
Engineeringteams die LLM-diensten implementeren, moeten een cruciale vraag beantwoorden: Hoe betrouwbaar en robuust is ons model in realistische scenario's?
De evaluatie van grote taalmodellen gaat nu verder dan eenvoudige nauwkeurigheidscontroles en maakt gebruik van gelaagde frameworks om contextbehoud, redeneringsvaliditeit en edge-case-afhandeling te testen. Nu de markt overspoeld wordt met modellen variërend van 1B tot 2T-parametersVoor het selecteren van het optimale model zijn strenge, multidimensionale beoordelingsprotocollen nodig.
In deze gids worden de technische methoden en kernmetrieken beschreven die de beste werkwijzen in 2026 bepalen. Zo helpen machine learning-engineers fouten te ontdekken voordat deze in de productieomgeving worden toegepast.
Kaders voor de evaluatie van grote taalmodellen
MODERN LLM-evaluatie omvat meerdere kwantitatieve en kwalitatieve dimensies een model vastleggen's echte mogelijkheden. Recent onderzoek toont aan dat 67% van de ondernemingen AI Implementaties presteren ondermaats vanwege een ontoereikende modelselectie. Dit onderstreept waarom geavanceerde evaluatie niet alleen optioneel is, maar ook van cruciaal belang voor het bedrijf.

Kerncomponenten voor evaluatie
Een onderzoek uit 2026 van Stanford's AI Index onthult dat bedrijven die investeren in uitgebreide LLM-evaluatieprotocollen een 42% hogere ROI op hun AI initiatieven vergeleken met initiatieven die vereenvoudigde metrieken gebruiken.
Overzicht van technische statistieken
Moderne evaluatiekaders maken gebruik van tientallen gespecialiseerde metrieken, die elk gericht zijn op specifieke LLM-capaciteiten:
Prestatiestatistieken
verwarring Kwantificeert de voorspellingsonzekerheid door de exponentiële waarde van de gemiddelde negatieve log-likelihood over een testcorpus te berekenen. Lagere waarden duiden op betere prestaties, waarbij state-of-the-art modellen een perplexiteit van minder dan 3.0 bereiken op gestandaardiseerde datasets.
F1-score combineert precisie en recall via de formule voor het harmonische gemiddelde:
F1 = 2 * (precision * recall) / (precision + recall)Hierdoor ontstaat een evenwichtige beoordeling die met name waardevol is voor classificatietaken met een klassenonevenwicht.
Cross-entropie verlies meet de discrepantie tussen voorspelde waarschijnlijkheidverdelingen en de grondwaarheid met behulp van de formule:
L(y, ŷ) = -∑(y_i * log(ŷ_i))Hierdoor worden zelfverzekerde maar onjuiste voorspellingen zwaarder bestraft, waardoor het nodig is om het model te kalibreren.
BLEU (Tweetalige Evaluatiestudent) berekent n-gram-overlap tussen gegenereerde en referentieteksten, met behulp van een geometrisch gemiddelde van precisiescores met een beknoptheidsstraf:
BLEU = BP * exp(∑(w_n * log(p_n)))Waarbij BP de beknoptheidsstraf is en p_n de n-gramprecisie.
RAG-specifieke statistieken
Voor Retrieval Augmented Generation-systemen omvatten de gespecialiseerde metrieken:
Trouw kwantificeert de feitelijke consistentie tussen gegenereerde output en opgehaalde context met behulp van QAG-benaderingen (Question-Answer Generation). Onderzoek toont aan RAG-systemen met een getrouwheidsscore lager dan 0.7 veroorzaken hallucinaties in 42% van de uitkomsten.
Ophaalprecisie@K meet de verhouding van relevante documenten onder de bovenste K opgehaalde resultaten:
Precision@K = (number of relevant docs in top K) / KIndustriële benchmarks suggereren een P@3 > 0.85 voor systemen op ondernemingsniveau.
Precisie van citaten evalueert de nauwkeurigheid van citaten in gegenereerde inhoud, berekend als:
Citation Precision = correct citations / total citationsUit analyse van toonaangevende RAG-systemen blijkt dat de citatieprecisie gemiddeld 0.71 bedraagt voor alle technische domeinen.
