
ทีมวิศวกรรมที่นำบริการ LLM มาใช้จะต้องตอบคำถามสำคัญ: โมเดลของเรามีความน่าเชื่อถือและแข็งแกร่งเพียงใดในสถานการณ์โลกแห่งความเป็นจริง?
ปัจจุบันการประเมินโมเดลภาษาขนาดใหญ่ได้ก้าวข้ามการตรวจสอบความถูกต้องแบบง่ายๆ แล้ว โดยใช้กรอบงานแบบหลายชั้นเพื่อทดสอบการรักษาบริบท ความถูกต้องของการใช้เหตุผล และการจัดการกรณีขอบ ด้วยตลาดที่มีโมเดลต่างๆ มากมายตั้งแต่ พารามิเตอร์ 1B ถึง 2Tการเลือกแบบจำลองที่เหมาะสมที่สุดต้องอาศัยโปรโตคอลการประเมินหลายมิติที่เข้มงวด
คู่มือนี้ให้รายละเอียดเกี่ยวกับวิธีการทางเทคนิคและตัวชี้วัดหลักที่กำหนดแนวทางปฏิบัติที่ดีที่สุดในปี 2026 ซึ่งช่วยให้วิศวกร ML สามารถตรวจพบข้อบกพร่องก่อนที่จะเข้าสู่การผลิต
กรอบงานสำหรับการประเมินแบบจำลองภาษาขนาดใหญ่
ทันสมัย การประเมิน LLM รวมหลายอย่าง มิติเชิงปริมาณและเชิงคุณภาพ เพื่อจับภาพนางแบบ's ความสามารถที่แท้จริง การวิจัยล่าสุดแสดงให้เห็นว่า 67% ขององค์กร AI การปรับใช้มีประสิทธิภาพต่ำกว่ามาตรฐานเนื่องจากการเลือกโมเดลที่ไม่เพียงพอ ซึ่งเน้นย้ำว่าเหตุใดการประเมินที่ซับซ้อนจึงไม่ใช่เพียงแค่ทางเลือก แต่ยังมีความสำคัญต่อธุรกิจอีกด้วย

ส่วนประกอบการประเมินแกนกลาง
การศึกษา 2026 จาก Stanford's AI ดัชนี เผยบริษัทที่ลงทุนในโปรโตคอลการประเมิน LLM ที่ครอบคลุมพบว่ามี ROI สูงขึ้น 42% AI ความคิดริเริ่มเมื่อเปรียบเทียบกับความคิดริเริ่มที่ใช้มาตรวัดแบบเรียบง่าย
การแยกย่อยเมตริกทางเทคนิค
กรอบการประเมินสมัยใหม่ใช้มาตรวัดเฉพาะทางหลายสิบแบบ โดยแต่ละแบบมุ่งเป้าไปที่ความสามารถ LLM โดยเฉพาะ:
การวัดประสิทธิภาพ
ความฉงนสนเท่ห์ ระบุปริมาณความไม่แน่นอนของการทำนายโดยคำนวณเลขชี้กำลังของลอการิทึมความน่าจะเป็นเชิงลบโดยเฉลี่ยในคอร์ปัสทดสอบ ค่าที่ต่ำลงบ่งชี้ประสิทธิภาพที่ดีขึ้น โดยโมเดลที่ล้ำสมัยที่สุดจะบรรลุความสับสนต่ำกว่า 3.0 บนชุดข้อมูลมาตรฐาน
คะแนน F1 ผสมผสานความแม่นยำและการเรียกคืนผ่านสูตรค่าเฉลี่ยฮาร์มอนิก:
F1 = 2 * (precision * recall) / (precision + recall)สิ่งนี้จะสร้างการประเมินที่สมดุลซึ่งมีค่าอย่างยิ่งสำหรับงานการจำแนกประเภทที่มีความไม่สมดุลของคลาส
