
As equipes de engenharia que implantam serviços de LLM devem responder a uma pergunta crítica: quão confiável e robusto é nosso modelo em cenários do mundo real?
A Avaliação de Modelos de Linguagem Ampla agora vai além de simples verificações de precisão, empregando estruturas em camadas para testar a retenção de contexto, a validade do raciocínio e o tratamento de casos extremos. Com o mercado inundado por modelos que variam de Parâmetros 1B a 2T, selecionar o modelo ideal requer protocolos de avaliação rigorosos e multidimensionais.
Este guia detalha os métodos técnicos e as principais métricas que moldam as melhores práticas em 2026, ajudando engenheiros de ML a detectar falhas antes que elas cheguem à produção.
Estruturas para Avaliação de Grandes Modelos de Linguagem
EQUIPAMENTOS Avaliação LLM incorpora múltiplos dimensões quantitativas e qualitativas para capturar um modelo's verdadeiras capacidades. Pesquisas recentes mostram que 67% das empresas AI as implantações apresentam desempenho inferior devido à seleção inadequada de modelos, destacando por que a avaliação sofisticada não é meramente opcional, mas crítica para os negócios.

Componentes principais de avaliação
Um estudo de 2026 da Stanford's AI Índice revela que empresas que investem em protocolos abrangentes de avaliação de LLM veem um ROI 42% maior em seus AI iniciativas em comparação àquelas que usam métricas simplificadas.
Análise de Métricas Técnicas
As estruturas de avaliação modernas empregam dezenas de métricas especializadas, cada uma visando capacidades específicas de LLM:
Métricas de Desempenho
Perplexidade quantifica a incerteza de previsão calculando o exponencial da média do logaritmo negativo da verossimilhança em um corpus de teste. Valores mais baixos indicam melhor desempenho, com modelos de última geração alcançando perplexidade abaixo de 3.0 em conjuntos de dados padronizados.
Pontuação F1 combina precisão e recall por meio da fórmula da média harmônica:
F1 = 2 * (precision * recall) / (precision + recall)Isso cria uma avaliação equilibrada, particularmente valiosa para tarefas de classificação com desequilíbrio de classe.
Perda de Entropia Cruzada mede a discrepância entre as distribuições de probabilidade previstas e a verdade básica usando a fórmula:
L(y, ŷ) = -∑(y_i * log(ŷ_i))Isso penaliza previsões confiantes, mas incorretas, mais severamente, incentivando a calibração do modelo.
BLEU (Estudante de Avaliação Bilíngue) calcula a sobreposição de n-gramas entre textos gerados e de referência, empregando uma média geométrica de pontuações de precisão com uma penalidade de brevidade:
BLEU = BP * exp(∑(w_n * log(p_n)))Onde BP é a penalidade de brevidade e p_n é a precisão de n-gramas.
Métricas específicas do RAG
Para sistemas de geração aumentada de recuperação, as métricas especializadas incluem:
Fidelidade quantifica a consistência factual entre a saída gerada e o contexto recuperado usando abordagens QAG (Geração de Perguntas e Respostas). Pesquisas mostram Sistemas RAG com pontuações de fidelidade abaixo de 0.7 produzem alucinações em 42% dos resultados.
Precisão de recuperação@K mede a proporção de documentos relevantes entre os K principais resultados recuperados:
Precision@K = (number of relevant docs in top K) / KOs benchmarks do setor sugerem P@3 > 0.85 para sistemas de nível empresarial.
Precisão de citação avalia a precisão das citações no conteúdo gerado, calculada como:
Citation Precision = correct citations / total citationsA análise dos principais sistemas RAG revela uma precisão de citação média de 0.71 em todos os domínios técnicos.
Conjuntos de dados de referência: especificações técnicas
Os conjuntos de dados de referência fornecem estruturas de avaliação padronizadas com características técnicas específicas:

MMLU-Pro Apresenta 15,908 questões de múltipla escolha com 10 opções por questão (em comparação com 4 no MMLU padrão), abrangendo 57 áreas, incluindo matemática avançada, medicina, direito e ciência da computação. Desempenho médio de especialistas humanos: 89.2%.
