Fogos de artifício AI Principais insights
O que é Fireworks AI?
IA de fogos de artifício é uma plataforma de inferência de alto desempenho criada especificamente para desenvolvedores e empresas que precisam executar, otimizar e escalar softwares de código aberto. AI modelos em velocidade de nível de produção. Fundada por ex-membros da equipe PyTorch na Meta, a plataforma fornece um OpenAI API compatível que concede acesso a mais de 100 modelos populares de linguagem, visão computacional e geração de imagens.
Fogos de artifício AI Elimina a carga operacional da gestão da infraestrutura de GPUs, oferecendo opções de implantação sem servidor e sob demanda. Empresas utilizam o Fireworks. AI para alimentar chatbots, assistentes de codificação, mecanismos de busca e agentes AI fluxos de trabalho. Seu mecanismo de inferência personalizado oferece até 4 vezes mais taxa de transferência e 50% menos latência do que as pilhas de serviço de código aberto padrão, tornando-o um dos mais rápidos. AI Provedores de API disponíveis atualmente para geração de dados generativos. AI cargas de trabalho de produção.
O mecanismo de inferência proprietário da Fireworks AI foi desenvolvido desde o início para oferecer velocidade. Ele consistentemente proporciona latência do primeiro token inferior a 100 milissegundos em uma ampla variedade de tamanhos de modelo. Para qualquer aplicação que exija capacidade de resposta em tempo real, como chatbots voltados para o cliente ou assistentes de codificação agéticosEssa vantagem de desempenho é mensurável e significativa. Empresas como Sourcegraph e Notion divulgaram publicamente ganhos de produtividade após a migração para a plataforma.
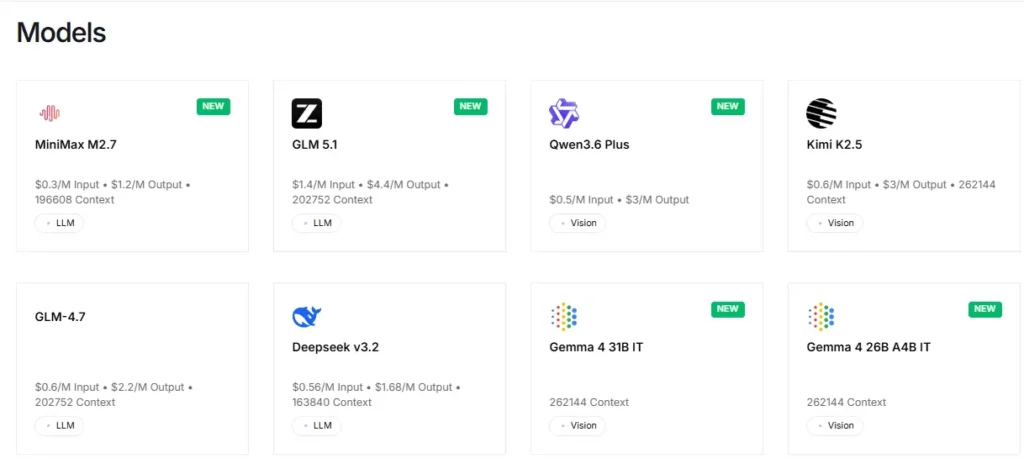
A plataforma oferece acesso instantâneo a mais de 100 modelos de código aberto, incluindo Llama, Qwen, DeepSeek, Kimi K2.5, GLM 5, Mixtral e FLUX. geradores de imagemOs desenvolvedores podem testar e alternar entre modelos por meio de um único endpoint de API, sem alterações de configuração. Isso torna a prototipagem rápida e os testes A/B entre famílias de modelos extremamente eficientes.
Fogos de artifício AI Suporta toda a gama de métodos de ajuste fino, incluindo LoRA, ajuste fino supervisionado de parâmetros completos, DPO (alinhamento de preferências) e ajuste fino por reforço. Fundamentalmente, os modelos ajustados são oferecidos pelo mesmo preço dos modelos base, eliminando a penalidade de custo imposta por muitos concorrentes. O ajuste fino de modelos de linguagem de visão também é suportado, permitindo que as equipes personalizem modelos multimodais com seus próprios conjuntos de dados de imagem e texto.