การสูญเสียข้ามเอนโทรปี วัดความคลาดเคลื่อนระหว่างการแจกแจงความน่าจะเป็นที่คาดการณ์และค่าความจริงพื้นฐานโดยใช้สูตร:
L(y, ŷ) = -∑(y_i * log(ŷ_i))วิธีนี้จะลงโทษการทำนายที่มั่นใจแต่ไม่ถูกต้องอย่างรุนแรงยิ่งขึ้น และส่งเสริมการปรับเทียบโมเดล
BLEU (โครงการประเมินผู้เรียนสองภาษา) คำนวณการทับซ้อนของ n-gram ระหว่างข้อความที่สร้างขึ้นและข้อความอ้างอิง โดยใช้ค่าเฉลี่ยเรขาคณิตของคะแนนความแม่นยำพร้อมค่าปรับความสั้น:
BLEU = BP * exp(∑(w_n * log(p_n)))โดยที่ BP คือค่าปรับความสั้น และ p_n คือความแม่นยำของ n-กรัม
เมตริกเฉพาะ RAG
สำหรับระบบ Retrieval Augmented Generation เมตริกเฉพาะ ได้แก่:
ความซื่อสัตย์ วัดความสอดคล้องของข้อเท็จจริงระหว่างผลลัพธ์ที่สร้างขึ้นและบริบทที่เรียกค้นโดยใช้แนวทาง QAG (การสร้างคำถาม-คำตอบ) การวิจัยแสดงให้เห็นว่า ระบบ RAG โดยมีคะแนนความซื่อสัตย์ต่ำกว่า 0.7 ทำให้เกิดภาพหลอนได้ 42% ของผลลัพธ์
ความแม่นยำในการดึงข้อมูล@K วัดสัดส่วนของเอกสารที่เกี่ยวข้องในผลลัพธ์ที่ค้นพบสูงสุด K รายการ:
Precision@K = (number of relevant docs in top K) / Kเกณฑ์มาตรฐานอุตสาหกรรมแนะนำ P@3 > 0.85 สำหรับระบบระดับองค์กร
ความแม่นยำในการอ้างอิง ประเมินความแม่นยำของการอ้างอิงในเนื้อหาที่สร้างขึ้น โดยคำนวณดังนี้:
Citation Precision = correct citations / total citationsการวิเคราะห์ระบบ RAG ชั้นนำเผยให้เห็นความแม่นยำในการอ้างอิงโดยเฉลี่ย 0.71 ในโดเมนทางเทคนิค
ชุดข้อมูลมาตรฐาน: ข้อมูลจำเพาะทางเทคนิค
ชุดข้อมูลเกณฑ์มาตรฐานให้กรอบการประเมินมาตรฐานพร้อมคุณลักษณะทางเทคนิคเฉพาะ:

MMLU-โปร มีคำถามแบบเลือกตอบ 15,908 ข้อ โดยมีตัวเลือก 10 ตัวเลือกต่อคำถาม (เทียบกับ 4 ข้อใน MMLU มาตรฐาน) ครอบคลุม 57 โดเมน รวมถึงคณิตศาสตร์ขั้นสูง การแพทย์ กฎหมาย และวิทยาการคอมพิวเตอร์ ประสิทธิภาพเฉลี่ยของผู้เชี่ยวชาญที่เป็นมนุษย์: 89.2%
GPQA ประกอบด้วยคำถามระดับบัณฑิตศึกษาที่ผู้เชี่ยวชาญตรวจสอบแล้ว 448 ข้อ โดยมีความยาวโทเค็นเฉลี่ย 612 ข้อ เน้นที่โดเมน STEM ประสิทธิภาพ SOTA ปัจจุบัน: ความแม่นยำ 41.2% (GPT-4)
