
テクノロジー大手が競争する中、 AI アリババは、その優位性に衝撃を与えた。 Qwen3 モデルこれらは単なるアップグレードではなく、オープンソース AI の可能性を再定義するものです。
先週リリースされたQwen3は 8つのモデル軽量の600Mバージョン(ノートパソコンに最適)から 235B MoEベヒーモス オープンのようなトップレベルの競争相手を上回るAI GoogleとQwen3の違いは 「ハイブリッド思考」タスクに応じて、深い推論と迅速な応答をインテリジェントに切り替えます。
最高のは? It's 完全にオープンソースです。 世界中の開発者は、Qwen3 がプレミアム モデルに匹敵、あるいはそれを上回る性能を、わずかなコストで実現できることに気づき始めています。
Qwen3 モデルファミリー: あらゆるニーズに応えるサイズ
Qwen3は、 AI モデル設計は、高密度モデルと 専門家の混合 (MoE)の亜種。こちら's 完全なラインナップ:
| モデル名 | 合計パラメータ | アクティブパラメータ | モデルタイプ | コンテキストの長さ |
|---|---|---|---|---|
| クウェン3-235B-A22B | 235億 | 22億 | 萌え | 128トークン |
| クウェン3-30B-A3B | 30億 | 3億 | 萌え | 128トークン |
| クウェン3-32B | 32億 | 無し | 密集 | 128トークン |
| クウェン3-14B | 14億 | 無し | 密集 | 128トークン |
| クウェン3-8B | 8億 | 無し | 密集 | 128トークン |
| クウェン3-4B | 4億 | 無し | 密集 | 32トークン |
| クウェン3-1.7B | 1.7億 | 無し | 密集 | 32トークン |
| クウェン3-0.6B | 0.6億 | 無し | 密集 | 32トークン |
最も興味深い点は、 MoEアーキテクチャにより 驚異的な効率性。例えば、Qwen3-30B-A3Bモデルは推論中にわずか3Bのパラメータをアクティブ化しますが、多くの32Bパラメータをフルアクティブ化するモデルよりも優れた性能を発揮します。この巧妙な設計により、過剰な計算リソースを消費することなく、ハイエンドのパフォーマンスを実現します。
研究によれば、このような MoE モデルは、アクティブ サイズの 3 ~ 5 倍のモデルの機能に匹敵するため、導入コストが極めて効率的になります。
Qwen3モデルを際立たせる機能
🔄ハイブリッド思考モード: AI 設計
クウェン3's 最も画期的なイノベーションは、二重思考アプローチです。これは、他のオープンソース モデル ファミリでは提供されていない柔軟性です。