GPQA Contém 448 questões de nível de pós-graduação, verificadas por especialistas, com comprimento médio de token de 612, com foco em áreas STEM. Desempenho atual no SOTA: precisão de 41.2% (GPT-4).
MuSR Implementa problemas de raciocínio multietapas gerados algoritmicamente com grafos de dependência de profundidade média de 4.7, exigindo que os modelos realizem operações lógicas encadeadas. Diferença média de desempenho entre os modelos principais e a linha de base aleatória: 17.8 pontos percentuais.
BBH compreende 23 tarefas desafiadoras do BigBench com 2,254 exemplos individuais focados em raciocínio complexo. Essas tarefas mostram alta correlação (r=0.82) com classificações de preferência humana em avaliações cegas.
LEval é especializada em avaliação de contexto longo, com 411 perguntas em 8 categorias de tarefas, com extensões de contexto que variam de 5 mil a 200 mil tokens. Os modelos atuais mostram uma degradação de desempenho de aproximadamente 0.4% a cada 10 mil tokens adicionais.
Algoritmos de Avaliação e Implementação
A implementação técnica da avaliação de LLM segue abordagens algorítmicas específicas:
Avaliação Semântica Baseada em Vetores
Sistemas modernos empregam embeddings vetoriais para medir a similaridade semântica entre textos gerados e de referência. Utilizando técnicas de recuperação densa como HNSW (Hierarchical Navigable Small World), LSH (Locality-Sensitive Hashing) e PQ (Product Quantization), esses sistemas calculam pontuações de similaridade com complexidade de tempo sublinear.
python
from sentence_transformers import SentenceTransformer
import numpy as np
model = SentenceTransformer('all-MiniLM-L6-v2')
reference = model.encode("Reference text")
generated = model.encode("Generated text")
similarity = np.dot(reference, generated) / (np.linalg.norm(reference) * np.linalg.norm(generated))Implementação do Framework DeepEval
O DeepEval fornece uma avaliação abrangente com explicações métricas, suportando cenários RAG e de ajuste fino:
python
from deepeval import assert_test
from deepeval.metrics import HallucinationMetric
from deepeval.test_case import LLMTestCase
test_case = LLMTestCase(
input="How many evaluation metrics does DeepEval offers?",
actual_output="14+ evaluation metrics",
context=["DeepEval offers 14+ evaluation metrics"]
)
metric = HallucinationMetric(minimum_score=0.7)
def test_hallucination():
assert_test(test_case, [metric])Esta estrutura trata as avaliações como testes unitários com integração Pytest, fornecendo não apenas pontuações, mas explicações para os níveis de desempenho.
Abordagens de avaliação com eficiência de parâmetros
Para avaliação em larga escala de modelos com bilhões de parâmetros, surgiram técnicas especializadas:

Mecanismos de Atenção Esparsos reduzir complexidade computacional por meio da otimização do padrão de atenção. Técnicas como Longformer's os padrões de atenção mostram 91% de precisão de atenção total com apenas 25% do cálculo.
Mistura de Especialistas (MoE) As arquiteturas implementam caminhos computacionais condicionais, ativando apenas sub-redes relevantes para tarefas específicas. O GShard implementa a atenção MoE para avaliação com eficiência de parâmetros em diversos benchmarks.
Destilação de Conhecimento comprime modelos maiores de professores em modelos menores de alunos específicos para avaliação usando:
L_distill = α * L_CE(y, ŷ_student) + (1-α) * L_KL(ŷ_teacher, ŷ_student)
Onde L_CE é perda de entropia cruzada e L_KL é divergência KL entre distribuições de probabilidade.
Desafios da Avaliação Sistemática
Apesar das metodologias avançadas, ainda existem desafios significativos na avaliação do LLM:
Contaminação de referência
Estudos mostram que 47% dos benchmarks populares apresentam algum grau de contaminação nos dados de treinamento. Escala AI demonstrou isso ao criar o GSM1k, uma variante menor do benchmark matemático GSM8k. Os modelos tiveram um desempenho 12.3% pior no GSM1k do que no GSM8k, indicando overfitting em vez de raciocínio matemático capacidade.