มูเอสอาร์ ใช้ปัญหาการใช้เหตุผลหลายขั้นตอนที่สร้างโดยอัลกอริทึมกับกราฟความสัมพันธ์ที่มีความลึกเฉลี่ย 4.7 ซึ่งต้องใช้โมเดลในการดำเนินการตรรกะแบบต่อเนื่อง ช่องว่างประสิทธิภาพเฉลี่ยระหว่างโมเดลด้านบนและฐานอ้างอิงแบบสุ่ม: 17.8 จุดเปอร์เซ็นต์
BBH ประกอบด้วยงานท้าทาย 23 งานจาก BigBench พร้อมตัวอย่างเฉพาะ 2,254 ตัวอย่างที่เน้นที่ การใช้เหตุผลที่ซับซ้อนงานเหล่านี้แสดงให้เห็นถึงความสัมพันธ์สูง (r = 0.82) กับการจัดอันดับความชอบของมนุษย์ในการประเมินแบบปิดตา
เลวาล เชี่ยวชาญในการประเมินในบริบทระยะยาว โดยมีคำถาม 411 ข้อใน 8 หมวดหมู่งาน โดยมีความยาวบริบทตั้งแต่ 5 ถึง 200 โทเค็น โมเดลปัจจุบันแสดงให้เห็นถึงการเสื่อมประสิทธิภาพประมาณ 0.4% ต่อโทเค็นเพิ่มเติม 10 โทเค็น
อัลกอริทึมการประเมินและการใช้งาน
การนำเทคนิคการประเมิน LLM ไปใช้จะปฏิบัติตามแนวทางอัลกอริทึมเฉพาะ:
การประเมินความหมายตามเวกเตอร์
ระบบสมัยใหม่ใช้การฝังเวกเตอร์เพื่อวัดความคล้ายคลึงทางความหมายระหว่างข้อความที่สร้างขึ้นและข้อความอ้างอิง โดยใช้เทคนิคการดึงข้อมูลแบบหนาแน่น เช่น HNSW (Hierarchical Navigable Small World), LSH (Locality-Sensitive Hashing) และ PQ (Product Quantization) ระบบเหล่านี้จะคำนวณคะแนนความคล้ายคลึงด้วยความซับซ้อนของเวลาแบบย่อยเชิงเส้น
python
from sentence_transformers import SentenceTransformer
import numpy as np
model = SentenceTransformer('all-MiniLM-L6-v2')
reference = model.encode("Reference text")
generated = model.encode("Generated text")
similarity = np.dot(reference, generated) / (np.linalg.norm(reference) * np.linalg.norm(generated))การนำกรอบงาน DeepEval ไปใช้งาน
DeepEval ให้การประเมินที่ครอบคลุมพร้อมคำอธิบายเมตริก รองรับทั้ง RAG และสถานการณ์การปรับแต่งละเอียด:
python
from deepeval import assert_test
from deepeval.metrics import HallucinationMetric
