
尽管科技巨头们争夺 AI 阿里巴巴已经掀起了一股冲击波: Qwen3 模型。这些不仅仅是升级——它们是对开源人工智能潜力的重新定义。
Qwen3 于上周发布,涵盖 八种型号,从轻量级 600M 版本(适合笔记本电脑)到 235B MoE 庞然大物 超越 Open 等顶级竞争对手AI 以及谷歌。但 Qwen3 的独特之处在于 “混合思维”—根据任务在深度推理和快速响应之间智能切换。
最好的? It's 完全开源。 全球各地的开发人员发现 Qwen3 可以与高端机型相媲美甚至超越高端机型,而成本却只是后者的一小部分。
Qwen3 型号系列:满足各种需求的尺寸
Qwen3 代表了 AI 模型设计,为密集模型和 混合专家 (MoE)变体。这里's 完整阵容:
| 型号名称 | 总参数 | 活动参数 | 型号型号 | 上下文长度 |
|---|---|---|---|---|
| Qwen3-235B-A22B | 235亿 | 22亿 | 教育部 | 128K 代币 |
| Qwen3-30B-A3B | 30亿 | 3亿 | 教育部 | 128K 代币 |
| Qwen3-32B | 32亿 | 无 | 稠密 | 128K 代币 |
| Qwen3-14B | 14亿 | 无 | 稠密 | 128K 代币 |
| Qwen3-8B | 8亿 | 无 | 稠密 | 128K 代币 |
| Qwen3-4B | 4亿 | 无 | 稠密 | 32K 代币 |
| Qwen3-1.7B | 1.7亿 | 无 | 稠密 | 32K 代币 |
| Qwen3-0.6B | 0.6亿 | 无 | 稠密 | 32K 代币 |
最令人着迷的是 MoE 架构支持 令人印象深刻的效率。例如,Qwen3-30B-A3B 模型在推理过程中仅激活 3B 个参数,但其性能却优于许多完全激活的 32B 个参数模型。这种巧妙的设计无需过多的计算资源即可提供高端性能。
研究表明,此类 MoE 模型可以匹配其活跃尺寸 3-5 倍的模型的功能,从而使其部署极具成本效益。
Qwen3 型号的与众不同之处
🔄 混合思维模式: AI 工艺设计
Qwen3's 最具突破性的创新是其双重思维方式——这是其他开源模型系列所不具备的灵活性。
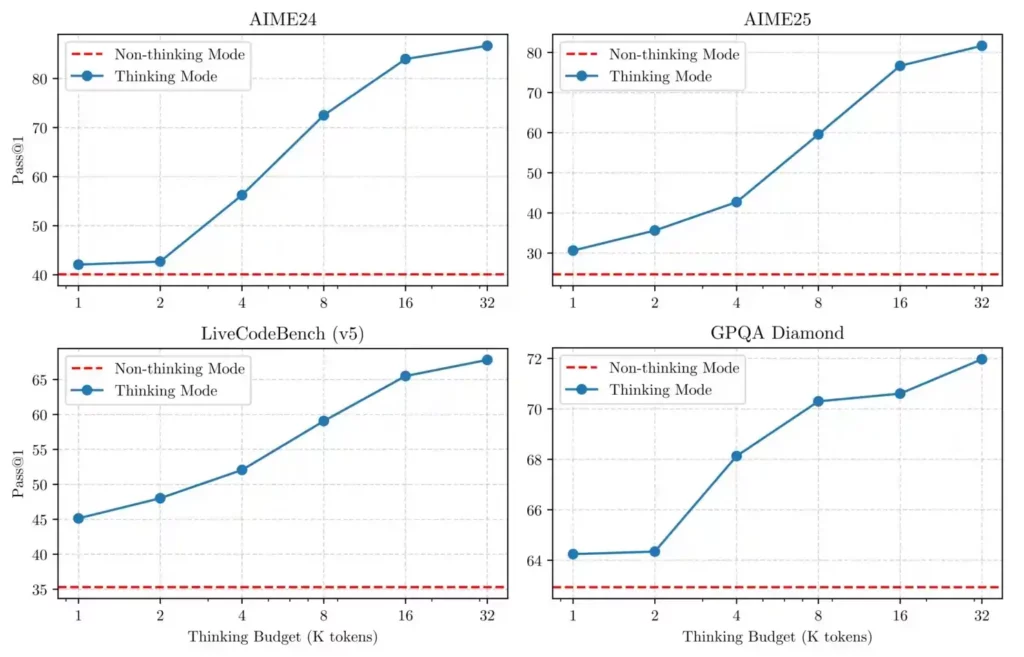
思考模式: 当面对需要多步推理的复杂问题(例如数学、编程或逻辑谜题)时,Qwen3 会启动其思维模式,逐步完成具有挑战性的任务,最终得出最终答案。
非思考模式: 对于简单的查询或随意的对话,Qwen3 会切换到非思考模式,提供快速、简洁的响应,而无需不必要的计算开销。
与 用户可控制的“思考预算”, 开发人员可以微调 Qwen3 的推理程度—— 性能提升高达 65% 完成高等数学等任务。
🌍 精通 119 种语言
虽然大多数顶级模型主要关注英语,但 Qwen3 的训练基于涵盖 119 种语言和方言的庞大数据集。这种广泛的语言支持使其对于全球应用和服务欠缺的语言社区尤为重要。
内部基准测试显示,Qwen3-235B-A22B 在阿拉伯语、印地语和泰语等语言的复杂推理任务中达到了 87% 的准确率,接近其在英语任务中 92% 的准确率。如此之小的跨语言性能差距在同类产品中是前所未有的。 开源模型.
代理功能和工具集成