Para cargas de trabalho que exigem recursos dedicados, o Fireworks é a solução ideal. AI ofertas sob demanda implantações de GPU Cobrado por segundo. A linha de hardware agora inclui GPUs NVIDIA A100, H100, H200, B200 e B300. Isso oferece às equipes de engenharia a flexibilidade de executar instâncias de modelos privadas e isoladas com capacidade garantida e sem problemas de tráfego vizinho.
O Fire Pass, uma adição recente, é uma assinatura de US$ 7 por semana que oferece acesso ilimitado a tokens do modelo Kimi K2.5 Turbo a velocidades em torno de 200 a 250 tokens por segundo. Ele foi projetado especificamente para desenvolvedores que utilizam ferramentas de codificação agentiva como Claude Code e OpenCode, oferecendo uma alternativa de preço fixo à cobrança imprevisível por token.
Fogos de artifício AI Planos de preços
| Nome do Plano | Custo | Detalhes-chave |
|---|---|---|
| Sem servidor (modelos pequenos) | $ 0.10 por 1 milhão de tokens | Modelos sob parâmetros 4B |
| Sem servidor (nível intermediário) | $ 0.20 por 1 milhão de tokens | Parâmetros dos modelos 4B a 16B |
| Sem servidor (modelos grandes) | $ 0.90 por 1 milhão de tokens | Modelos com base em 16 parâmetros. |
| Sem servidor (Modelos MoE) | De US$ 0.50 a US$ 1.20 por 1 milhão de tokens | Mixtral classe mistura de modelos de especialistas |
| Passagem de incêndio | $ 7 por semana | Tokens ilimitados do Kimi K2.5 Turbo |
| Sob Demanda (H100) | US$ 6.00 por hora de GPU | Cobrança por segundo, instância dedicada. |
| Sob Demanda (B200) | US$ 9.00 por hora de GPU | GPU de última geração, cobrada por segundo. |
| Empreendimento | Molduras por Medida | Descontos anuais, SLAs e implantações privadas. |
Primeiros passos com o Fireworks AI
- Passo 1: Criar uma conta no fogos de artifício.aiVocê receberá automaticamente US$ 1 em créditos gratuitos ao se cadastrar.
- Passo 2: Acesse a seção Chaves de API no seu painel de controle e gere uma nova chave de API.
- Passo 3: Instale o cliente Python do Fireworks ou use qualquer Open.AI SDK compatível. Direcione seu URL base para o endpoint da API do Fireworks.
- Passo 4: Escolha um modelo da biblioteca de modelos, faça sua primeira chamada à API e monitore o uso e a cobrança no console.
Prós e Contras
- Velocidade de inferência líder do setor.
- Mais de 100 modelos de código aberto disponíveis.
- Inclui um sistema completo de ajuste fino.
- O Fire Pass oferece fichas ilimitadas.
- Hardware de GPU de última geração (B300).
- Painel de controle gratuito, sem necessidade de código, exclusivo para desenvolvedores.
- Não há ferramentas de fluxo de trabalho empresarial integradas.
- O suporte ao cliente pode ser lento.
Os melhores fogos de artifício AI Alternativas
| AI Plataforma de Inferência e Servir Modelos | Taxa de transferência de inferência | Eficiência de custos |
|---|---|---|
| Juntos IA | 917 TPS, latência mais alta (0.78s) | Taxas semelhantes por token, menos variedade de GPUs |
| Groq | 456 TPS via LPUs personalizadas, latência de 0.19s | Preços de entrada mais baixos, seleção de modelos limitada. |
| Replicar | Velocidade moderada, baseado em contêineres | Cobrança simples por previsão, menos ajustes finos. |
| Baseten | Infraestrutura personalizável, velocidade moderada | Flexível, mas requer mais configuração. |

