
Raske justeringer alene er ikke lenger nok for bedrifter AI systemer. Etter hvert som modellkontekstvinduer øker med over 200 XNUMX tokens, pakker ingeniører nå LLM-en inn i dokumenter, hentepipeliner, kladdeblokker og verktøykall – en tilnærming merket kontekstteknikk.
Skiftet skjedde raskt.
Kontekstutvikling bygger bro over dette gapet ved å behandle hele AI miljø som et system i stedet for å fokusere på individuelle innspill.
Kontekstutvikling:
Systemet som faktisk fungerer
Kontekstutvikling behandler hele pipelinen før LLM-kallet som konstruerbar infrastruktur. Tenk på en LLM's kontekstvindu som RAM – det har begrenset arbeidsminne som bestemmer hva modellen kan behandle.
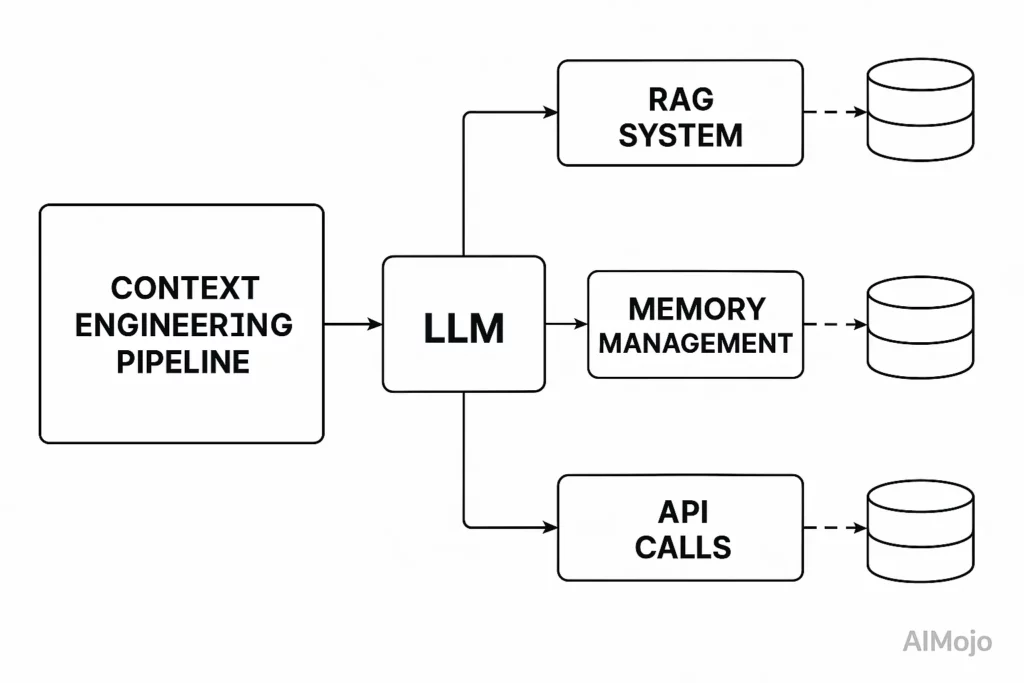
Akkurat som et operativsystem nøye administrerer hva som går inn i RAM, kuraterer kontekstteknikk hvilken informasjon som fyller LLM-en.'s kontekstvindu.
Her's hva kontekstteknikk egentlig inkluderer:
Kontekstteknikk vs. promptteknikk:
Tallene lyver ikke
| Aspekt | Rask Engineering | Kontekstteknikk |
|---|---|---|
| Fokus | Lage én inputstreng | Orkestrerer hvert signal rundt modellen |
| Gjennomsnittlig utviklingstid | 70 % raske justeringer | 60 % datapipelines, 20 % minneregler, 20 % ledetekster |
| Typisk feilmodus | Plutselig fall i utskriftskvaliteten etter dataavvik | Robust via RAG, minne, verktøykall |
Raskt eksempel: En kundestøttebot trent med bare ledetekster kan huske refusjonspolicyen når de blir spurt direkte. Når brukeren refererer til «ordre 45791», mislykkes det. Legg til kontekstteknikk – samtalehistorikk pluss en RAG-spørring i ordredatabasen – og roboten henter umiddelbart kjøpsdetaljer og anbefaler riktig refusjonsprosess.
De fire søylene innen kontekstteknikk som faktisk betyr noe
1. Skrivekontekst (din AI's Notatsystem)
Å skrive kontekst betyr å lagre informasjon utenfor kontekstvindu for fremtidig bruk. Dette bevarer verdifull tokenplass samtidig som tilgangen til viktige data opprettholdes.
Kladdeblokker fungerer som notatskriving for agenter i løpet av en enkelt økt. Antropisk's multiagentforsker lagrer sin opprinnelige plan til «Minne«fordi hvis konteksten overstiger 200,000 XNUMX tokens, blir den avkortet og planen går tapt.»

