
Benieuwd naar het bouwen, verfijnen of implementeren Grote taalmodellen?
Je bent niet de enige: LLM-expertise is een van de meest gewilde vaardigheden in AI Vandaag. Met open source-projecten GitHub groeit snel en is uitgegroeid tot de go-to hub voor top-tier LLM-projecten, -kaders en -onderzoek.
Deze gids belicht 12 essentiële GitHub-opslagplaatsen vol met broncode, praktische tutorials en modelimplementaties.
Bewijs het LLM-kennis, versnel uw leerproces en sluit u aan bij de wereldwijde community die de toekomst van kunstmatige intelligentie vormgeeft. Dit alles doet u met deze onmisbare GitHub-repositories.
Waarom GitHub Is essentieel voor LLM-ontwikkeling
GitHub is uitgegroeid tot het kloppende hart van het LLM-ecosysteem, waar baanbrekend onderzoek samenkomt met praktische implementatie. Terwijl academische papers theorie leveren, levert GitHub de daadwerkelijke code die vandaag de dag de basis vormt.'s de meest geavanceerde taalmodellen.
Het platform host alles van Meta's Llama-implementaties naar OpenAI's Onderzoek codebases, waardoor dit de snelste manier is om toegang te krijgen tot bewezen technieken en op de hoogte te blijven van snelle ontwikkelingen.
Belangrijkste redenen waarom GitHub de ontwikkeling van LLM domineert:
Voor LLM-enthousiastelingen is GitHub niet alleen een bron, maar ook een's uw directe lijn naar de toekomst van AI ontwikkeling.
1. llm-cursus

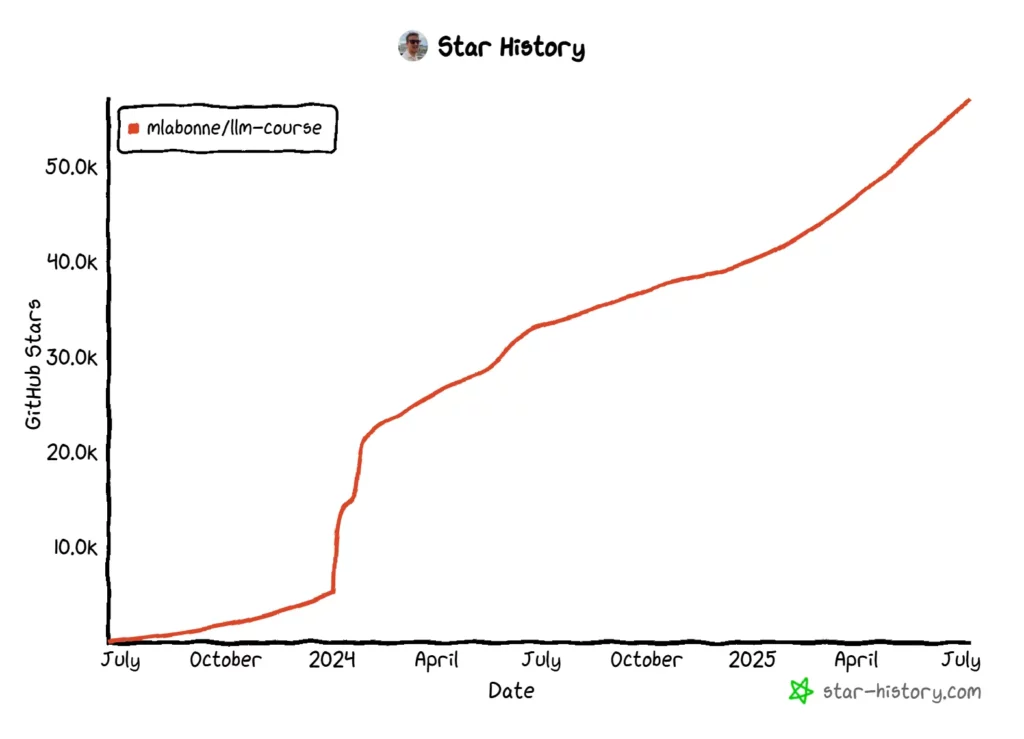
Maxime Labonne's llm-cursus is een fantastisch startpunt en een uitgebreide routekaart voor iedereen die serieus bezig is met LLM's leren. Het's meer dan alleen een verzameling bestanden; het's Een gestructureerd leerpad dat aansluit bij verschillende carrièredoelen. De repository is enorm populair geworden en heeft meer dan 51,500 sterren op GitHub.