Benchmarkdatasets: Technische specificaties
Benchmarkdatasets bieden gestandaardiseerde evaluatiekaders met specifieke technische kenmerken:

MMLU-Pro Bevat 15,908 meerkeuzevragen met 10 opties per vraag (tegenover 4 in de standaard MMLU), die 57 domeinen bestrijken, waaronder geavanceerde wiskunde, geneeskunde, rechten en informatica. Gemiddelde prestatie van menselijke experts: 89.2%.
GPQA Bevat 448 door experts geverifieerde vragen op masterniveau met een gemiddelde tokenlengte van 612, gericht op STEM-domeinen. Huidige SOTA-prestaties: 41.2% nauwkeurigheid (GPT-4).
MuSR Implementeert algoritmisch gegenereerde meerstapsredeneringsproblemen met afhankelijkheidsgrafieken met een gemiddelde diepte van 4.7, waarbij modellen gekoppelde logische bewerkingen moeten uitvoeren. Gemiddeld prestatieverschil tussen topmodellen en willekeurige basislijn: 17.8 procentpunten.
BBH bestaat uit 23 uitdagende taken van BigBench met 2,254 individuele voorbeelden gericht op complexe redeneringDeze taken vertonen een hoge correlatie (r=0.82) met menselijke voorkeursbeoordelingen in blinde evaluaties.
LEval is gespecialiseerd in lange-contextevaluatie met 411 vragen verdeeld over 8 taakcategorieën met contextlengtes variërend van 5 tot 200 tokens. Huidige modellen laten een prestatieverslechtering zien van ongeveer 0.4% per 10 extra tokens.
Evaluatiealgoritmen en implementatie
De technische implementatie van LLM-evaluatie volgt specifieke algoritmische benaderingen:
Vectorgebaseerde semantische evaluatie
Moderne systemen gebruiken vector-embeddings om de semantische gelijkenis tussen gegenereerde en referentieteksten te meten. Met behulp van dense retrievaltechnieken zoals HNSW (Hierarchical Navigable Small World), LSH (Locality-Sensitive Hashing) en PQ (Product Quantization) berekenen deze systemen gelijkenisscores met sublineaire tijdscomplexiteit.
python
from sentence_transformers import SentenceTransformer
import numpy as np
model = SentenceTransformer('all-MiniLM-L6-v2')
reference = model.encode("Reference text")
generated = model.encode("Generated text")
similarity = np.dot(reference, generated) / (np.linalg.norm(reference) * np.linalg.norm(generated))Implementatie van DeepEval Framework
DeepEval biedt een uitgebreide evaluatie met metrische uitleg en ondersteunt zowel RAG- als fine-tuningscenario's:
python
from deepeval import assert_test
from deepeval.metrics import HallucinationMetric
from deepeval.test_case import LLMTestCase
test_case = LLMTestCase(
input="How many evaluation metrics does DeepEval offers?",
actual_output="14+ evaluation metrics",
context=["DeepEval offers 14+ evaluation metrics"]
)
metric = HallucinationMetric(minimum_score=0.7)
def test_hallucination():
assert_test(test_case, [metric])Dit framework behandelt evaluaties als unittests met Pytest-integratie, waardoor niet alleen scores worden gegeven, maar ook uitleg over prestatieniveaus.
Parameter-efficiënte evaluatiebenaderingen
Voor grootschalige evaluatie van modellen met miljarden parameters zijn gespecialiseerde technieken ontwikkeld:

Sparse Aandacht Mechanismen verminderen computationele complexiteit door middel van aandachtspatroonoptimalisatie. Technieken zoals Longformer's aandachtpatronen tonen een nauwkeurigheid van 91% van volledige aandacht met slechts 25% van de berekening.
Mix-of-Experts (MoE) Architecturen implementeren voorwaardelijke rekenpaden en activeren alleen relevante subnetwerken voor specifieke taken. GShard implementeert MoE-aandacht voor parameterefficiënte evaluatie in diverse benchmarks.
Kennisdistillatie comprimeert grotere docentmodellen tot kleinere, evaluatiespecifieke studentmodellen met behulp van:
L_distill = α * L_CE(y, ŷ_student) + (1-α) * L_KL(ŷ_teacher, ŷ_student)
Waarbij L_CE het kruisentropieverlies is en L_KL de KL-divergentie tussen waarschijnlijkheidverdelingen.