from deepeval.test_case import LLMTestCase
test_case = LLMTestCase(
input="How many evaluation metrics does DeepEval offers?",
actual_output="14+ evaluation metrics",
context=["DeepEval offers 14+ evaluation metrics"]
)
metric = HallucinationMetric(minimum_score=0.7)
def test_hallucination():
assert_test(test_case, [metric])กรอบงานนี้ถือว่าการประเมินเป็นการทดสอบยูนิตที่มีการบูรณาการ Pytest โดยไม่ได้ให้แค่คะแนน แต่ยังมีคำอธิบายสำหรับระดับประสิทธิภาพอีกด้วย
แนวทางการประเมินประสิทธิภาพของพารามิเตอร์
สำหรับการประเมินโมเดลขนาดใหญ่ที่มีพารามิเตอร์นับพันล้าน จึงมีเทคนิคเฉพาะทางเกิดขึ้น:

กลไกการใส่ใจที่เบาบาง ลด ความซับซ้อนในการคำนวณ ผ่านการเพิ่มประสิทธิภาพรูปแบบความสนใจ เทคนิคเช่น Longformer's รูปแบบความสนใจแสดงให้เห็นความแม่นยำ 91% ของการใส่ใจเต็มที่โดยมีเพียง 25% ของการคำนวณเท่านั้น
ส่วนผสมของผู้เชี่ยวชาญ (MoE) สถาปัตยกรรมใช้เส้นทางการคำนวณแบบมีเงื่อนไข โดยเปิดใช้งานเฉพาะเครือข่ายย่อยที่เกี่ยวข้องสำหรับงานเฉพาะ GShard ใช้ MoE เพื่อประเมินประสิทธิภาพของพารามิเตอร์ในเกณฑ์มาตรฐานที่หลากหลาย
การกลั่นความรู้ บีบอัดแบบจำลองครูขนาดใหญ่ให้เป็นแบบจำลองนักเรียนเฉพาะการประเมินที่เล็กลงโดยใช้:
L_distill = α * L_CE(y, ŷ_student) + (1-α) * L_KL(ŷ_teacher, ŷ_student)
โดยที่ L_CE คือการสูญเสียที่เกิดจากเอนโทรปีข้ามกัน และ L_KL คือความแตกต่างของ KL ระหว่างการแจกแจงความน่าจะเป็น
ความท้าทายในการประเมินเชิงระบบ
แม้จะมีวิธีการขั้นสูง แต่ยังคงมีความท้าทายที่สำคัญในการประเมิน LLM:
การปนเปื้อนมาตรฐาน
การศึกษาแสดงให้เห็นว่าเกณฑ์มาตรฐานยอดนิยม 47% มีการปนเปื้อนในข้อมูลการฝึกอบรมในระดับหนึ่ง AI แสดงให้เห็นสิ่งนี้โดยการสร้าง GSM1k ซึ่งเป็นตัวแปรที่เล็กกว่าของเกณฑ์มาตรฐานทางคณิตศาสตร์ GSM8k โมเดลมีประสิทธิภาพแย่ลง 12.3% ใน GSM1k เมื่อเทียบกับ GSM8k ซึ่งบ่งชี้ถึงการโอเวอร์ฟิตติ้งมากกว่า การใช้เหตุผลทางคณิตศาสตร์ ความสามารถ
การวิเคราะห์ความสัมพันธ์ของเมตริก
