Crawl4AI Key Insights
What is Crawl4AI?
Crawl4AI is a free, open source Python library that converts web pages into clean Markdown, structured JSON, or filtered HTML that large language models can consume directly. Built on top of Playwright for browser automation, it serves developers building RAG pipelines, AI agents, and automated data workflows. The tool supports both LLM powered and LLM free extraction strategies, giving teams full control over cost and output quality.
With more than 60,000 GitHub stars and over 900,000 monthly PyPI downloads, Crawl4AI has become one of the most popular web scraping tools in the AI engineering community. It runs entirely on your own infrastructure, so there are no API keys required and no per page fees. For teams that need production scale data extraction for business automation, Crawl4AI offers the flexibility to plug into any LLM provider while keeping the crawling layer completely free.
Crawl4AI produces two types of Markdown output as described on its official site. Clean Markdown preserves accurate page formatting with headings, tables, code blocks, and citation hints. Fit Markdown applies heuristic based filtering through a pruning algorithm or BM25 relevance scoring to strip boilerplate, navigation, and footer noise.
This dual output is specifically designed for RAG pipelines and direct LLM ingestion. Users can also build custom Markdown generation strategies to match their exact pipeline requirements.
The tool provides two distinct extraction paths. For pages with predictable layouts, the CSS and XPath based JsonCssExtractionStrategy pulls structured JSON using schema definitions and requires zero LLM calls.
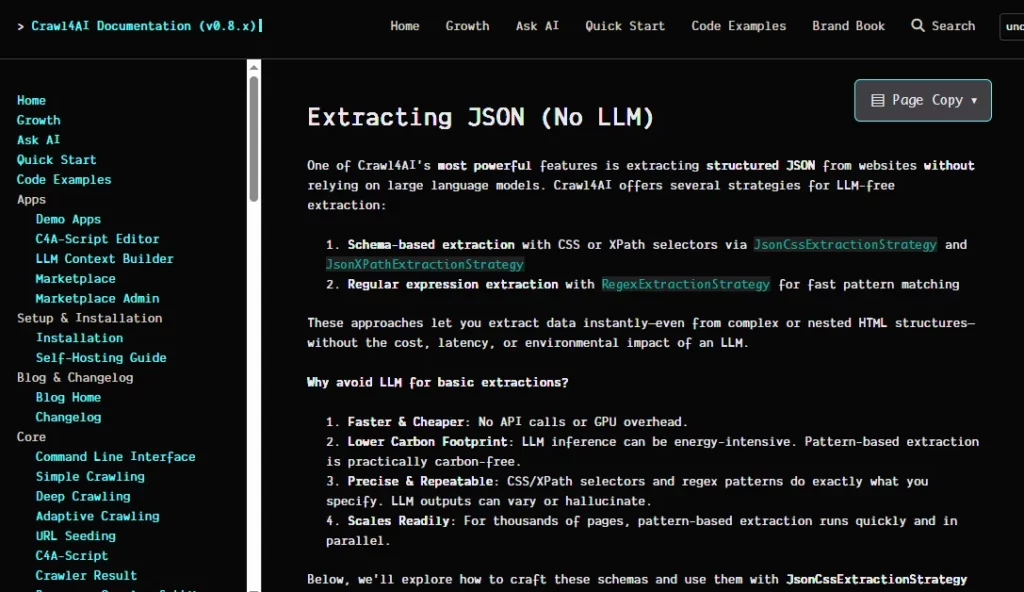
For complex or unpredictable pages, the LLMExtractionStrategy connects to any LLM provider (OpenAI, Ollama, DeepSeek, and others) and uses Pydantic schemas to return perfectly structured data. Chunking strategies including topic based, regex, and sentence level processing handle large pages efficiently.
Announced on crawl4ai.com as a flagship capability, adaptive crawling uses information foraging algorithms with a three layer scoring system that measures coverage, consistency, and saturation. Rather than crawling every page on a site, it evaluates content relevance at each step and stops automatically when confidence thresholds are met.
It supports both a statistical strategy (fast, free, term based) and an embedding strategy (semantic understanding with query expansion). This prevents over crawling and saves significant compute resources.
