
Entwicklungsteams, die LLM-Dienste bereitstellen, müssen eine wichtige Frage beantworten: Wie zuverlässig und robust ist unser Modell in realen Szenarien?
Die Evaluation großer Sprachmodelle geht heute über einfache Genauigkeitsprüfungen hinaus und nutzt mehrschichtige Frameworks, um Kontexterhaltung, Argumentationsvalidität und die Behandlung von Randfällen zu testen. Der Markt ist überschwemmt mit Modellen von 1B bis 2T Parameter, die Auswahl des optimalen Modells erfordert strenge, mehrdimensionale Bewertungsprotokolle.
In diesem Handbuch werden die technischen Methoden und Kernmetriken beschrieben, die im Jahr 2026 die besten Vorgehensweisen bestimmen und ML-Ingenieuren dabei helfen, Fehler zu erkennen, bevor diese in die Produktion gelangen.
Frameworks für die Evaluierung großer Sprachmodelle
Modernes LLM-Bewertung beinhaltet mehrere quantitative und qualitative Dimensionen ein Modell erfassen's wahre Fähigkeiten. Aktuelle Untersuchungen zeigen, dass 67 % der Unternehmen AI Bereitstellungen weisen aufgrund einer unzureichenden Modellauswahl eine unterdurchschnittliche Leistung auf. Dies verdeutlicht, warum eine anspruchsvolle Evaluierung nicht nur optional, sondern geschäftskritisch ist.

Kernkomponenten der Bewertung
Eine Studie von 2026 aus Stanford's AI Index zeigt, dass Unternehmen, die in umfassende LLM-Evaluierungsprotokolle investieren, einen um 42 % höheren ROI für ihre AI Initiativen im Vergleich zu Initiativen, die vereinfachte Metriken verwenden.
Aufschlüsselung der technischen Kennzahlen
Moderne Bewertungsrahmen verwenden Dutzende spezialisierter Metriken, die jeweils auf bestimmte LLM-Funktionen abzielen:
Leistungskennzahlen:
Verwirrung quantifiziert die Vorhersageunsicherheit durch Berechnung der Exponentialfunktion der durchschnittlichen negativen Log-Likelihood über ein Testkorpus. Niedrigere Werte weisen auf eine bessere Leistung hin, wobei moderne Modelle bei standardisierten Datensätzen eine Perplexität unter 3.0 erreichen.
F1-Punktzahl kombiniert Präzision und Rückruf durch die Formel des harmonischen Mittelwerts:
F1 = 2 * (precision * recall) / (precision + recall)Dadurch entsteht eine ausgewogene Bewertung, die insbesondere bei Klassifizierungsaufgaben mit Klassenungleichgewicht wertvoll ist.
Cross-Entropy-Verlust misst die Diskrepanz zwischen vorhergesagten Wahrscheinlichkeitsverteilungen und der Grundwahrheit mithilfe der Formel:
L(y, ŷ) = -∑(y_i * log(ŷ_i))Dadurch werden sichere, aber falsche Vorhersagen strenger bestraft, was eine Modellkalibrierung fördert.
BLEU (Zweisprachige Evaluationsstudie) berechnet die N-Gramm-Überlappung zwischen generierten und Referenztexten und verwendet dabei einen geometrischen Mittelwert der Präzisionswerte mit einer Kürzestrafe:
BLEU = BP * exp(∑(w_n * log(p_n)))Dabei ist BP die Kürzestrafe und p_n die N-Gramm-Präzision.
RAG-spezifische Metriken
Zu den speziellen Metriken für Retrieval Augmented Generation-Systeme gehören:
Treue quantifiziert die faktische Konsistenz zwischen generierter Ausgabe und abgerufenem Kontext mithilfe von QAG-Ansätzen (Frage-Antwort-Generierung). Die Forschung zeigt RAG-Systeme mit Treuewerten unter 0.7 führen in 42 % der Ausgaben zu Halluzinationen.
