
Prompt tweaks alone no longer cut it for enterprise AI systems. As model context windows balloon past 200k tokens, engineers now wrap the LLM with documents, retrieval pipelines, scratch-pads, and tool calls—an approach branded context engineering.
The shift happened fast.
Context engineering bridges this gap by treating the entire AI environment as a system rather than focusing on individual inputs.
Context Engineering:
The System That Actually Works
Context engineering treats the entire pipeline before the LLM call as engineerable infrastructure. Think of an LLM's context window as RAM – it has limited working memory that determines what the model can process.
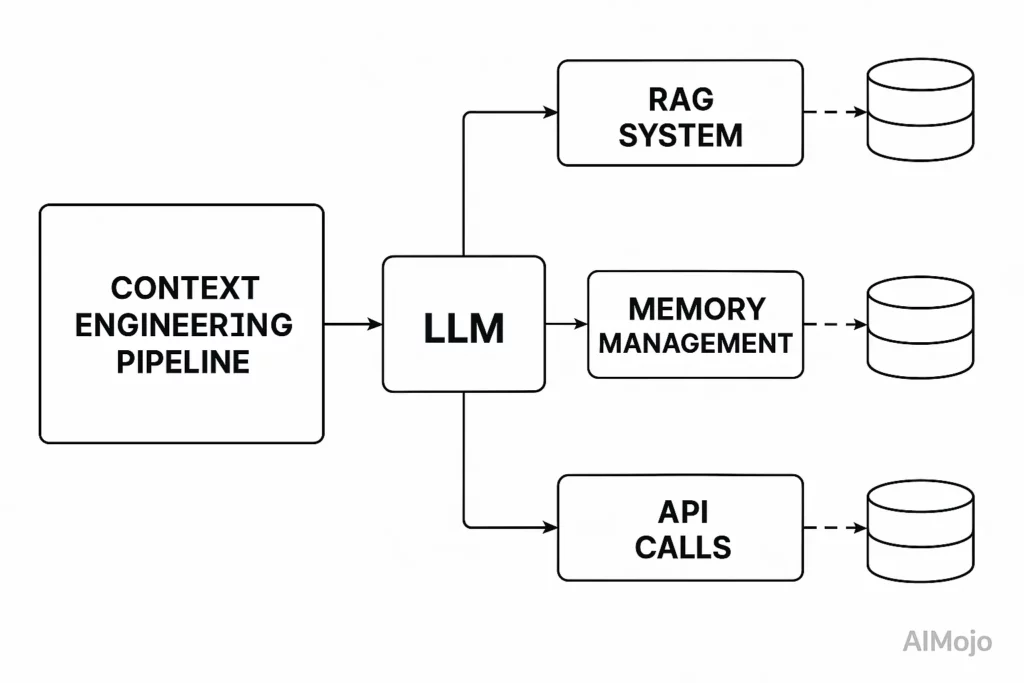
Just as an operating system carefully manages what goes into RAM, context engineering curates what information fills the LLM's context window.
Here's what context engineering actually includes:
Context Engineering vs Prompt Engineering:
The Numbers Don’t Lie
| Aspect | Prompt Engineering | Context Engineering |
|---|---|---|
| Focus | Crafting one input string | Orchestrating every signal around the model |
| Average Dev Time | 70% prompt tweaks | 60% data pipelines, 20% memory rules, 20% prompts |
| Typical Failure Mode | Sudden drop in output quality after data drift | Resilient via RAG, memory, tool calls |
Quick example: A customer-support bot trained with prompts alone can recall refund policy when asked directly. When the user references “order 45791,” it fails. Add context engineering—conversation history plus a RAG query into the order database—and the bot instantly pulls purchase details and recommends the correct refund process.
The Four Pillars of Context Engineering That Actually Matter
1. Writing Context (Your AI's Note-Taking System)
Writing context means saving information outside the context window for future use. This preserves valuable token space while maintaining access to important data.
Scratchpads work like note-taking for agents within a single session. Anthropic's multi-agent researcher saves its initial plan to “Memory” because if the context exceeds 200,000 tokens, it gets truncated and the plan is lost.

Long-term memories retain information across multiple sessions. Examples include ChatGPT auto-generating user preferences from conversations, and Cursor/Windsurf learning coding patterns and project context.

2. Context Selection (The Art of Choosing What Matters)
Context selection brings in just the relevant information for the task at hand.
When an AI fitness coach generates a workout plan, it must select context details that include the user's height, weight, and activity level, while ignoring irrelevant information.
The key insight: More information isn't always better. Effective context engineering means selecting the right combination for each specific task.
3. Context Compression (Fitting More Into Less)
When conversations grow so long that they exceed the LLM's memory window, context compression becomes critical. Agents typically accomplish this by summarizing earlier parts of the conversation.