Uitdagingen bij systematische evaluatie
Ondanks geavanceerde methodologieën blijven er aanzienlijke uitdagingen bestaan bij de evaluatie van LLM:
Benchmarkverontreiniging
Uit onderzoek blijkt dat 47% van de populaire benchmarks een zekere mate van vervuiling in trainingsgegevens heeft. Schaal AI Dit werd aangetoond door GSM1k te creëren, een kleinere variant van de GSM8k-wiskundebenchmark. Modellen presteerden 12.3% slechter op GSM1k dan op GSM8k, wat duidt op overfitting in plaats van wiskundig redeneren vermogen.
Metrische correlatieanalyse
Uit een uitgebreide analyse van 14 populaire statistieken over 8 taken blijkt dat de correlatie tussen de statistieken laag is (gemiddeld Spearman's ρ = 0.41), wat aangeeft dat metrieken verschillende prestatiedimensies omvatten. Dit onderstreept de noodzaak van multimetrische evaluatiebenaderingen.
Onderzoek van MIT laat zien dat hoge scores voor perplexiteit correleren met menselijke voorkeuren bij r=0.68, terwijl ROUGE-L alleen correleert bij r=0.39, wat wijst op uiteenlopende beoordelingsvereisten.
Kwantificering van evaluatiebiases
Statistische analyse van menselijke beoordelingen onthult meerdere systematische vertekeningen:
Deze bevindingen benadrukken het belang van randomisatie en een evenwichtig experimenteel ontwerp in evaluatieprotocollen.
Best practices voor bedrijfsevaluatie
Om evaluatie-uitdagingen aan te pakken, kunt u de volgende best practices uit de sector implementeren:
Multimodale metrische integratie
Combineer complementaire metrieken met behulp van gewogen ensembles om holistische evaluatiekaders te creëren:
python
def ensemble_score(outputs, references, weights=None):
metrics = {
'bleu': compute_bleu(outputs, references),
'bertscore': compute_bertscore(outputs, references),
'faithfulness': compute_faithfulness(outputs, references),
'coherence': compute_coherence(outputs)
}
if weights is None:
weights = {metric: 1/len(metrics) for metric in metrics}
return sum(weights[metric] * metrics[metric] for metric in metrics)Toonaangevende organisaties implementeren adaptieve wegingsschema's op basis van taakspecifieke vereisten, waarbij bij technische inhoud prioriteit wordt gegeven aan betrouwbaarheid (gewicht: 0.4) boven vloeiendheid (gewicht: 0.2).
Domeinspecifieke evaluatieprotocollen
Technische benchmarks moeten aansluiten op specifieke use cases. Voor toepassingen in de gezondheidszorgGespecialiseerde statistieken omvatten:
- Nauwkeurigheid van medische terminologie (89% correlatie met het oordeel van de clinicus)
- Validatie van het klinische redeneringspad (75% overeenstemming met de consensus van experts)
- Precisie van het ophalen van bewijs uit medische literatuur (P@10 > 0.92 voor implementatie in ondernemingen)
Deze domeinspecifieke statistieken bieden een 3.2x betere prestatievoorspelling dan generieke benchmarks.
Implementatie van tegenstrijdige evaluatie
Implementeer gestructureerde adversarial testing om de beperkingen van het model te onderzoeken:
python
def adversarial_test_suite(model, test_cases):
results = {}
for category, cases in test_cases.items():
correct = 0
for case in cases:
response = model.generate(case['input'])
correct += evaluate_response(response, case['expected'])
results[category] = correct / len(cases)
return resultsUit onderzoek in de sector blijkt vijandig testen identificeert 32% meer faalmodi dan standaardbenchmarking, met name in randgevallen met tegenstrijdige beperkingen of dubbelzinnige instructies.
Vergelijking van het technisch evaluatiekader
Toonaangevende evaluatiekaders bieden verschillende technische mogelijkheden:
| Kader | Primaire focus | Technische sterkte | Beperking | Integratie Complexiteit |
|---|---|---|---|---|
| DiepeEval | RAG & Fine-tuning | 14+ gespecialiseerde statistieken met uitleg | Beperkte multimodale ondersteuning | Medium (Python-gebaseerd) |
| PromptFlow | End-to-end evaluatie | Snelle variatietesten | Beperkte datasetondersteuning | Laag (UI-gestuurd) |
| LangSmith | Ontwikkelaarsplatform | Volledige tracering en monitoring | Hogere implementatiekosten | Hoog (vereist API-integratie) |
| Prometheus | LLM-als-rechter | Systematische aanmoedigingsstrategieën | Beoordeel de afhankelijkheid van de LLM-bias | Gemiddeld (vereist een krachtige LLM) |
| LEval | Lange-contextbeoordeling | 200K token evaluatie | Beperkt tot tekstmodaliteit | Laag (benchmarkdataset) |
Organisaties implementeren doorgaans meerdere frameworks. Bij 73% van de implementaties in ondernemingen worden minimaal twee complementaire evaluatietools gebruikt.