Abrufpräzision@K misst den Anteil relevanter Dokumente unter den Top K abgerufenen Ergebnissen:
Precision@K = (number of relevant docs in top K) / KBranchen-Benchmarks legen für Systeme der Unternehmensklasse einen P@3 > 0.85 nahe.
Zitierpräzision Bewertet die Genauigkeit von Zitaten in generierten Inhalten, berechnet wie folgt:
Citation Precision = correct citations / total citationsEine Analyse führender RAG-Systeme zeigt, dass die Zitationspräzision in allen technischen Bereichen durchschnittlich 0.71 beträgt.
Benchmark-Datensätze: Technische Spezifikationen
Benchmark-Datensätze bieten standardisierte Bewertungsrahmen mit spezifischen technischen Merkmalen:

MMLU-Pro Der Kurs umfasst 15,908 Multiple-Choice-Fragen mit jeweils zehn Antwortmöglichkeiten (im Vergleich zu vier im Standard-MMLU) und deckt 10 Bereiche ab, darunter höhere Mathematik, Medizin, Recht und Informatik. Durchschnittliche menschliche Expertenleistung: 4 %.
GPQA Enthält 448 von Experten geprüfte Fragen auf Hochschulniveau mit einer durchschnittlichen Tokenlänge von 612, mit Schwerpunkt auf MINT-Fächern. Aktuelle SOTA-Leistung: 41.2 % Genauigkeit (GPT-4).
MuSR implementiert algorithmisch generierte mehrstufige Schlussfolgerungsprobleme mit Abhängigkeitsgraphen einer durchschnittlichen Tiefe von 4.7, wobei die Modelle verkettete logische Operationen ausführen müssen. Durchschnittliche Leistungslücke zwischen Topmodellen und zufälliger Basislinie: 17.8 Prozentpunkte.
BBH umfasst 23 anspruchsvolle Aufgaben von BigBench mit 2,254 Einzelbeispielen mit Schwerpunkt auf komplexe Argumentation. Diese Aufgaben zeigen eine hohe Korrelation (r=0.82) mit menschlichen Präferenzbewertungen in Blindbewertungen.
LEval ist auf die Auswertung von Langzeitkontexten spezialisiert und umfasst 411 Fragen in acht Aufgabenkategorien mit Kontextlängen von 8 bis 5 Token. Aktuelle Modelle zeigen einen Leistungsabfall von ca. 200 % pro 0.4 zusätzlichen Token.
Auswertungsalgorithmen und Implementierung
Die technische Umsetzung der LLM-Auswertung folgt spezifischen algorithmischen Ansätzen:
Vektorbasierte semantische Auswertung
Moderne Systeme nutzen Vektoreinbettungen, um die semantische Ähnlichkeit zwischen generierten und Referenztexten zu messen. Mithilfe dichter Retrieval-Techniken wie HNSW (Hierarchical Navigable Small World), LSH (Locality-Sensitive Hashing) und PQ (Product Quantization) berechnen diese Systeme Ähnlichkeitswerte mit sublinearer Zeitkomplexität.
python
from sentence_transformers import SentenceTransformer
import numpy as np
model = SentenceTransformer('all-MiniLM-L6-v2')
reference = model.encode("Reference text")
generated = model.encode("Generated text")
similarity = np.dot(reference, generated) / (np.linalg.norm(reference) * np.linalg.norm(generated))Implementierung des DeepEval-Frameworks
DeepEval bietet eine umfassende Auswertung mit metrischen Erklärungen und unterstützt sowohl RAG- als auch Feinabstimmungsszenarien:
python
from deepeval import assert_test
from deepeval.metrics import HallucinationMetric
from deepeval.test_case import LLMTestCase
test_case = LLMTestCase(
input="How many evaluation metrics does DeepEval offers?",
actual_output="14+ evaluation metrics",
context=["DeepEval offers 14+ evaluation metrics"]
)
metric = HallucinationMetric(minimum_score=0.7)
def test_hallucination():
assert_test(test_case, [metric])Dieses Framework behandelt Bewertungen als Unit-Tests mit Pytest-Integration und liefert nicht nur Punktzahlen, sondern auch Erklärungen zu Leistungsstufen.