Análise de correlação métrica
A análise abrangente de 14 métricas populares em 8 tarefas revela baixa correlação intermétrica (média de Spearman's ρ = 0.41), indicando que as métricas capturam diferentes dimensões de desempenho. Isso reforça a necessidade de abordagens de avaliação multimétricas.
Pesquisas do MIT mostram que altas pontuações de perplexidade se correlacionam com preferências humanas em r=0.68, enquanto ROUGE-L se correlaciona apenas em r=0.39, indicando requisitos de avaliação diversos.
Quantificação de Vieses de Avaliação
A análise estatística das avaliações humanas revela múltiplos vieses sistemáticos:
Essas descobertas destacam a importância da randomização e do delineamento experimental equilibrado em protocolos de avaliação.
Melhores práticas de avaliação empresarial
Para enfrentar os desafios da avaliação, implemente estas práticas recomendadas do setor:
Integração de métricas multimodais
Combine métricas complementares usando conjuntos ponderados para criar estruturas de avaliação holísticas:
python
def ensemble_score(outputs, references, weights=None):
metrics = {
'bleu': compute_bleu(outputs, references),
'bertscore': compute_bertscore(outputs, references),
'faithfulness': compute_faithfulness(outputs, references),
'coherence': compute_coherence(outputs)
}
if weights is None:
weights = {metric: 1/len(metrics) for metric in metrics}
return sum(weights[metric] * metrics[metric] for metric in metrics)As principais organizações implementam esquemas de ponderação adaptáveis com base em requisitos específicos da tarefa, com conteúdo técnico priorizando fidelidade (peso: 0.4) em vez de fluência (peso: 0.2).
Protocolos de Avaliação Específicos de Domínio
Os benchmarks técnicos devem estar alinhados com casos de uso específicos. Para aplicações de saúde, métricas especializadas incluem:
- Precisão da terminologia médica (correlação de 89% com o julgamento clínico)
- Validação do caminho do raciocínio clínico (75% de concordância com o consenso de especialistas)
- Precisão de recuperação de evidências da literatura médica (P@10 > 0.92 para implantação empresarial)
Essas métricas específicas de domínio fornecem uma previsão de desempenho 3.2× melhor do que benchmarks genéricos.
Implementação de Avaliação Adversarial
Implementar testes adversariais estruturados para investigar as limitações do modelo:
python
def adversarial_test_suite(model, test_cases):
results = {}
for category, cases in test_cases.items():
correct = 0
for case in cases:
response = model.generate(case['input'])
correct += evaluate_response(response, case['expected'])
results[category] = correct / len(cases)
return resultsPesquisas da indústria mostram teste adversário identifica 32% mais modos de falha do que o benchmarking padrão, particularmente em casos extremos envolvendo restrições conflitantes ou instruções ambíguas.
Comparação da Estrutura de Avaliação Técnica
As principais estruturas de avaliação oferecem diferentes capacidades técnicas:
| Quadro | Foco primário | Força Técnica | Limitação | Complexidade de Integração |
|---|---|---|---|---|
| Avaliação Profunda | RAG e ajuste fino | Mais de 14 métricas especializadas com explicações | Suporte multimodal limitado | Médio (baseado em Python) |
| PromptFlow | Avaliação de ponta a ponta | Teste de variação rápida | Suporte limitado a conjuntos de dados | Baixo (orientado pela IU) |
| Lang Smith | Plataforma de desenvolvedor | Rastreamento e monitoramento completos | Maior sobrecarga de implementação | Alto (requer integração de API) |
| Prometeu | LLM-como-juiz | Estratégias de estímulo sistemático | Julgar a dependência de viés do LLM | Médio (requer um poderoso LLM) |
| LEval | Avaliação de longo contexto | Avaliação de tokens de 200 mil | Limitado à modalidade de texto | Baixo (conjunto de dados de referência) |
As organizações geralmente implementam várias estruturas, com 73% das implantações corporativas usando pelo menos duas ferramentas de avaliação complementares.