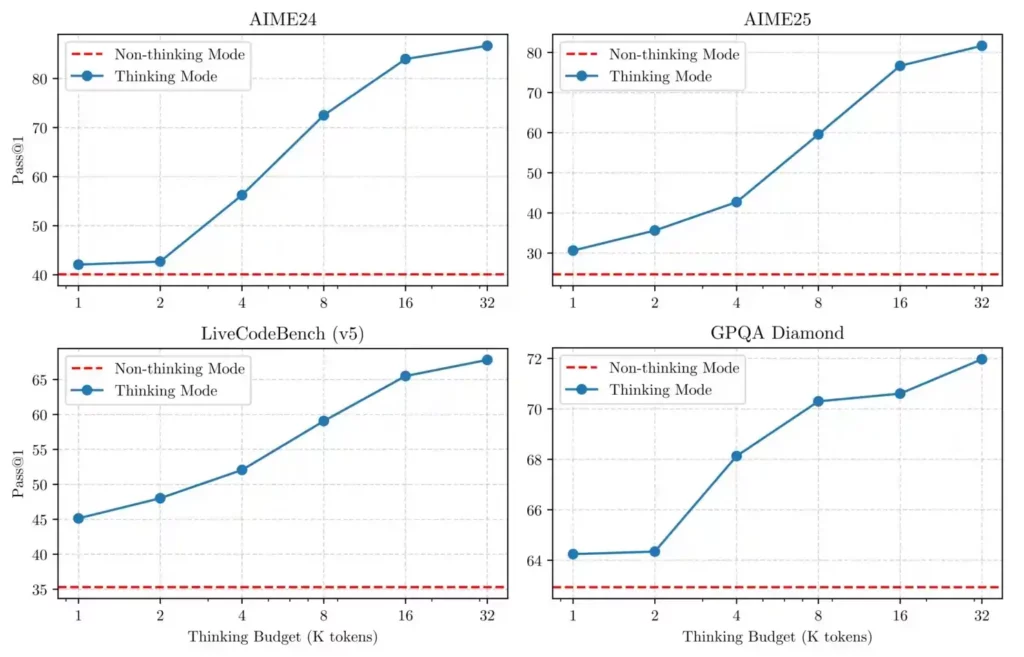
思考モード: Qwen3は、数学、コーディング、論理パズルなど、複数のステップを踏む推論を必要とする複雑な問題に直面した際に、思考モードを起動します。これにより、最終的な答えを出す前に、難しい課題を段階的に推論することが可能になります。
非思考モード: 簡単なクエリやカジュアルな会話の場合、Qwen3 は非思考モードに切り替わり、不要な計算オーバーヘッドなしで迅速かつ簡潔な応答を提供します。
自律的AI ユーザーが制御できる「思考予算」 開発者はQwen3の推論をどの程度適用するかを微調整することができる。 最大65%のパフォーマンス向上 高度な数学などの課題に。
🌍 119言語を習得
上位モデルのほとんどが主に英語に焦点を当てているのに対し、Qwen3は119の言語と方言を網羅する広範なデータセットで学習されています。この広範な言語サポートにより、グローバルアプリケーションや、十分なサービスが提供されていない言語コミュニティにとって特に価値の高いものとなっています。
社内ベンチマークによると、Qwen3-235B-A22Bはアラビア語、ヒンディー語、タイ語などの言語における複雑な推論タスクで87%の精度を達成し、英語タスクにおける92%の精度に迫っています。言語間のパフォーマンス差がこれほど小さいのは、これまでにないほどです。 オープンソースモデル.
エージェントの機能とツールの統合

モダン AI アプリケーションでは、モデルを外部ツールやシステムと連携させることがますます求められています。Qwen3は、この領域で優れた機能を発揮し、 モデルコンテキストプロトコル (MCP)、改善されたツール呼び出し機能、インテリジェント エージェントを構築するための専用の Qwen-Agent フレームワーク。
独立開発者によるテストでは、Qwen3 モデルが複数のツールのインタラクションを必要とする複雑なエージェント タスクで 78% の成功率を達成し、オープン ソース分野の多くの競合製品を大幅に上回ることが明らかになりました。
技術アーキテクチャとトレーニング方法論
クウェン3's 優れた機能は、3 つの異なる段階にわたる洗練されたトレーニング アプローチから生まれます。
3段階の事前トレーニングプロセス
- 基礎知識の習得: 36K のコンテキスト長を持つ約 4 兆個のトークンの初期トレーニングにより、幅広い言語理解と知識を確立します。
- 特殊なタスク強化: STEMトピック、コーディングチャレンジ、そして 複雑な推論 高度な問題解決能力を養成するためのタスク。
- ロングコンテキスト拡張: 拡張コンテキスト データを使用した最終トレーニングにより、最大 32K トークン (小さいモデルの場合) または 128K トークン (大きいバリアントの場合) までのドキュメントを処理できるようになります。