Parametereffiziente Bewertungsansätze
Für die groß angelegte Auswertung von Modellen mit Milliarden von Parametern haben sich spezielle Techniken entwickelt:

Spärliche Aufmerksamkeitsmechanismen Veteran Rechenkomplexität durch Aufmerksamkeitsmusteroptimierung. Techniken wie Longformer's Aufmerksamkeitsmuster zeigen eine Genauigkeit von 91 % bei voller Aufmerksamkeit mit nur 25 % der Berechnung.
Expertenmix (MoE) Architekturen implementieren bedingte Berechnungspfade und aktivieren nur relevante Subnetze für bestimmte Aufgaben. GShard implementiert MoE-Aufmerksamkeit für eine parametereffiziente Auswertung über verschiedene Benchmarks hinweg.
Wissensdestillation komprimiert größere Lehrermodelle in kleinere, bewertungsspezifische Schülermodelle mithilfe von:
L_distill = α * L_CE(y, ŷ_student) + (1-α) * L_KL(ŷ_teacher, ŷ_student)
Wobei L_CE der Kreuzentropieverlust und L_KL die KL-Divergenz zwischen Wahrscheinlichkeitsverteilungen ist.
Herausforderungen der systematischen Bewertung
Trotz fortschrittlicher Methoden bestehen bei der LLM-Bewertung weiterhin erhebliche Herausforderungen:
Benchmark-Kontamination
Studien zeigen, dass 47 % der gängigen Benchmarks einen gewissen Grad an Verunreinigungen in den Trainingsdaten aufweisen. AI Dies wurde durch die Entwicklung von GSM1k, einer kleineren Variante des mathematischen Benchmarks GSM8k, demonstriert. Die Modelle schnitten bei GSM12.3k um 1 % schlechter ab als bei GSM8k, was eher auf Überanpassung als auf Mathematische Begründung Fähigkeit.
Metrische Korrelationsanalyse
Eine umfassende Analyse von 14 gängigen Metriken in 8 Aufgaben zeigt eine geringe Korrelation zwischen den Metriken (durchschnittlicher Spearman's ρ = 0.41), was darauf hindeutet, dass die Metriken unterschiedliche Leistungsdimensionen erfassen. Dies unterstreicht die Notwendigkeit multimetrischer Bewertungsansätze.
Untersuchungen des MIT zeigen, dass hohe Perplexitätswerte mit menschlichen Präferenzen bei r=0.68 korrelieren, während ROUGE-L nur bei r=0.39 korreliert, was auf unterschiedliche Bewertungsanforderungen hindeutet.
Quantifizierung von Bewertungsverzerrungen
Die statistische Analyse menschlicher Bewertungen offenbart mehrere systematische Verzerrungen:
Diese Erkenntnisse unterstreichen die Bedeutung der Randomisierung und eines ausgewogenen experimentellen Designs in Bewertungsprotokollen.
Best Practices für die Unternehmensbewertung
Um die Herausforderungen bei der Bewertung zu bewältigen, implementieren Sie die folgenden bewährten Methoden der Branche:
Multimodale Metrikintegration
Kombinieren Sie ergänzende Metriken mithilfe gewichteter Ensembles, um ganzheitliche Bewertungsrahmen zu erstellen:
python
def ensemble_score(outputs, references, weights=None):
metrics = {
'bleu': compute_bleu(outputs, references),
'bertscore': compute_bertscore(outputs, references),
'faithfulness': compute_faithfulness(outputs, references),
'coherence': compute_coherence(outputs)
}
if weights is None:
weights = {metric: 1/len(metrics) for metric in metrics}
return sum(weights[metric] * metrics[metric] for metric in metrics)Führende Organisationen implementieren adaptive Gewichtungsschemata basierend auf aufgabenspezifischen Anforderungen, wobei bei technischen Inhalten die Genauigkeit (Gewichtung: 0.4) gegenüber der Flüssigkeit (Gewichtung: 0.2) priorisiert wird.