Waarom het's een topkeuze
Deze repository onderscheidt zich doordat deze twee verschillende routekaarten biedt, waarmee u uw leertraject op maat kunt maken:
De cursus behandelt alles van de basisprincipes van LLM wiskunde tot geavanceerde onderwerpen zoals kwantificering, fine-tuning en modelimplementatie. Het is een compleet pakket voor cursisten op alle niveaus.
BELANGRIJKSTE KENMERKEN
Wie zou het moeten gebruiken?
Deze repository is perfect voor zowel beginners die behoefte hebben aan een gestructureerde introductie als voor ervaren professionals die hun expertise op specifieke gebieden van LLM-ontwikkeling willen verdiepen.
2. HandsOnLLM
De HandsOnLLM/Hands-On-Large-Language-Models-repository is de officiële aanvulling op de O'Reilly-boek met dezelfde naam. Het's Een visueel rijke en praktische gids die de werking van LLM's verduidelijkt. Als je het beste leert door te doen en goed gedocumenteerde codevoorbeelden waardeert, dan is deze repository iets voor jou.
Waarom het's een topkeuze
Het biedt een praktische, projectmatige leerbenadering. Elk hoofdstuk van het boek gaat vergezeld van Jupyter-notebooks, zodat je de code zelf kunt volgen en ermee kunt experimenteren. Het richt zich op projecten uit de praktijk en voorbeelden die je kunt aanpassen aan je eigen gebruiksscenario's.

BELANGRIJKSTE KENMERKEN
Wie zou het moeten gebruiken?
Ontwikkelaars en datawetenschappers die de voorkeur geven aan een praktische, projectmatige leerstijl, zullen deze repository enorm waardevol vinden. Het is ook een uitstekende bron voor iedereen die het boek "Hands-on Large Language Models" leest.
3. snelle engineering
De brexhq/prompt-engineering gids is een schatkamer voor het beheersen van de kunst en wetenschap van snelle techniekIn de wereld van LLM's wordt de kwaliteit van je output vaak bepaald door de kwaliteit van je input, waardoor deze vaardigheid absoluut essentieel is. Deze databank, met bijna 9,000 sterren, biedt praktische tips en strategieën voor het werken met modellen zoals GPT-4.
Waarom het's een topkeuze
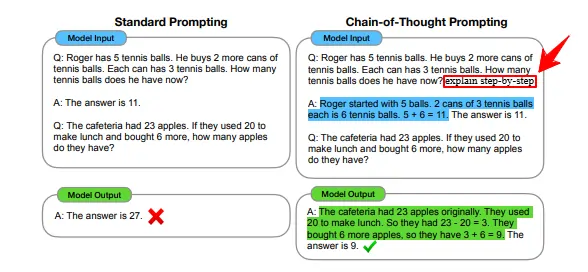
Het consolideert de lessen die zijn geleerd bij het maken van prompts voor productie-use cases, waardoor het zeer praktisch is. De repository is overzichtelijk ingedeeld in tutorials die alles behandelen, van basisprincipes tot geavanceerde technieken zoals Aanleiding voor de gedachteketen (CoT) en zelfconsistentie.
BELANGRIJKSTE KENMERKEN
Wie zou het moeten gebruiken?
Iedereen die met LLM's werkt, van ontwikkelaars en onderzoekers tot content creators en marketeers, zal baat hebben bij deze repository. Het beheersen van prompt engineering is een essentiële vaardigheid om het maximale uit elk taalmodel te halen.