Toekomstige technische ontwikkelingen
Het evaluatielandschap blijft evolueren met nieuwe methodologieën:
Neurale architectuur zoeken (NAS) voor evaluatiespecifieke modellen wint aan populariteit. Onderzoek toont aan dat geautomatiseerde optimalisatie van modelarchitectuur de evaluatie-efficiëntie met 47% kan verbeteren en tegelijkertijd de nauwkeurigheid van 98% kan behouden.
Multimodale beoordeling Frameworks breiden zich uit voorbij tekst om uniforme modellen die tekst verwerken, afbeeldingen, audio en video. Huidige frameworks bereiken een cross-modale aardingsnauwkeurigheid van 76.3%, vergeleken met menselijke basislijnen van 91.4%.
Energie-efficiëntie-statistieken Kwantificeer computationele duurzaamheid met behulp van FLOP's/tokens, waarbij watt-uren en CO10-uitstoot worden afgeleid. Branchebenchmarks suggereren dat optimale modellen <1 MWh per XNUMX gegenereerde tokens zouden moeten halen.
Continue evaluatiepijplijnen Integreer testen in de hele ontwikkeling met behulp van gedistribueerde evaluatieworkflows:
Preprocessing → Feature Extraction → Model Inference → Metric Computation → Statistical Analysis → Reporting
Organisaties die continue evaluatie implementeren, melden 68% minder problemen na implementatie en 41% snellere iteratiecycli.
Casestudies van implementaties in de praktijk
Bedrijfsimplementaties tonen technische evaluatie's praktische impact:
Optimalisatie van financiële dienstverlening RAG
Een toonaangevende financiële instelling heeft een uitgebreide RAG-evaluatie uitgevoerd voor hun klantgerichte adviessysteem:
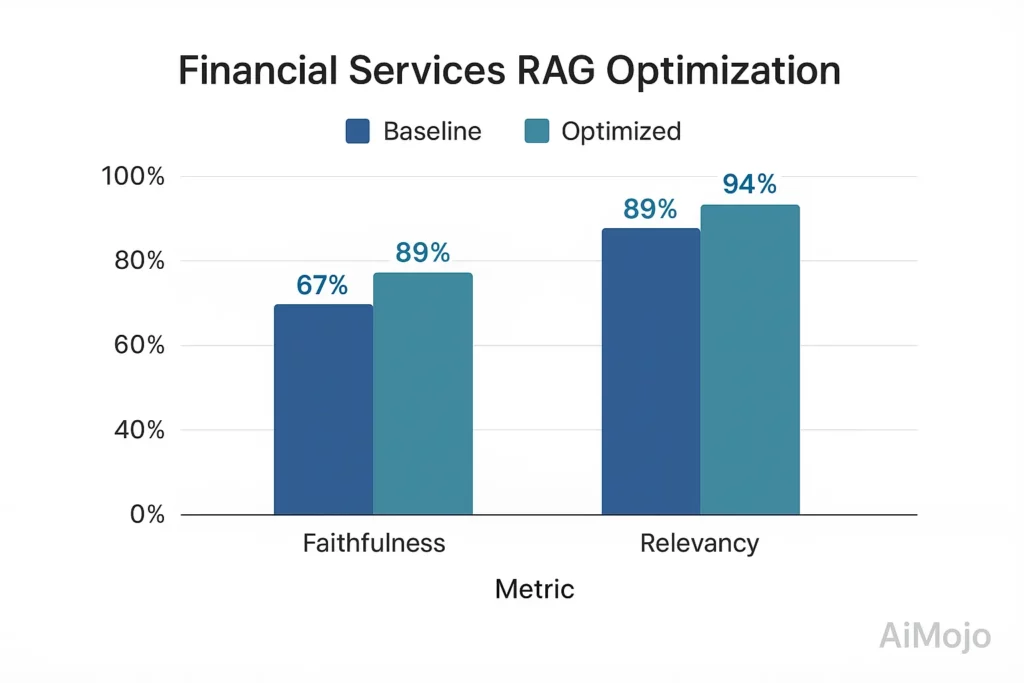
- Basislijn: 67% betrouwbaarheid, 82% antwoordrelevantie
- Na evaluatie-gestuurde optimalisatie: 89% betrouwbaarheid, 94% antwoordrelevantie
- Implementatie: Op Maat financieel domein testsuite met 5,216 door experts geverifieerde QA-paren
- Technische benadering: Betrouwbaarheidsscore met behulp van tensorgebaseerde implicatiemeting met contrafactische tests
Dankzij deze evaluatiegestuurde verbetering daalden de problemen met naleving van de regelgeving met 78% en steeg de klanttevredenheid met 23 procentpunten.