Domänenspezifische Evaluierungsprotokolle
Technische Benchmarks sollten auf spezifische Anwendungsfälle abgestimmt sein. Für GesundheitsanwendungenZu den speziellen Metriken gehören:
- Genauigkeit der medizinischen Terminologie (89 % Übereinstimmung mit der Beurteilung durch den Kliniker)
- Validierung des Clinical Reasoning-Pfads (75 % Übereinstimmung mit dem Expertenkonsens)
- Präzision der Beweismittelbeschaffung aus der medizinischen Literatur (P@10 > 0.92 für den Unternehmenseinsatz)
Diese domänenspezifischen Metriken ermöglichen eine 3.2-mal bessere Leistungsvorhersage als allgemeine Benchmarks.
Implementierung der kontroversen Bewertung
Implementieren Sie strukturierte Adversarial-Tests, um die Einschränkungen des Modells zu untersuchen:
python
def adversarial_test_suite(model, test_cases):
results = {}
for category, cases in test_cases.items():
correct = 0
for case in cases:
response = model.generate(case['input'])
correct += evaluate_response(response, case['expected'])
results[category] = correct / len(cases)
return resultsBranchenforschung zeigt kontradiktorische Prüfung identifiziert 32 % mehr Fehlermodi als Standard-Benchmarking, insbesondere in Randfällen mit widersprüchlichen Einschränkungen oder mehrdeutigen Anweisungen.
Vergleich des technischen Bewertungsrahmens
Führende Evaluierungsframeworks bieten unterschiedliche technische Möglichkeiten:
| Unser Ansatz | Hauptfokus | Technische Stärke | Einschränkung | Integrationskomplexität |
|---|---|---|---|---|
| DeepEval | RAG & Feinabstimmung | 14+ spezialisierte Metriken mit Erklärungen | Eingeschränkte multimodale Unterstützung | Mittel (Python-basiert) |
| PromptFlow | End-to-End-Evaluierung | Schnelle Variantenprüfung | Eingeschränkte Dataset-Unterstützung | Niedrig (UI-gesteuert) |
| LangSmith | Entwicklerplattform | Lückenlose Rückverfolgung und Überwachung | Höherer Implementierungsaufwand | Hoch (erfordert API-Integration) |
| Prometheus | LLM als Richter | Systematische Aufforderungsstrategien | Richter LLM Bias-Abhängigkeit | Mittel (erfordert leistungsstarkes LLM) |
| LEval | Langzeitanalyse | 200-Token-Bewertung | Beschränkt auf Textmodalität | Niedrig (Benchmark-Datensatz) |
Organisationen implementieren typischerweise mehrere Frameworks, wobei 73 % der Unternehmensbereitstellungen mindestens zwei sich ergänzende Evaluierungstools verwenden.
Zukünftige technische Entwicklungen
Die Evaluierungslandschaft entwickelt sich mit neuen Methoden ständig weiter:
Suche nach neuronaler Architektur (NAS) für auswertungsspezifische Modelle gewinnt an Bedeutung. Untersuchungen zeigen, dass die automatisierte Optimierung der Modellarchitektur die Auswertungseffizienz um 47 % verbessern kann, während gleichzeitig eine Genauigkeit von 98 % erhalten bleibt.
Multimodale Beurteilung Frameworks erweitern sich über den Text hinaus, um einheitliche Modelle, die Text verarbeiten, Bilder, Audio und Video. Aktuelle Frameworks erreichen eine modalübergreifende Erdungsgenauigkeit von 76.3 % im Vergleich zu menschlichen Basiswerten von 91.4 %.
Kennzahlen zur Energieeffizienz Quantifizieren Sie die rechnerische Nachhaltigkeit anhand von FLOPs/Token, der Inferenz von Wattstunden und CO10-Emissionsmetriken. Branchen-Benchmarks legen nahe, dass optimale Modelle weniger als 1 MWh pro XNUMX generierten Token erreichen sollten.