Desenvolvimentos técnicos futuros
O cenário de avaliação continua evoluindo com metodologias emergentes:
Pesquisa de arquitetura neural (NAS) para modelos específicos de avaliação está ganhando força, com pesquisas mostrando que a otimização automatizada da arquitetura de modelos pode melhorar a eficiência da avaliação em 47%, mantendo 98% de precisão.
Avaliação Multimodal as estruturas estão se expandindo além do texto para avaliar unificado modelos processando texto, imagens, áudio e vídeo. As estruturas atuais alcançam uma precisão de aterramento intermodal de 76.3%, em comparação com as linhas de base humanas de 91.4%.
Métricas de eficiência energética Quantificar a sustentabilidade computacional usando FLOPs/token, inferindo watts-hora e métricas de emissão de carbono. Referências do setor sugerem que os modelos ideais devem atingir <10 mWh por 1 tokens gerados.
Pipelines de Avaliação Contínua integrar testes durante o desenvolvimento usando fluxos de trabalho de avaliação distribuídos:
Preprocessing → Feature Extraction → Model Inference → Metric Computation → Statistical Analysis → Reporting
Organizações que implementam avaliação contínua relatam 68% menos problemas pós-implantação e ciclos de iteração 41% mais rápidos.
Estudos de caso de implementação no mundo real
Implementações empresariais demonstram avaliação técnica's impacto prático:
Otimização de RAG de Serviços Financeiros
Uma instituição financeira líder implementou uma avaliação RAG abrangente para seu sistema de consultoria voltado ao cliente:
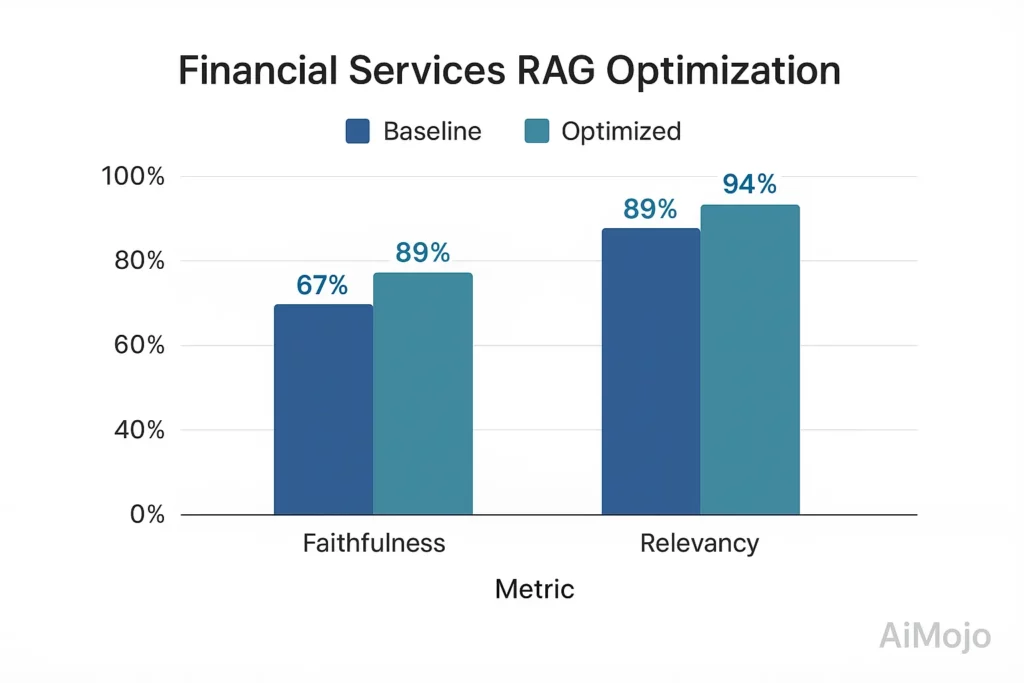
- Linha de base: 67% de fidelidade, 82% de relevância da resposta
- Após otimização orientada por avaliação: 89% de fidelidade, 94% de relevância da resposta
- Implementação: Molduras por Medida domínio financeiro conjunto de testes com 5,216 pares de QA verificados por especialistas
- Abordagem técnica: Pontuação de fidelidade usando medição de implicação baseada em tensor com teste contrafactual
Essa melhoria orientada pela avaliação reduziu os problemas de conformidade regulatória em 78% e aumentou as pontuações de satisfação do cliente em 23 pontos percentuais.