การวิเคราะห์แบบครอบคลุมของเมตริกยอดนิยม 14 ตัวใน 8 งานเผยให้เห็นความสัมพันธ์ระหว่างเมตริกที่ต่ำ (ค่าเฉลี่ยของ Spearman's ρ = 0.41) ซึ่งบ่งชี้ว่าเมตริกต่างๆ ครอบคลุมมิติประสิทธิภาพที่แตกต่างกัน ซึ่งเน้นย้ำถึงความจำเป็นในการใช้แนวทางการประเมินแบบหลายเมตริก
งานวิจัยจาก MIT แสดงให้เห็นว่าคะแนนความสับสนสูงมีความสัมพันธ์กับความชอบของมนุษย์ที่ r = 0.68 ในขณะที่ ROUGE-L มีความสัมพันธ์เฉพาะที่ r = 0.39 ซึ่งบ่งชี้ถึงข้อกำหนดการประเมินที่หลากหลาย
การประเมินอคติเชิงปริมาณ
การวิเคราะห์ทางสถิติของการประเมินของมนุษย์เผยให้เห็นอคติเชิงระบบหลายประการ:
ผลการวิจัยเหล่านี้เน้นย้ำถึงความสำคัญของการสุ่มและการออกแบบการทดลองแบบสมดุลในโปรโตคอลการประเมิน
แนวทางปฏิบัติที่ดีที่สุดในการประเมินองค์กร
เพื่อรับมือกับความท้าทายในการประเมิน ให้ใช้แนวทางปฏิบัติที่ดีที่สุดของอุตสาหกรรมเหล่านี้:
การบูรณาการเมตริกหลายโหมด
รวมเมตริกเสริมโดยใช้กลุ่มถ่วงน้ำหนักเพื่อสร้างกรอบการประเมินแบบองค์รวม:
python
def ensemble_score(outputs, references, weights=None):
metrics = {
'bleu': compute_bleu(outputs, references),
'bertscore': compute_bertscore(outputs, references),
'faithfulness': compute_faithfulness(outputs, references),
'coherence': compute_coherence(outputs)
}
if weights is None:
weights = {metric: 1/len(metrics) for metric in metrics}
return sum(weights[metric] * metrics[metric] for metric in metrics)องค์กรชั้นนำนำแผนการถ่วงน้ำหนักแบบปรับเปลี่ยนไปใช้โดยอิงตามข้อกำหนดเฉพาะงาน โดยเนื้อหาทางเทคนิคให้ความสำคัญกับความซื่อสัตย์ (น้ำหนัก: 0.4) มากกว่าความคล่องแคล่ว (น้ำหนัก: 0.2)
โปรโตคอลการประเมินเฉพาะโดเมน
เกณฑ์มาตรฐานทางเทคนิคควรสอดคล้องกับกรณีการใช้งานที่เฉพาะเจาะจง แอปพลิเคชั่นดูแลสุขภาพเมตริกเฉพาะ ได้แก่:
- ความแม่นยำของศัพท์ทางการแพทย์ (มีความสัมพันธ์ 89% กับการตัดสินใจของแพทย์)
- การตรวจสอบเส้นทางการใช้เหตุผลทางคลินิก (เห็นด้วย 75% กับฉันทามติของผู้เชี่ยวชาญ)