4. Geweldig-LLM
De Hannibal046/Awesome-LLM-repository is een samengestelde lijst met alles wat met grote taalmodellen te maken heeft. Zie het als je centrale dashboard om op de hoogte te blijven van het LLM-ecosysteem. Het is een levende verzameling bronnen die regelmatig door de community wordt bijgewerkt.
Waarom het's een topkeuze
Deze repository bespaart je talloze uren zoekwerk door essentiële bronnen op één plek te verzamelen. Het bevat baanbrekende onderzoeksartikelen, trainingskaders, implementatietools en evaluatiebenchmarks. Het bevat zelfs een scorebord om de prestaties van verschillende LLM's te volgen.
BELANGRIJKSTE KENMERKEN
Wie zou het moeten gebruiken?
Dit is een must-have voor onderzoekers, studenten en professionals die op zoek zijn naar een one-stop-shop voor hoogwaardige LLM-bronnen. Perfect om nieuwe tools te ontdekken en op de hoogte te blijven van het laatste onderzoek.
5. ToolBench
Naarmate LLM's steeds actiever worden, wordt hun vermogen om externe tools te gebruiken steeds belangrijker. De OpenBMB/ToolBench-repository is een open source platform Ontworpen om LLM's te trainen, te begeleiden en te evalueren voor het leren van tools. Het biedt een raamwerk en een grootschalige dataset voor instructie-afstemming om deze mogelijkheden te verbeteren.
Waarom het's een topkeuze
ToolBench richt zich op een cruciaal en trending gebied binnen LLM-ontwikkeling: gereedschapsgebruik. De StableToolBench-extensie versterkt dit verder door functies te introduceren zoals MirrorAPI, die duizenden simuleert echte API'sEn een Virtueel API-systeem om stabiliteit en consistentie tijdens de evaluatie te garanderen.

BELANGRIJKSTE KENMERKEN
Wie zou het moeten gebruiken?
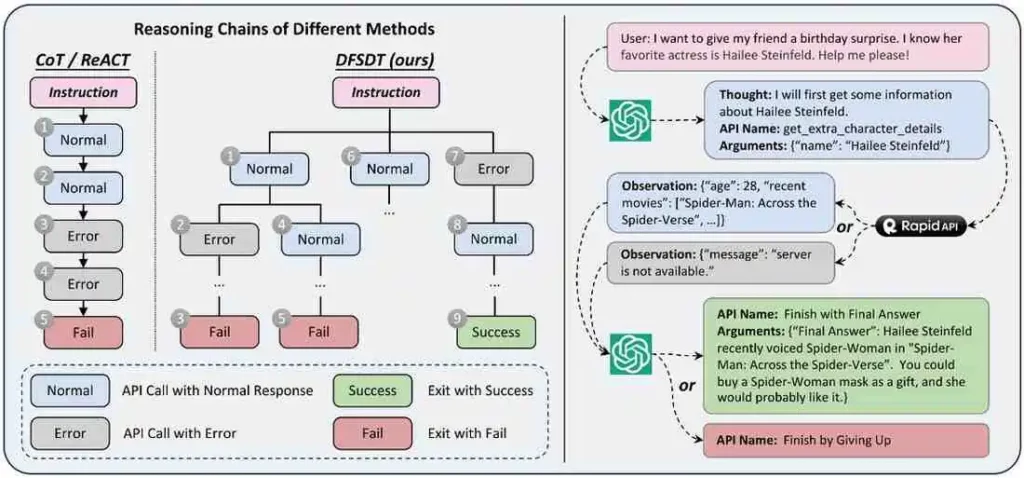
Onderzoekers en ontwikkelaars die geïnteresseerd zijn in het bouwen van agentische LLM's die kunnen interacteren met externe API's en tools zullen ToolBench van onschatbare waarde vinden. Het is ideaal voor iedereen die werkt aan het creëren van capabelere en autonomere AI agenten.