Langtidsminner beholde informasjon på tvers av flere økter. Eksempler inkluderer ChatGPT som automatisk genererer brukerpreferanser fra samtaler og markør-/vindsurfinglæring kodemønstre og prosjektkontekst.

2. Kontekstvalg (Kunsten å velge det som betyr noe)
Kontekstvalg bringer inn kun den relevante informasjonen for oppgaven.
Når en AI treningstrener genererer en treningsplan, må den velge kontekstdetaljer som inkluderer brukeren's høyde, vekt og aktivitetsnivå, samtidig som irrelevant informasjon ignoreres.
NøkkelinnsiktenMer informasjon er ikke alltid bedre. Effektiv kontekstutvikling betyr å velge riktig kombinasjon for hver spesifikke oppgave.
3. Kontekstkomprimering (få plass til mer på mindre)
Når samtaler blir så lange at de overskrider LLM's minne vinduet, blir kontekstkomprimering kritisk. Agenter oppnår vanligvis dette ved å oppsummere tidligere deler av samtalen.

4. Kontekstisolasjon (Splitt og hersk)
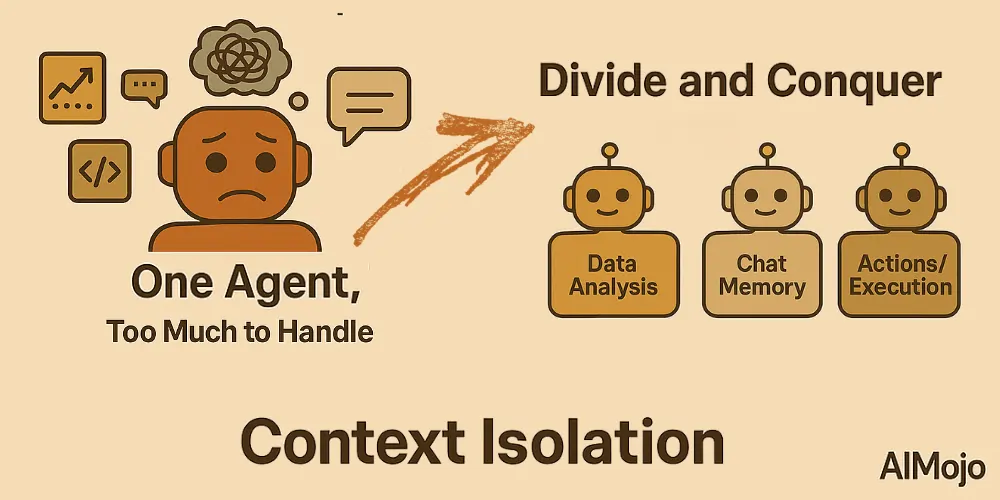
Kontekstisolering betyr å dele opp informasjon i separate deler slik at agenter bedre kan håndtere komplekse oppgaver. I stedet for å stappe all kunnskap inn i én massiv ledetekst, deler utviklere kontekst på tvers av spesialiserte underagenter eller sandkassemiljøer.
Kontekstutvikling i den virkelige verden i aksjon
Kundeservicerevolusjonen
| Før kontekstutvikling | Etter kontekstutvikling |
|---|---|
| Generiske chatboter som glemmer tidligere samtaler og gir irrelevante svar. | AI agenter som husker kjøpshistorikken din, får tilgang til sanntidslagerdata og koordinerer med menneskelige agenter ved behov. |
Kodeassistenten som aldri glemmer
SystemetNår du spør «Hvordan fikser jeg denne autentiseringsfeilen?», gjør kontekstutviklingssystemet automatisk følgende:

I stedet for generiske koderåd får du spesifikke løsninger skreddersydd til din faktiske kodebase.
Den tekniske arkitekturen som driver kontekstutvikling
Dynamisk kontekstsamling
Kontekst bygges opp underveis og utvikler seg etter hvert som samtalene skrider frem. Dette inkluderer:
- Henting av relevante dokumenter
- Opprettholde hukommelsen
- Oppdaterer brukerstatus
- API-kall og databasespørringer
Kontekstvinduhåndtering
Med fast størrelse symbolske grenser (32K, 100K, 1M), må ingeniører komprimere og prioritere informasjon intelligent ved hjelp av:
- Poengfunksjoner (TF-IDF, innebygginger, oppmerksomhetsheuristikker)
- Oppsummering og fremtredende utvinning
- Chunking-strategier og overlappingsjustering

Sikkerhet og konsistens
Anvend prinsipper som rask injeksjonsdeteksjon, kontekstsanering, PII-redaksjonog rollebasert kontekstbasert tilgangskontroll.
Bygg ditt første konteksttekniske system
Å bygge en kontekstutviklingsarbeidsflyt er ikke bare teori – det's en repeterbar prosess som kan operasjonaliseres og til og med automatiseres. Slik kan du sette den ut i livet:
Trinn 1: Kartlegg kontekstkildene dine
Identifiser hvor agenten din trenger å hente informasjon fra (dokumenter, databaser, API-er, tidligere chatter osv.).
python
# Example: Fetching relevant documents using embeddings
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer("all-MiniLM-L6-v2")
query = "project status update"
corpus = ["spec doc", "requirements", "last week's meeting notes"]
query_embedding = model.encode(query, convert_to_tensor=True)
corpus_embeddings = model.encode(corpus, convert_to_tensor=True)
hits = util.semantic_search(query_embedding, corpus_embeddings, top_k=2)[0]
relevant_docs = [corpus[hit['corpus_id']] for hit in hits]
Trinn 2: Implementer minne og skrivekontekst
Lagre viktig informasjon slik at den alltid er der for fremtidige oppgaver.
python
import json
def save_to_memory(memory_path, user_id, data):
with open(memory_path, "r+") as file:
memory = json.load(file)
memory[user_id] = data
file.seek(0)
json.dump(memory, file)
file.truncate()Trinn 3: Bygg kontekstvalg og komprimeringslogikk
Utvikle regler eller modeller som kun velger det som er mest relevant for oppgaven. Komprimer lange historikker til oppsummerte former.
python
def summarize_conversation(history):
# Placeholder for use with an LLM summarizer or custom rules
return history[-5:] # Only the last 5 messagesTrinn 4: Isoler kontekster for agentkoordinering
Del informasjon slik at hver agent eller komponent bare håndterer det den skal.
python
user_profile_ctx = {"user_goals": "..."}
task_specific_ctx = {"current_task": "..."}
external_data_ctx = {"live_data": "..."}
full_context = {**user_profile_ctx, **task_specific_ctx, **external_data_ctx}Trinn 5: Utdatastrukturering og API-klargjøring
Formater utdatakonteksten konsekvent slik at den's forutsigbar for nedstrøms LLM-kall eller API-endepunkter.
python
schema = {
"user": {"age": 35, "goal": "muscle gain"},
"plan": "high protein, 3x/week weight training"
}Trinn 6: Overvåk, iterer og sikre
Spor feil, revider kontekstkvaliteten og forbedre logikken for kontekstinkludering, minne og henting. Rens alltid inndata for å unngå rask injeksjon og datalekkasjer.
Hvorfor kontekstutvikling lønner seg mer enn rask utvikling
Bedrifter trenger ingeniører som kan bygge systemer som gir riktig kontekst til AI, holder informasjon nøyaktig og oppdatert, og beskytter brukere ved å legge til sikkerhetsretningslinjer.
MarkedsvirkelighetenKontekstteknikk krever tverrfaglige ferdigheter som innebærer å forstå forretningsbrukstilfeller, definere resultater og strukturere informasjon slik at LLM-er kan utføre komplekse oppgaver.
Bottom line: Hvem som helst kan skrive ledetekster. Bygge kontekstbevisste agenter som husker, tilpasser og velger kontekst i stor skala? Slik fremtidssikrer utviklere ferdighetene sine og leverer faktisk verdi med avanserte LLM-applikasjoner.



 BONUS: Få våre 200 dollarAI «Mestringsverktøysett» GRATIS når du registrerer deg!
BONUS: Få våre 200 dollarAI «Mestringsverktøysett» GRATIS når du registrerer deg!