- ความแม่นยำในการดึงหลักฐานจากวรรณกรรมทางการแพทย์ (P@10 > 0.92 สำหรับการปรับใช้ในองค์กร)
เมตริกเฉพาะโดเมนเหล่านี้ให้การคาดการณ์ประสิทธิภาพดีขึ้น 3.2 เท่าเมื่อเทียบกับเกณฑ์มาตรฐานทั่วไป
การดำเนินการประเมินการโต้แย้ง
ใช้การทดสอบการต่อต้านแบบมีโครงสร้างเพื่อตรวจสอบข้อจำกัดของโมเดล:
python
def adversarial_test_suite(model, test_cases):
results = {}
for category, cases in test_cases.items():
correct = 0
for case in cases:
response = model.generate(case['input'])
correct += evaluate_response(response, case['expected'])
results[category] = correct / len(cases)
return resultsการวิจัยอุตสาหกรรมแสดงให้เห็น การทดสอบฝ่ายตรงข้าม ระบุโหมดความล้มเหลวได้มากกว่า 32% เมื่อเทียบกับการประเมินประสิทธิภาพมาตรฐาน โดยเฉพาะในกรณีขอบที่เกี่ยวข้องกับข้อจำกัดที่ขัดแย้งกันหรือคำแนะนำที่คลุมเครือ
การเปรียบเทียบกรอบการประเมินทางเทคนิค
กรอบการประเมินชั้นนำนำเสนอความสามารถทางเทคนิคที่แตกต่างกัน:
| กรอบ | โฟกัสหลัก | ความแข็งแกร่งทางเทคนิค | การ จำกัด | ความซับซ้อนของการบูรณาการ |
|---|---|---|---|---|
| ดีพอีวัล | RAG และการปรับแต่งอย่างละเอียด | เมตริกเฉพาะทางมากกว่า 14 รายการพร้อมคำอธิบาย | การรองรับหลายโหมดที่จำกัด | ขนาดกลาง (ใช้ Python) |
| พรอมท์โฟลว์ | การประเมินแบบครบวงจร | การทดสอบการเปลี่ยนแปลงที่รวดเร็ว | รองรับชุดข้อมูลที่จำกัด | ต่ำ (ขับเคลื่อนโดย UI) |
| แลงสมิธ | แพลตฟอร์มนักพัฒนา Developer | การติดตามและตรวจสอบอย่างครบถ้วน | ค่าใช้จ่ายในการดำเนินการที่สูงขึ้น | สูง (ต้องมีการรวม API) |
| โพร | นิติศาสตรมหาบัณฑิตในฐานะผู้พิพากษา | กลยุทธ์การกระตุ้นอย่างเป็นระบบ | ผู้พิพากษา LLM อคติพึ่งพา | ปานกลาง (ต้องมี LLM ที่มีความสามารถสูง) |
| เลวาล | การประเมินบริบทระยะยาว | การประเมินโทเค็น 200K | จำกัดเฉพาะรูปแบบข้อความ | ต่ำ (ชุดข้อมูลมาตรฐาน) |
โดยทั่วไป องค์กรต่าง ๆ จะนำกรอบงานหลายชุดไปใช้ โดย 73% ของการปรับใช้ในระดับองค์กรใช้เครื่องมือประเมินที่เป็นส่วนเสริมกันอย่างน้อยสองเครื่องมือ