Implantação de LLM em Saúde
Um provedor de saúde implementou uma avaliação em várias camadas para suporte à decisão clínica:
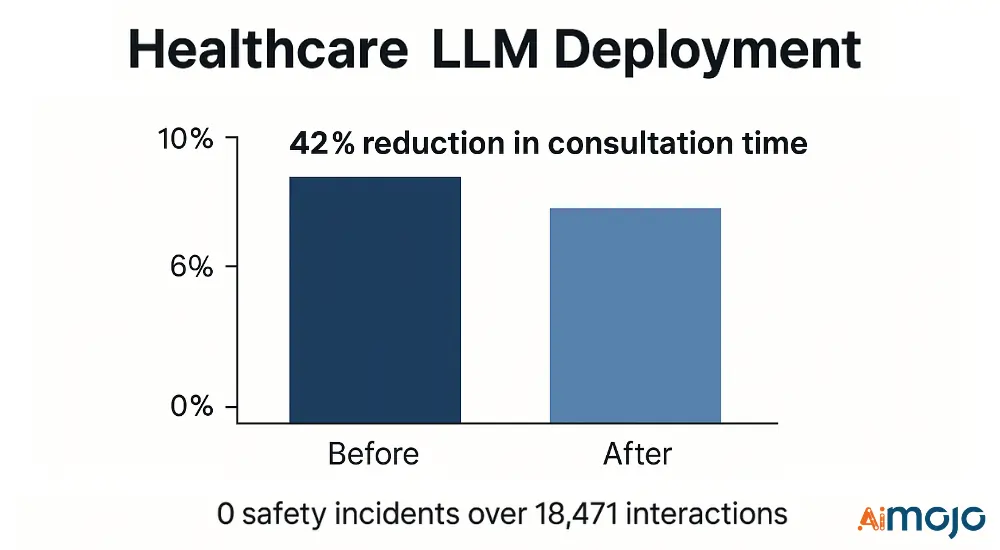
- Métricas técnicas: Pontuação médica NER F1 (0.91), precisão do raciocínio clínico (87.4%), precisão da filtragem de segurança (99.2%)
- Implementação: Pipeline de filtragem de 3 estágios com validadores especializados em saúde
- Resultados: Redução de 42% no tempo de consulta com 0 incidentes de segurança em 18,471 interações clínicas
A estrutura de avaliação identificou e mitigou 17 modos de falha críticos antes da implantação, prevenindo potenciais eventos adversos.
Avaliação de LLM: seu roteiro para o sucesso
A avaliação técnica de LLMs evoluiu de simples verificações de precisão para estruturas abrangentes que ponderam múltiplas dimensões de desempenho. As organizações que adotam esses protocolos rigorosos e os integram pontuação automatizada, testes de benchmark e supervisão humana-obter uma seleção de modelos mais confiável e resultados mais sólidos.
Pipelines de testes adaptativos e regulares revelam falhas antes da implantação, tornando o custo da avaliação inicial pequeno em comparação com os riscos de implementar um sistema defeituoso. Para equipes de engenharia, etapas robustas de validação são mais do que suficientes. tarefas de desenvolvimento; são salvaguardas empresariais essenciais.
Em 2026 e além, as equipes que refinarem seus métodos de avaliação manterão seus LLMs confiáveis, evitarão erros dispendiosos e manterão a confiança do usuário.



 BONUS: Receba nossos $ 200 “AI “Kit de ferramentas de domínio” GRÁTIS ao se inscrever!
BONUS: Receba nossos $ 200 “AI “Kit de ferramentas de domínio” GRÁTIS ao se inscrever!