6. Pythia
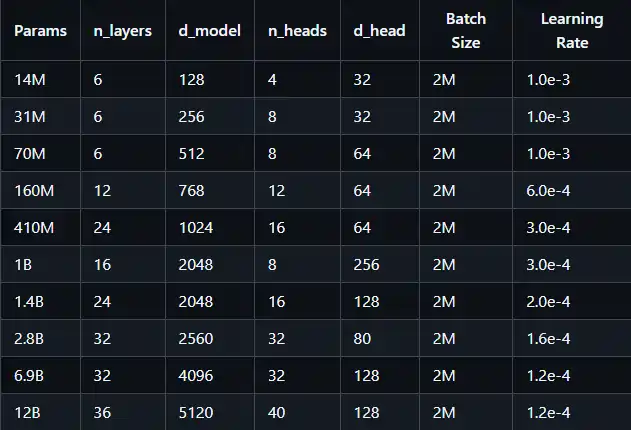
De EleutherAI/pythia-repository, ontwikkeld door EleutherAI, is een reeks modellen die ontworpen zijn om onderzoek naar interpreteerbaarheid, leerdynamiek en ethiek mogelijk te maken. In tegenstelling tot veel andere modelreleases is de Pythia-suite ontwikkeld met transparantie en wetenschappelijk onderzoek als primaire doelen.
Waarom het's een topkeuze
Pythia biedt volledig open-source toegang tot 16 verschillende modelcheckpoints, waardoor onderzoekers kunnen bestuderen hoe LLM's zich ontwikkelen en evolueren tijdens de opleiding. Dit is cruciaal voor het begrijpen van de 'black box'-aard van deze modellen en voor onderzoek naar gebieden zoals schaalwetgeving en modelethiek.
BELANGRIJKSTE KENMERKEN
Wie zou het moeten gebruiken?
AI Onderzoekers, ethici en studenten die zich richten op de interpreteerbaarheid van modellen, veiligheid en de fundamentele principes van de LLM-opleiding, zullen veel profijt hebben van deze databank.
7. LLM-Agent-Papier-Lijst
Voor degenen die zich willen verdiepen in de academische kant van AI agentenDe WooooDyy/LLM-Agent-Paper-List is een essentiële bron. Deze databank is een zorgvuldig samengestelde verzameling onderzoeksartikelen die systematisch de ontwikkeling, toepassing en implementatie van... LLM-gebaseerde agenten.
Waarom het's een topkeuze
Het dient als een fundamentele kennisbibliotheek voor een van de meest opwindende vakgebieden in AI vandaag. In plaats van alleen code biedt deze repository de theoretische onderbouwing die u nodig hebt om de volgende generatie te begrijpen en te bouwen. AI agenten.
BELANGRIJKSTE KENMERKEN
Wie zou het moeten gebruiken?
Deze repository is bedoeld voor academische onderzoekers, afgestudeerde studenten en gevorderde professionals die willen voortbouwen op baanbrekend onderzoek op het gebied van LLM-gebaseerde agenten.
8. Geweldige multimodale groottalige modellen
LLM's beperken zich niet langer tot alleen tekst. De BradyFU/Awesome-Multimodal-Large-Language-Models repository is een zorgvuldig samengestelde verzameling bronnen gericht op de nieuwste ontwikkelingen in multimodale LLM's (MLLM's), die informatie uit tekst, afbeeldingen, audio en video kunnen verwerken.
Waarom het's een topkeuze
Deze repository is uw toegangspoort tot de wereld van MLLM's. Het behandelt een breed scala aan onderwerpen, van multimodale instructie-afstemming tot ketenredenering en technieken voor hallucinatievermindering. Het is ook verbonden met het VITA-project, een open-source interactief multimodaal LLM-platform.
BELANGRIJKSTE KENMERKEN
Wie zou het moeten gebruiken?
Ontwikkelaars en onderzoekers die geïnteresseerd zijn in het bouwen van applicaties die verder gaan dan tekst, zoals ondertiteling van afbeeldingen, video-analyse of spraakgestuurde assistenten, zullen deze collectie uiterst nuttig vinden.