Kontinuierliche Evaluierungspipelines Integrieren Sie Tests während der gesamten Entwicklung mithilfe verteilter Evaluierungsworkflows:
Preprocessing → Feature Extraction → Model Inference → Metric Computation → Statistical Analysis → Reporting
Unternehmen, die eine kontinuierliche Evaluierung durchführen, berichten von 68 % weniger Problemen nach der Bereitstellung und 41 % schnelleren Iterationszyklen.
Fallstudien zur Implementierung in der Praxis
Unternehmensimplementierungen demonstrieren technische Bewertung's praktische Auswirkungen:
Finanzdienstleistungen RAG-Optimierung
Ein führendes Finanzinstitut hat eine umfassende RAG-Evaluierung für sein kundenorientiertes Beratungssystem durchgeführt:
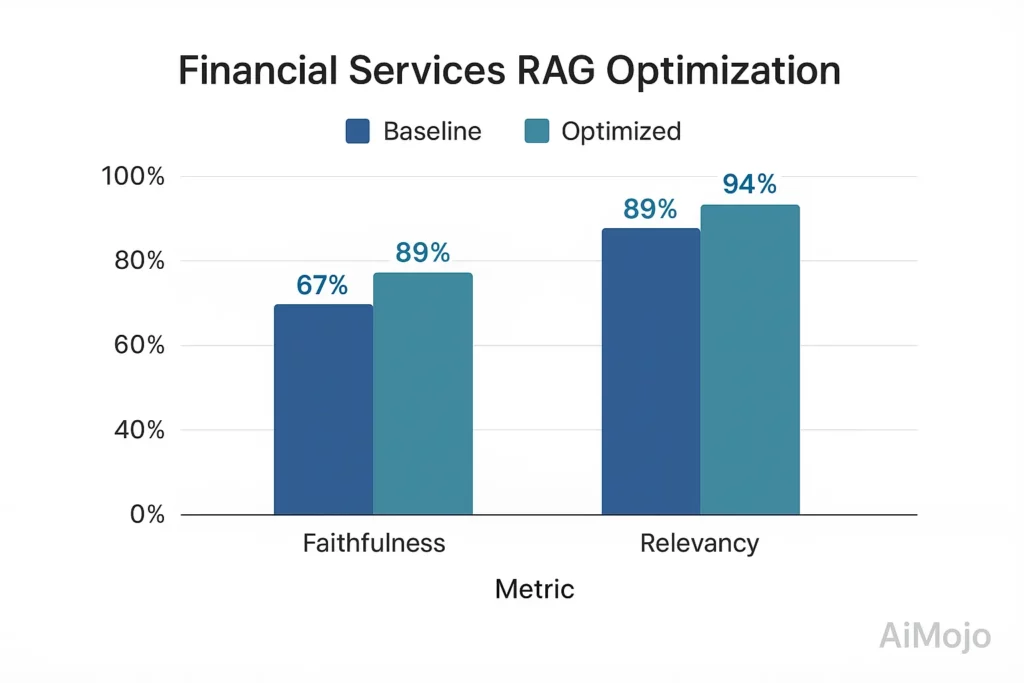
- Grundlinie: 67 % Treue, 82 % Antwortrelevanz
- Nach der bewertungsgesteuerten Optimierung: 89 % Treue, 94 % Antwortrelevanz
- Implementierung: Maßgeschneidert Finanzbereich Testsuite mit 5,216 von Experten verifizierten QA-Paaren
- Technischer Ansatz: Treuebewertung mittels tensorbasierter Implikationsmessung mit kontrafaktischen Tests
Diese durch Auswertungen erzielte Verbesserung verringerte die Probleme bei der Einhaltung gesetzlicher Vorschriften um 78 % und steigerte die Kundenzufriedenheit um 23 Prozentpunkte.