现代 AI 应用程序越来越需要模型与外部工具和系统进行交互。Qwen3 在这方面表现出色,增强了对 模型上下文协议 (MCP)、改进的工具调用能力以及用于构建智能代理的专用 Qwen-Agent 框架。
独立开发人员的测试表明,Qwen3 模型在需要多种工具交互的复杂代理任务中实现了 78% 的成功率,大大优于开源领域的许多竞争对手。
技术架构与训练方法
Qwen3's 令人印象深刻的能力源于跨越三个不同阶段的复杂培训方法:
三阶段预训练过程
- 基础知识获取: 对具有 36K 上下文长度的约 4 万亿个标记进行初始训练,建立广泛的语言理解和知识。
- 专门任务增强: 重点培训 STEM 主题、编码挑战和 复杂推理 任务来培养高级解决问题的能力。
- 长上下文扩展: 使用扩展上下文数据进行最终训练,以便能够处理最多 32K 个标记(对于较小的模型)或 128K 个标记(对于较大的变体)的文档。
训练后优化
在最初的预训练之后,Qwen3 经历了四步的后训练过程:

- 思路链冷启动: 通过明确的推理示例进行训练,建立基本的逻辑思维模式。
- 基于推理的强化学习: 优化模型's 在不同任务中一致地运用推理的能力。
- 思维模式融合: 整合在思考和非思考方法之间切换的能力。
- 通用强化学习: 根据人类偏好和对齐技术进行最终改进。
这种方法解释了为什么即使是紧凑型 Qwen3-4B 模型也能胜过许多更大的竞争对手——它受益于从该系列中更大的模型中提炼出的知识。
性能基准:Qwen3 的表现如何
最近的基准测试结果让很多人感到惊讶 AI 研究人员表示,Qwen3 模型在与更强大的竞争对手的竞争中表现出色。
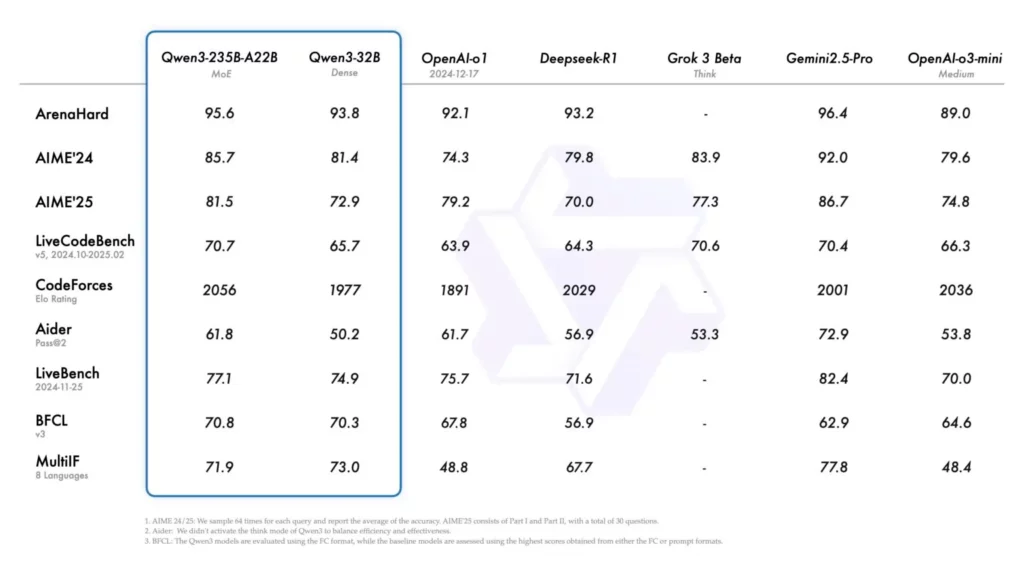
顶级模型比较
与行业领先者相比,旗舰 Qwen3-235B-A22B 型号表现出色:
- 编码性能: 在 CodeForces Elo Rating、BFCL 和 LiveCodeBench v5 基准测试中处于领先地位,甚至超越了 DeepSeek-R1 和 OpenAI's o1。
- 数学: 在 ArenaHard 和 AIME 基准测试中,得分仅比 Gemini 3.2 Pro 低 2.5%,但却以明显更少的活动参数实现了这一目标。
- 一般推理: 在完全开源的情况下,复杂推理基准上的表现与 GPT-5o 相差 4% 以内。
尺寸与性能的效率
也许最令人印象深刻的是 Qwen3 型号与前几代相比更小:

- Qwen3-30B-A3B(仅具有 3B 活动参数)的性能优于之前的 QwQ-32B 型号(所有 32B 参数均处于活动状态)。
- Qwen3-4B 的结果与一年前其尺寸 5 倍的模型的结果相当。
在直接比较测试中 DeepSeek-R1其中,Qwen3 在编码任务和文本结构化方面表现出色,而 DeepSeek-R1 在复杂的数学问题上保持着微弱的优势。
真实世界性能:超越基准
量化基准只能说明部分问题。这里's Qwen3 在实际现实任务中的表现如何:
Qwen3-30B-A3B 能够以结构化、精准的解决方案处理诸如相对论和时间膨胀等高级物理问题。235B-A22B 模型则进一步加深了学习者的深度,能够发现错误概念并提出替代方法,展现出强大的分析推理能力。



如何访问和部署 Qwen3

所有 Qwen3 模型均遵循 Apache 2.0 许可证,开放权重,可供个人和商业使用。访问这些模型的主要方法如下:
在线访问
- QwenChat: 通过阿里巴巴试用Qwen3模型的最简单方法's 网络界面。
- 拥抱脸: 所有模型均可在 Hugging Face 上直接使用或进行微调。
- 模型范围: 提供额外的部署选项和文档。
- Kaggle: 提供用于试验模型的笔记本环境。
本地部署
对于本地部署,有多个框架支持 Qwen3:
- Ollama 和 LMStudio: 用于在本地运行模型的用户友好工具。
- 骆驼.cpp: 高效的 C++ 实现,以优化性能。
- MLX: 针对 Apple Silicon 优化的部署。
- KTransformers: 针对特定用例的专门部署选项。
服务器部署
对于生产环境,Qwen3 可与以下环境配合使用:
- SGLang: 针对高吞吐量的服务器部署进行了优化。
- 法律硕士: 通过连续配料等高级功能提供高效的服务。
应用程序和用例
Qwen3's 多功能性使其适用于多种应用:
- 内容创建: 生成文章, 营销文案和创意写作。
- 软件开发: 代码生成、调试和文档。
- Education: 创建教育材料并回答复杂问题。
- 研究: 协助进行文献综述和假设生成。
- 客服支持: 为智能聊天机器人提供强大的推理能力。
- 数据分析: 解释复杂数据并产生见解。
- 检索增强生成 (RAG): 使用 Qwen3 创建复杂的知识系统's 上下文窗口和推理能力。
当前的局限性和未来的发展
尽管 Qwen3 功能强大,但也存在一些局限性:
- 对于简单的任务来说,思维模式有时可能会过于冗长。
- 尽管有多种语言,但不同语言的性能仍然存在一些差异。
- 尽管 MoE 效率有所提高,但最大的模型仍需要大量资源。
展望未来,阿里巴巴's 发展路线图提出了几种令人兴奋的可能性:
- 与 Qwen3-VL(视觉语言)功能进一步集成。
- 发布专门的 Qwen3-Audio 模型 语音处理.
- 增强型 Qwen3-Math 版本针对技术和科学应用进行了优化。
结论:Qwen3's 放在 AI 横向
Qwen3 不仅仅是另一个 AI 模型掉落——这是一个 战略跨越 在开源人工智能领域。
凭借混合推理、高效的 MoE 架构和全球语言覆盖等创新,它 专为现实世界的可扩展性而构建.
对于开发者来说, 研究人员以及需要最先进功能的企业 无需供应商锁定,Qwen3 提供 开放、强大、实用 替代方案——巩固其作为 2025 年's 最重要的 AI 发展。



 奖金: 获得我们的 200 美元“AI 注册即可免费获得“精通工具包”!
奖金: 获得我们的 200 美元“AI 注册即可免费获得“精通工具包”!