9. diepe snelheid
Microsoft/DeepSpeed, ontwikkeld door Microsoft, is een deep learning-optimalisatiebibliotheek die gedistribueerde training en inferentie eenvoudig en efficiënt maakt. Het integreert naadloos met PyTorch en heeft een belangrijke rol gespeeld bij de opleiding van een aantal van de wereldleiders's de grootste modellen, waaronder het Megatron-Turing-model met 530 miljard parameters.

Waarom het's een topkeuze
Bij DeepSpeed draait alles om schaalbaarheid en efficiëntie. Het biedt innovaties op systeemniveau waarmee u enorme modellen met miljarden parameters kunt trainen op beperkte hardware. De functies zijn essentieel voor iedereen die serieus bezig is met het trainen van state-of-the-art LLM's vanaf nul of het finetunen van grote LLM's.
BELANGRIJKSTE KENMERKEN
Wie zou het moeten gebruiken?
Dit is een tool voor serieuze professionals, datawetenschappers en onderzoekers die zeer grote taalmodellen moeten trainen of verfijnen. Als u met uw huidige configuratie tegen geheugenlimieten aanloopt, is DeepSpeed de oplossing.
10. lama.cpp
De ggml-org/llama.cpp-repository is een game-changer voor het uitvoeren van LLM's op consumentenhardware.'s een krachtige C/C++-bibliotheek voor het uitvoeren van inferentie op lokale machines, inclusief desktops en zelfs mobiele apparaten.'s is gebaseerd op de GGML tensor bibliotheek en staat bekend om zijn efficiëntie en minimale opzet.

Waarom het's een topkeuze
llama.cpp maakt krachtige LLM's voor iedereen toegankelijk. Je hebt geen enorme cloud-GPU-cluster nodig om te experimenteren met modellen zoals Lama 3, Mistral of GPT-2. De focus op CPU- en edge-apparaatprestaties heeft het gebruik van LLM gedemocratiseerd. Je kunt met slechts een paar opdrachten een lokale server opzetten en direct met modellen aan de slag gaan.
BELANGRIJKSTE KENMERKEN
Wie zou het moeten gebruiken?
Ontwikkelaars, hobbyisten en onderzoekers die lokaal LLM's willen uitvoeren en ermee willen experimenteren zonder afhankelijk te zijn van dure clouddiensten.'s ook perfect voor het bouwen op het apparaat AI toepassingen die privacy en lage latentie vooropstellen.
11. PaLM-rlhf-pytorch
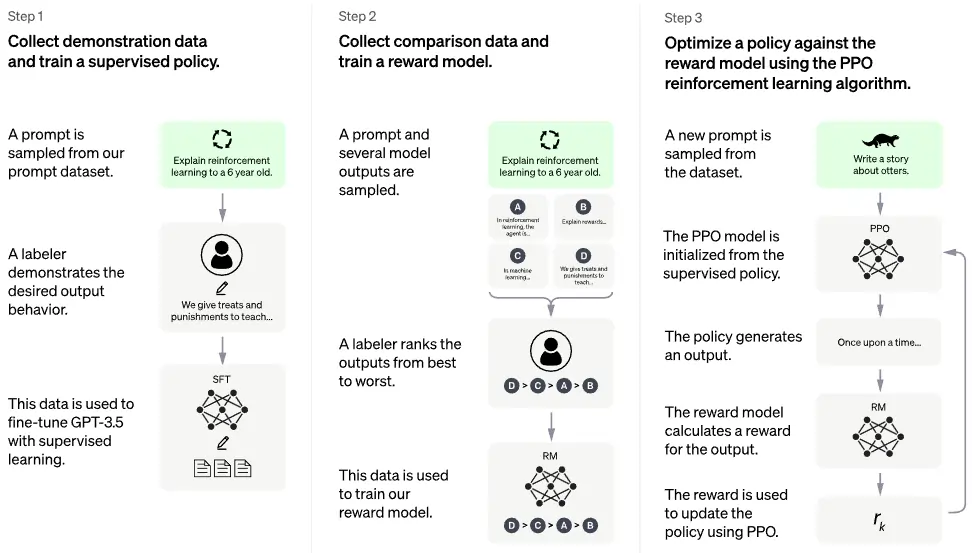
Reinforcement Learning met menselijke feedback (RLHF) is het geheime ingrediënt achter de indrukwekkende conversationele mogelijkheden van modellen zoals ChatGPT. De repository lucidrains/PaLM-rlhf-pytorch biedt een open-source-implementatie van RLHF toegepast op Google.'s PaLM-architectuur.