Bereitstellung eines LLM im Gesundheitswesen
Ein Gesundheitsdienstleister hat eine mehrschichtige Evaluation zur Unterstützung klinischer Entscheidungen implementiert:
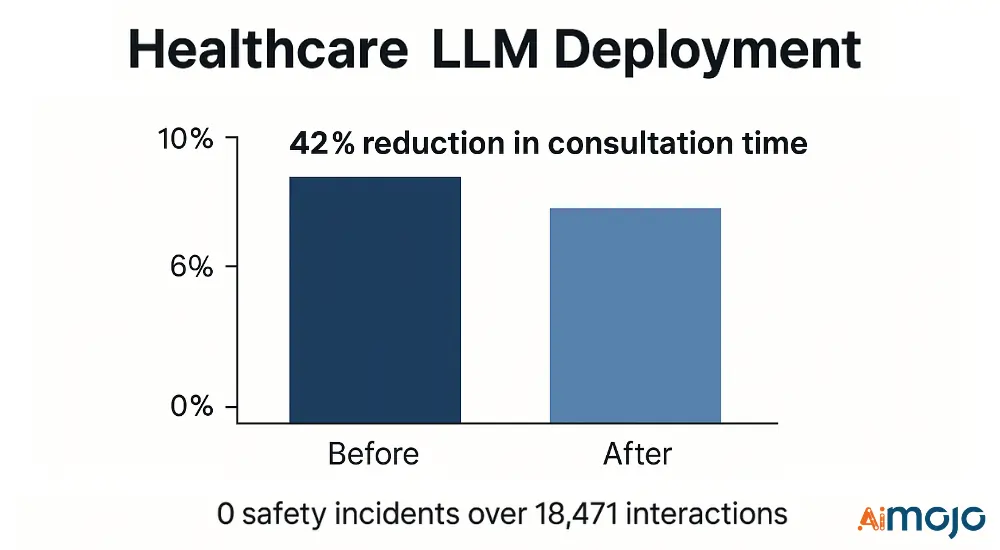
- Technische Kennzahlen: Medizinischer NER F1-Score (0.91), Genauigkeit der klinischen Argumentation (87.4 %), Präzision der Sicherheitsfilterung (99.2 %)
- Implementierung: 3-stufige Filterpipeline mit spezialisierten Validierern für das Gesundheitswesen
- Ergebnisse: 42 % Verkürzung der Konsultationszeit mit 0 Sicherheitsvorfällen bei 18,471 klinischen Interaktionen
Der Evaluierungsrahmen identifizierte und entschärfte vor der Bereitstellung 17 kritische Fehlermodi und verhinderte so potenzielle unerwünschte Ereignisse.
LLM-Evaluation: Ihr Fahrplan zum Erfolg
Die technische Evaluierung von LLMs hat sich von einfachen Genauigkeitsprüfungen zu umfassenden Frameworks entwickelt, die mehrere Leistungsdimensionen berücksichtigen. Organisationen, die diese strengen Protokolle übernehmen und integrieren automatisierte Bewertung, Benchmark-Tests und menschliche Überwachung-Erzielen Sie eine zuverlässigere Modellauswahl und bessere Ergebnisse.
Regelmäßige, adaptive Testpipelines decken Fehler vor der Bereitstellung auf, wodurch die Kosten für die Vorab-Evaluierung im Vergleich zu den Risiken eines fehlerhaften Systems gering bleiben. Für Entwicklungsteams sind robuste Validierungsschritte mehr als Entwicklungsaufgaben; sie sind wesentliche Sicherheitsvorkehrungen für Unternehmen.
Im Jahr 2026 und darüber hinaus werden Teams, die ihre Bewertungsmethoden verfeinern, die Zuverlässigkeit ihrer LLMs gewährleisten, kostspielige Fehler vermeiden und das Vertrauen der Benutzer aufrechterhalten.



 BONUS: Holen Sie sich unsere 200 $“AI „Mastery Toolkit“ KOSTENLOS bei der Anmeldung!
BONUS: Holen Sie sich unsere 200 $“AI „Mastery Toolkit“ KOSTENLOS bei der Anmeldung!