4. Context Isolation (Divide and Conquer)
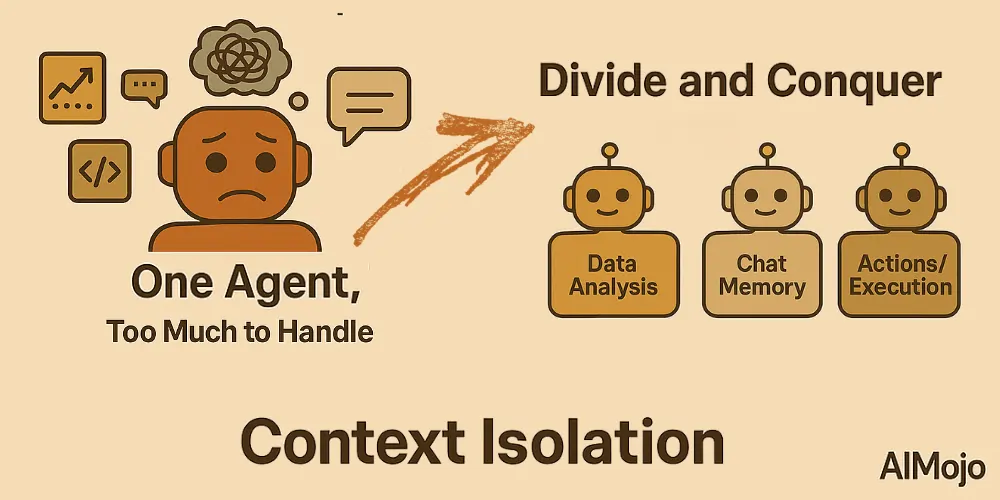
Context isolation means breaking down information into separate pieces so agents can better handle complex tasks. Instead of cramming all knowledge into one massive prompt, developers split context across specialized sub-agents or sandboxed environments.
Real-World Context Engineering in Action
The Customer Service Revolution
| Before context engineering | After context engineering |
|---|---|
| Generic chatbots that forget previous conversations and provide irrelevant answers. | AI agents that remember your purchase history, access real-time inventory data, and coordinate with human agents when needed. |
The Coding Assistant That Never Forgets
The system: When you ask “How do I fix this authentication bug?” the context engineering system automatically:

Instead of generic coding advice, you get specific solutions tailored to your actual codebase.
The Technical Architecture That Powers Context Engineering
Dynamic Context Assembly
Context is built on the fly, evolving as conversations progress. This includes:
- Retrieving relevant documents
- Maintaining memory
- Updating user state
- API calls and database queries
Context Window Management
With fixed-size token limits (32K, 100K, 1M), engineers must compress and prioritize information intelligently using:
- Scoring functions (TF-IDF, embeddings, attention heuristics)
- Summarization and saliency extraction
- Chunking strategies and overlap tuning

Security and Consistency
Apply principles like prompt injection detection, context sanitization, PII redaction, and role-based context access control.
Building Your First Context Engineering System
Building a context engineering workflow isn't just theory―it's a repeatable process that can be operationalized and even automated. Here’s how you can put it into practice:
Step 1: Map Out Your Context Sources
Identify where your agent needs to pull information from (docs, databases, APIs, previous chats, etc.).
python
# Example: Fetching relevant documents using embeddings
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer("all-MiniLM-L6-v2")
query = "project status update"
corpus = ["spec doc", "requirements", "last week's meeting notes"]
query_embedding = model.encode(query, convert_to_tensor=True)
corpus_embeddings = model.encode(corpus, convert_to_tensor=True)
hits = util.semantic_search(query_embedding, corpus_embeddings, top_k=2)[0]
relevant_docs = [corpus[hit['corpus_id']] for hit in hits]
Step 2: Implement Memory & Writing Context
Store important information so it’s always there for future tasks.
python
import json
def save_to_memory(memory_path, user_id, data):
with open(memory_path, "r+") as file:
memory = json.load(file)
memory[user_id] = data
file.seek(0)
json.dump(memory, file)
file.truncate()Step 3: Build Context Selection & Compression Logic
Develop rules or models that pick only what’s most relevant for the task. Compress lengthy histories into summarized forms.
python
def summarize_conversation(history):
# Placeholder for use with an LLM summarizer or custom rules
return history[-5:] # Only the last 5 messagesStep 4: Isolate Contexts for Agent Coordination
Split information so each agent or component handles only what it should.
python
user_profile_ctx = {"user_goals": "..."}
task_specific_ctx = {"current_task": "..."}
external_data_ctx = {"live_data": "..."}
full_context = {**user_profile_ctx, **task_specific_ctx, **external_data_ctx}Step 5: Output Structuring and API Readiness
Format the output context consistently so it's predictable for downstream LLM calls or API endpoints.
python
schema = {
"user": {"age": 35, "goal": "muscle gain"},
"plan": "high protein, 3x/week weight training"
}Step 6: Monitor, Iterate, and Secure
Track failures, audit context quality, and improve logic for context inclusion, memory, and retrieval. Always sanitize inputs to avoid prompt injection and data leaks.
Why Context Engineering Pays More Than Prompt Engineering
Companies need engineers who can build systems that provide the right context to AI, keep information accurate and up-to-date, and protect users by adding safety guidelines.
The market reality: Context engineering requires cross-functional skills that involve understanding business use cases, defining outputs, and structuring information so LLMs can accomplish complex tasks.
Bottom line: Anyone can write prompts. Building context-aware agents that remember, adapt, and select context at scale? That’s how developers future-proof their skills and deliver actual value with advanced LLM applications.



 BONUS: Get our $200 “AI Mastery Toolkit” FREE when you sign up!
BONUS: Get our $200 “AI Mastery Toolkit” FREE when you sign up!