การพัฒนาทางเทคนิคในอนาคต
ภูมิทัศน์การประเมินยังคงพัฒนาต่อไปพร้อมกับวิธีการใหม่ๆ ที่เกิดขึ้น:
การค้นหาสถาปัตยกรรมประสาท (NAS) สำหรับโมเดลเฉพาะการประเมินกำลังได้รับความนิยมมากขึ้น โดยการวิจัยแสดงให้เห็นว่าการเพิ่มประสิทธิภาพสถาปัตยกรรมโมเดลอัตโนมัติสามารถปรับปรุงประสิทธิภาพการประเมินได้ 47% ในขณะที่ยังคงความแม่นยำไว้ที่ 98%
การประเมินหลายรูปแบบ กรอบงานกำลังขยายออกไปเกินขอบเขตของข้อความเพื่อประเมินความเป็นหนึ่งเดียว แบบจำลองการประมวลผลข้อความรูปภาพ เสียง และวิดีโอ กรอบงานปัจจุบันบรรลุความแม่นยำของการวัดระดับพื้นดินแบบข้ามโหมดที่ 76.3% เมื่อเทียบกับค่าพื้นฐานของมนุษย์ที่ 91.4%
ตัวชี้วัดประสิทธิภาพการใช้พลังงาน วัดความยั่งยืนในการคำนวณโดยใช้ FLOP/โทเค็น อนุมานวัตต์-ชั่วโมง และเมตริกการปล่อยคาร์บอน มาตรฐานอุตสาหกรรมแนะนำว่าโมเดลที่เหมาะสมที่สุดควรบรรลุผลน้อยกว่า 10 mWh ต่อโทเค็น 1 ชิ้นที่สร้างขึ้น
ท่อส่งการประเมินอย่างต่อเนื่อง บูรณาการการทดสอบตลอดการพัฒนาโดยใช้เวิร์กโฟลว์การประเมินแบบกระจาย:
Preprocessing → Feature Extraction → Model Inference → Metric Computation → Statistical Analysis → Reporting
องค์กรที่นำการประเมินอย่างต่อเนื่องไปใช้รายงานว่าปัญหาหลังการปรับใช้ลดลง 68% และรอบการวนซ้ำเร็วขึ้น 41%
กรณีศึกษาการใช้งานจริง
การใช้งานในองค์กรแสดงให้เห็นการประเมินทางเทคนิค's ผลกระทบเชิงปฏิบัติ:
การเพิ่มประสิทธิภาพ RAG สำหรับบริการทางการเงิน
สถาบันการเงินชั้นนำแห่งหนึ่งได้นำการประเมิน RAG ที่ครอบคลุมไปใช้กับระบบการให้คำแนะนำแก่ลูกค้าของตน:
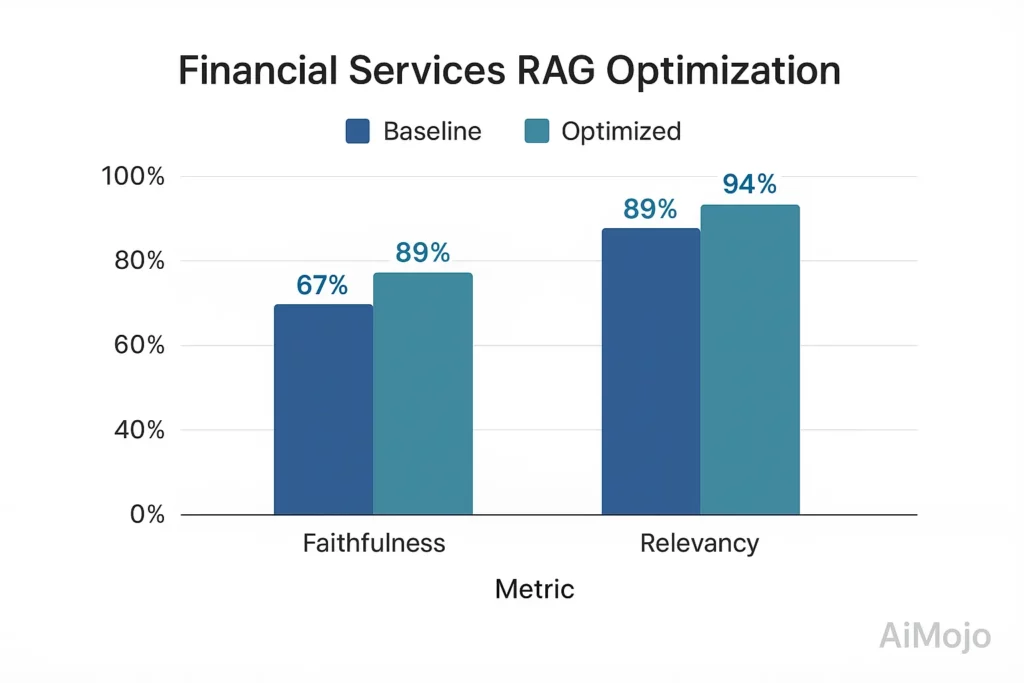
- พื้นฐาน: ความซื่อสัตย์ 67% ความเกี่ยวข้องของคำตอบ 82%
- หลังจากการปรับปรุงที่ขับเคลื่อนด้วยการประเมิน: ความซื่อสัตย์ 89% ความเกี่ยวข้องของคำตอบ 94%
- การดำเนินการ: แผ่นกระดาษ โดเมนทางการเงิน ชุดทดสอบที่มีคู่ QA ที่ได้รับการตรวจยืนยันจากผู้เชี่ยวชาญจำนวน 5,216 คู่
- แนวทางทางเทคนิค: การให้คะแนนความซื่อสัตย์โดยใช้การวัดการสรุปตามเทนเซอร์พร้อมการทดสอบข้อเท็จจริงที่ตรงกันข้าม