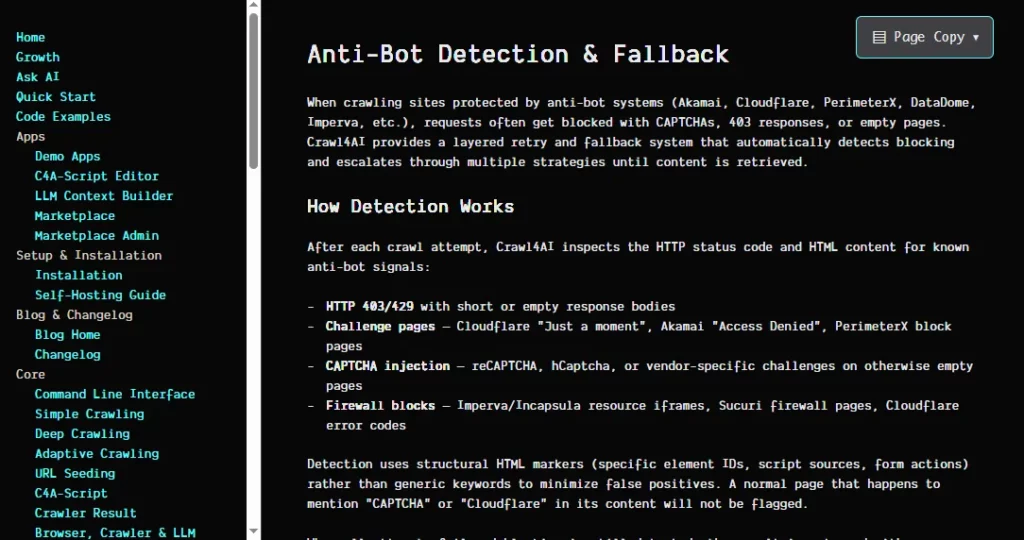
Introduced in v0.8.5, the three tier anti bot detection system checks known vendor signatures, generic block indicators, and structural integrity of returned pages. When a block is detected, the system automatically retries through a configurable proxy chain with fallback fetch functions. Combined with stealth mode that mimics real user behaviour and the undetected browser mode from v0.7.3, this gives Crawl4AI a strong toolkit for accessing protected sites.
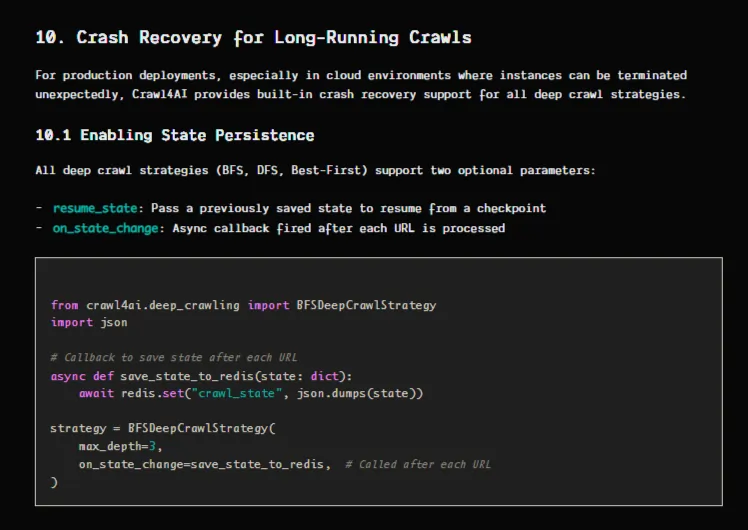
For large scale jobs that span thousands of pages, deep crawl strategies (BFS, DFS, Best First) include built-in crash recovery as released in v0.8.0. An on_state_change callback persists state after each URL, and the resume_state parameter lets you continue from the exact checkpoint after a failure.
The prefetch mode skips Markdown generation and extraction entirely, enabling URL discovery at 5 to 10 times normal speed for two phase crawling workflows.
Crawl4AI ships an optimised Docker image featuring a FastAPI server, JWT token authentication, a real time monitoring dashboard with live system metrics, and a three tier browser pool (permanent, hot, cold) with page pre-warming. The interactive playground lets teams test crawl configurations and generate request code without writing scripts.
MCP integration connects directly to AI tools like Claude Code. Multi architecture support with automatic AMD64 and ARM64 detection ensures it runs on any cloud provider.
Crawl4AI Pricing Plans
| Plan Name | Cost | Key Details |
|---|---|---|
| Open Source (Self Hosted) | $0 | Unlimited crawls, full feature set, you provide infrastructure |
| Cloud API (Closed Beta) | Custom | Managed service, apply for early access, limited slots |
| Believer Sponsor | $5/mo | Community support tier, back the project |
| Builder Sponsor | $50/mo | Priority support and early access to new features |
| Growing Team Sponsor | $500/mo | Bi weekly syncs and optimisation guidance |
| Data Infrastructure Partner | $2,000/mo | Dedicated support and full partnership |
How Crawl4AI Handles Markdown Generation?
Crawl4AI produces two types of Markdown output. Raw Markdown preserves the full page structure including navigation elements and footers. Fit Markdown applies heuristic filtering using a pruning algorithm or BM25 relevance scoring to strip noise and keep only the core content. This is particularly valuable for RAG pipelines where embedding quality depends on clean input text.
You can also implement custom Markdown generation strategies by extending the base class, giving full control over how HTML elements map to Markdown tokens. The citation system converts page links into numbered references, which helps LLMs track source attribution during retrieval tasks.
Pros and Cons
- 60,000+ stars active community.
- Apache 2.0 permissive licence.
- Works with any LLM provider.
- Async architecture for speed.
- Deep crawl crash recovery built in.
- No managed cloud service yet.
- No GUI or visual interface.
- Anti bot handling needs proxy setup.
Best Crawl4AI Alternatives
| AI Web Crawler and Scraper | Self Hosted Option | LLM Free Extraction |
|---|---|---|
| Firecrawl | Limited (AGPL 3.0 restrictions apply) | No, requires LLM for structured JSON |
| Apify | No, fully cloud dependent platform | No, relies on AI models for parsing |
| ScrapeGraphAI | Yes, open source Python library (MIT) | No, every extraction requires an LLM call |