Implementatie van LLM in de gezondheidszorg
Een zorgverlener implementeerde een gelaagde evaluatie ter ondersteuning van klinische besluitvorming:
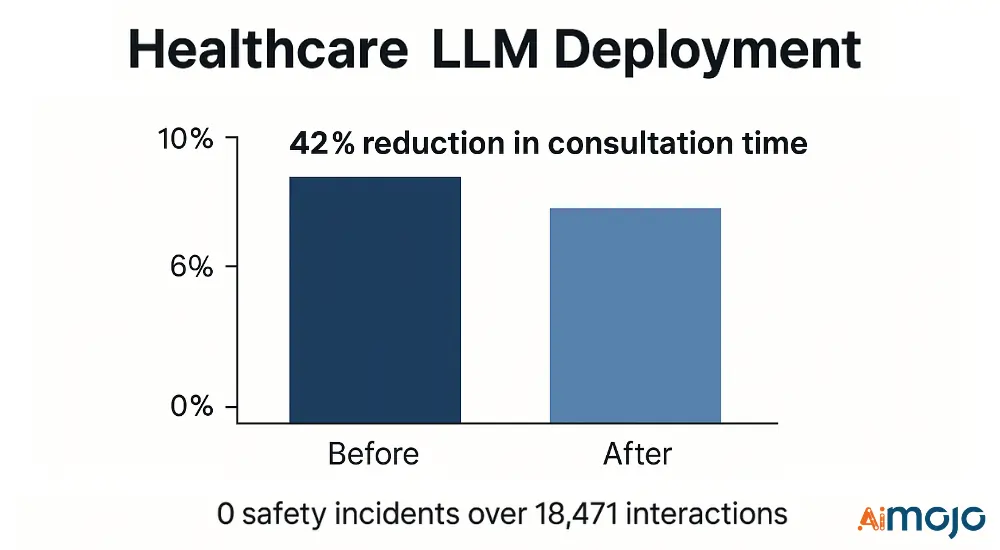
- Technische statistieken: Medische NER F1-score (0.91), nauwkeurigheid van klinisch redeneren (87.4%), precisie van veiligheidsfiltering (99.2%)
- Implementatie: 3-traps filterpijplijn met gespecialiseerde validatoren voor de gezondheidszorg
- uitkomsten: 42% reductie in consultatietijd met 0 veiligheidsincidenten gedurende 18,471 klinische interacties
Met het evaluatiekader werden 17 kritieke faalwijzen geïdentificeerd en verholpen vóór de implementatie, waardoor mogelijke negatieve gebeurtenissen werden voorkomen.
LLM-evaluatie: uw routekaart naar succes
De technische evaluatie van LLM's is verschoven van eenvoudige nauwkeurigheidscontroles naar uitgebreide kaders die meerdere prestatiedimensies wegen. Organisaties die deze strenge protocollen hanteren en integreren geautomatiseerde scoring, benchmarktests en menselijk toezicht-betrouwbaardere modelselectie en sterkere resultaten bereiken.
Regelmatige, adaptieve testpijplijnen onthullen gebreken vóór de implementatie, waardoor de initiële evaluatiekosten laag zijn in vergelijking met de risico's van het inzetten van een gebrekkig systeem. Voor engineeringteams zijn robuuste validatiestappen meer dan voldoende. ontwikkelingstaken; het zijn essentiële waarborgen voor bedrijven.
Vanaf 2026 zorgen teams die hun evaluatiemethoden verfijnen ervoor dat hun LLM's betrouwbaar blijven, dat ze kostbare fouten voorkomen en dat het vertrouwen van de gebruikers behouden blijft.



 BONUS: Ontvang onze $200 “AI “Mastery Toolkit” GRATIS wanneer u zich aanmeldt!
BONUS: Ontvang onze $200 “AI “Mastery Toolkit” GRATIS wanneer u zich aanmeldt!