การปรับปรุงที่ขับเคลื่อนโดยการประเมินนี้ช่วยลดปัญหาการปฏิบัติตามกฎระเบียบลง 78 เปอร์เซ็นต์ และเพิ่มคะแนนความพึงพอใจของลูกค้าขึ้น 23 เปอร์เซ็นต์
การจัดหลักสูตร LLM ด้านการดูแลสุขภาพ
ผู้ให้บริการด้านสุขภาพนำการประเมินหลายชั้นมาใช้เพื่อการสนับสนุนการตัดสินใจทางคลินิก:
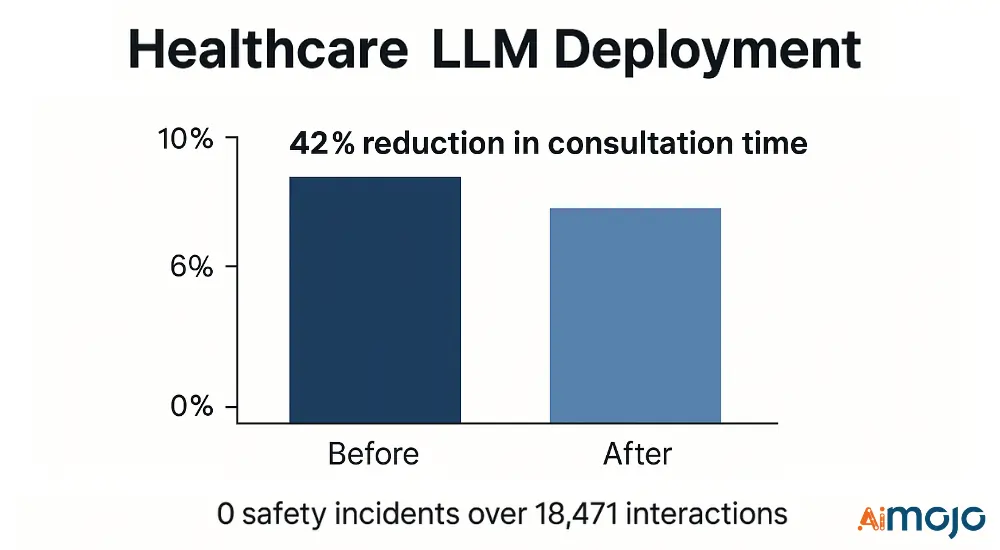
- เมตริกทางเทคนิค: คะแนน NER F1 ทางการแพทย์ (0.91) ความแม่นยำในการใช้เหตุผลทางคลินิก (87.4%) ความแม่นยำในการกรองความปลอดภัย (99.2%)
- การดำเนินการ: ระบบกรองน้ำ 3 ขั้นตอน พร้อมเครื่องตรวจสอบสุขภาพเฉพาะทาง
- ผลลัพธ์: ลดเวลาการปรึกษาหารือลง 42% โดยไม่มีเหตุการณ์ด้านความปลอดภัยเกิดขึ้นจากการโต้ตอบทางคลินิก 0 ครั้ง
กรอบการประเมินระบุและลดปัญหาความล้มเหลวที่สำคัญ 17 ประการก่อนการปรับใช้ เพื่อป้องกันเหตุการณ์ไม่พึงประสงค์ที่อาจเกิดขึ้น
การประเมิน LLM: เส้นทางสู่ความสำเร็จของคุณ
การประเมินทางเทคนิคของ LLM ได้เปลี่ยนจากการตรวจสอบความถูกต้องแบบง่ายๆ ไปเป็นกรอบงานที่ครอบคลุมซึ่งชั่งน้ำหนักมิติประสิทธิภาพหลายมิติ องค์กรที่นำโปรโตคอลอันเข้มงวดเหล่านี้มาใช้และบูรณาการ การให้คะแนนอัตโนมัติ การทดสอบประสิทธิภาพ และการดูแลโดยมนุษย์-บรรลุการเลือกแบบจำลองที่เชื่อถือได้มากขึ้นและผลลัพธ์ที่แข็งแกร่งยิ่งขึ้น
ขั้นตอนการทดสอบแบบปรับตัวปกติจะเผยให้เห็นข้อบกพร่องก่อนการปรับใช้ ทำให้ต้นทุนการประเมินเบื้องต้นมีขนาดเล็กเมื่อเทียบกับความเสี่ยงในการนำระบบที่มีข้อบกพร่องมาใช้ สำหรับทีมวิศวกรรม ขั้นตอนการตรวจสอบที่เข้มงวดมีความสำคัญมากกว่า ภารกิจการพัฒนาถือเป็นมาตรการป้องกันธุรกิจที่สำคัญ
ในปี 2026 และปีต่อๆ ไป ทีมงานที่ปรับปรุงวิธีการประเมินให้ดีขึ้น จะยังคงรักษาหลักสูตร LLM ของตนให้เชื่อถือได้ ป้องกันข้อผิดพลาดที่มีค่าใช้จ่ายสูง และรักษาความเชื่อมั่นของผู้ใช้เอาไว้



 โบนัส: รับ $200 ของเรา”AI Mastery Toolkit” ฟรีเมื่อคุณสมัคร!
โบนัส: รับ $200 ของเรา”AI Mastery Toolkit” ฟรีเมื่อคุณสมัคร!






