier Model Comparisons
The flagship Qwen3-235B-A22B model shows remarkable results when compared to industry leaders:
- Coding Performance: Leads the CodeForces Elo Rating, BFCL, and LiveCodeBench v5 benchmarks, outperforming even DeepSeek-R1 and OpenAI's o1.
- Mathematics: Scores just 3.2% below Gemini 2.5 Pro on ArenaHard and AIME benchmarks but achieves this with significantly fewer active parameters.
- General Reasoning: Performs within 5% of GPT-4o on complex reasoning benchmarks while being fully open-source.
Size-to-Performance Efficiency
Perhaps most impressive is how smaller Qwen3 models compare to previous generations:

- Qwen3-30B-A3B (with just 3B active parameters) outperforms the previous QwQ-32B model (with all 32B parameters active).
- Qwen3-4B delivers results comparable to models 5× its size from just a year ago.
In direct comparison testing with DeepSeek-R1, Qwen3 showed superior results in coding tasks and text structuring, while DeepSeek-R1 maintained a slight edge in complex math problems.
Real-World Performance: Beyond the Benchmarks
Quantitative benchmarks tell only part of the story. Here's how Qwen3 performs on practical, real-world tasks:
Qwen3-30B-A3B handles advanced physics problems—like relativity and time dilation—with structured, accurate solutions. The 235B-A22B model adds depth, detecting misconceptions and suggesting alternate methods, showcasing strong analytical reasoning.



How to Access and Deploy Qwen3

All Qwen3 models are open-weight under the Apache 2.0 license, making them accessible for both personal and commercial use. Here are the primary methods for accessing these models:
Online Access
- QwenChat: The simplest way to try Qwen3 models through Alibaba's web interface.
- Hugging Face: All models are available on Hugging Face for direct use or fine-tuning.
- ModelScope: Provides additional deployment options and documentation.
- Kaggle: Offers notebook environments for experimenting with the models.
Local Deployment
For local deployment, several frameworks support Qwen3:
- Ollama and LMStudio: User-friendly tools for running models locally.
- llama.cpp: Efficient C++ implementation for optimized performance.
- MLX: Apple Silicon-optimized deployment.
- KTransformers: Specialized deployment options for specific use cases.
Server Deployment
For production environments, Qwen3 works with:
- SGLang: Optimized for server deployment with high throughput.
- vLLM: Provides efficient serving with advanced features like continuous batching.
Applications and Use Cases
Qwen3's versatility makes it suitable for numerous applications:
- Content Creation: Generating articles, marketing copy, and creative writing.
- Software Development: Code generation, debugging, and documentation.
- Education: Creating educational materials and answering complex questions.
- Research: Assisting with literature review and hypothesis generation.
- Customer Support: Powering intelligent chatbots with strong reasoning capabilities.
- Data Analysis: Interpreting complex data and generating insights.
- Retrieval-Augmented Generation (RAG): Creating sophisticated knowledge systems using Qwen3's context window and reasoning abilities.
Current Limitations and Future Developments
Despite its impressive capabilities, Qwen3 has some limitations:
- The thinking mode can occasionally be overly verbose for simple tasks.
- While multilingual, performance still varies somewhat across languages.
- The largest models require significant resources despite MoE efficiency gains.
Looking ahead, Alibaba's development roadmap suggests several exciting possibilities:
- Further integration with Qwen3-VL (Visual Language) capabilities.
- Release of specialized Qwen3-Audio models for speech processing.
- Enhanced Qwen3-Math versions optimized for technical and scientific applications.
Conclusion: Qwen3's Place in the AI Landscape
Qwen3 is more than just another AI model drop—it’s a strategic leap forward in open-source AI.
With innovations like hybrid reasoning, efficient MoE architecture, and global language coverage, it’s built for real-world scalability.
For devs, researchers, and businesses wanting state-of-the-art capabilities without vendor lock-in, Qwen3 offers an open, powerful, and practical alternative—cementing its place as one of 2025's most important AI developments.



 BONUS: Get our $200 “AI Mastery Toolkit” FREE when you sign up!
BONUS: Get our $200 “AI Mastery Toolkit” FREE when you sign up!