Waarom het's een topkeuze
Deze repository ontdoet een van de belangrijkste technieken in de moderne LLM-ontwikkeling van zijn geheimen. Het doel is om de functionaliteit van ChatGPT te repliceren met behulp van de PaLM-model, wat een concreet voorbeeld geeft van hoe RLHF kan worden geïmplementeerd. U kunt vooraf getrainde modellen laden of ze naar eigen wens aanpassen.
BELANGRIJKSTE KENMERKEN
Wie zou het moeten gebruiken?
Deze repository is bedoeld voor onderzoekers en ontwikkelaars die geïnteresseerd zijn in het fine-tuningproces, met name voor hen die RLHF willen begrijpen en implementeren om LLM's af te stemmen op menselijke voorkeuren.
12. nanoGPT
Karpathy/nanoGPT, ontwikkeld door de legendarische Andrej Karpathy, is de eenvoudigste en snelste repository voor het trainen en finetunen van middelgrote GPT's. De codebase is opzettelijk beknopt, met de kerntrainingslus in train.py en de modeldefinitie in model.py.
Waarom het's een topkeuze
nanoGPT geeft prioriteit aan eenvoud en educatieve waarde. Het ontdoet je van alle complexiteit van grote bibliotheken, zodat je de transformerarchitectuur vanaf de grond af kunt begrijpen. Ondanks de eenvoud,'s krachtig genoeg om resultaten op GPT-2-niveau te reproduceren en heeft andere minimalistische projecten geïnspireerd, zoals nanoVLM voor visie-taalmodellen.

BELANGRIJKSTE KENMERKEN
Wie zou het moeten gebruiken?
nanoGPT is ideaal voor studenten, docenten en ontwikkelaars die een diepgaande, fundamentele kennis van de GPT-architectuur willen. Als je genoeg hebt van black-box-bibliotheken en wilt zien hoe het echt werkt, dan is dit de plek voor jou.
Uw LLM-reis Begint met deze essentiële GitHub-repositories
Wat is het verschil tussen dromen over een LLM en ze daadwerkelijk opzetten? Deze 12 GitHub-repositories. Terwijl anderen over de theorie debatteren, heb je nu direct toegang tot de code die vandaag de dag wordt gebruikt's meest geavanceerd taalmodellen.
Uw concurrentievoordeel wacht op u:
- Kloon nanoGPT de basisprincipes van transformatoren begrijpen
- Vork llama.cpp voor lokale modelimplementatie
- Star llm-cursus voor gestructureerde leerpaden
- Draag bij aan DeepSpeed en word lid van Microsoft's optimalisatie inspanningen
Het LLM-veld beweegt snel -ontwikkelaars Wie deze opslagplaatsen vandaag beheerst, wordt morgen's AI architecten. Kies je 3 beste repositories, richt je ontwikkelomgeving in en begin met experimenteren. Elke commit, elke pull-request en elk model dat je traint, brengt je dichter bij LLM-meesterschap.



 BONUS: Ontvang onze $200 “AI “Mastery Toolkit” GRATIS wanneer u zich aanmeldt!
BONUS: Ontvang onze $200 “AI “Mastery Toolkit” GRATIS wanneer u zich aanmeldt!