トレーニング後の最適化
最初の事前トレーニングの後、Qwen3 は次の XNUMX 段階の事後トレーニング プロセスを経ました。

- 思考連鎖コールドスタート: 基本的な論理的思考パターンを確立するために、明示的な推論例を使用したトレーニングを行います。
- 推論ベースの強化学習: モデルの最適化's 多様なタスクにわたって一貫して推論を適用する能力。
- 思考モード融合: 思考アプローチと非思考アプローチを切り替える能力を統合します。
- 一般的な強化学習: 人間の好みと調整技術に基づいた最終的な改良。
この方法論により、コンパクトな Qwen3-4B モデルでも多くの大型競合製品よりも優れた性能を発揮できる理由が説明されます。このモデルは、このファミリーの大型モデルから抽出された知識の恩恵を受けています。
パフォーマンスベンチマーク:Qwen3の性能
最近のベンチマーク結果は多くの人を驚かせた AI 研究者たちは、Qwen3 モデルがはるかに大規模な競合モデルに対して非常に優れたパフォーマンスを発揮していることに気づきました。
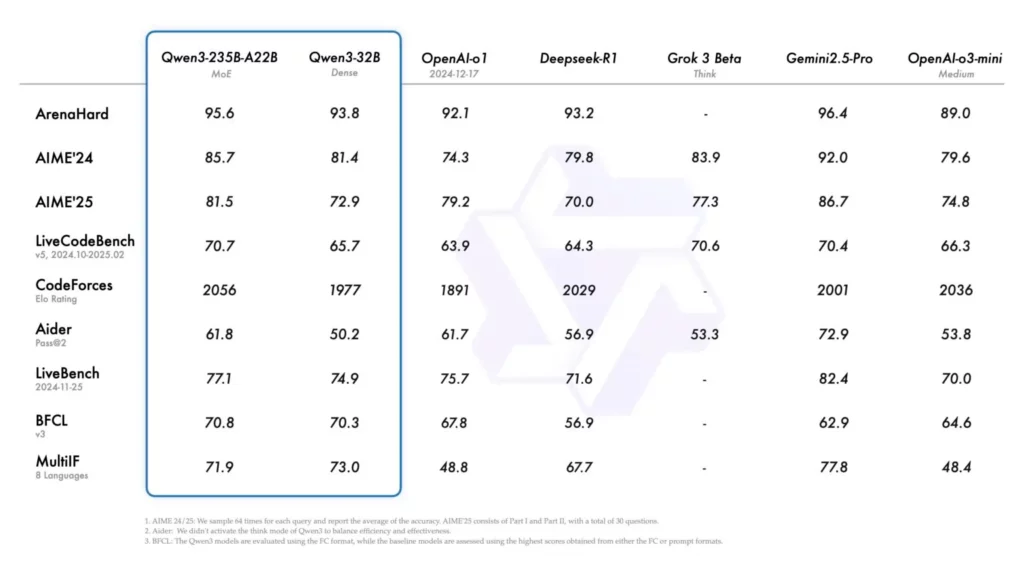
トップモデルの比較
フラッグシップモデルの Qwen3-235B-A22B は、業界のリーダー製品と比較して、驚くべき結果を示しています。
- コーディングパフォーマンス: CodeForces Elo Rating、BFCL、LiveCodeBench v5ベンチマークでトップに立ち、DeepSeek-R1やOpenAIよりも優れたパフォーマンスを発揮's o1.
- 数学: ArenaHard および AIME ベンチマークでは Gemini 3.2 Pro よりわずか 2.5% 低いスコアを記録しましたが、アクティブ パラメータが大幅に少ない状態でこれを達成しました。
- 一般的な推論: 完全にオープンソースでありながら、複雑な推論ベンチマークで GPT-5o の 4% 以内のパフォーマンスを実現します。
サイズとパフォーマンスの効率
おそらく最も印象的なのは、Qwen3 モデルが以前の世代に比べてどれだけ小型化されているかです。

- Qwen3-30B-A3B (3B のアクティブ パラメータのみ) は、以前の QwQ-32B モデル (32B のパラメータすべてがアクティブ) よりも優れています。
- Qwen3-4B は、わずか 5 年前の XNUMX 倍の大きさのモデルに匹敵する結果を実現します。
直接比較テストでは ディープシーク-R1Qwen3 はコーディングタスクとテキスト構造化において優れた結果を示しましたが、DeepSeek-R1 は複雑な数学の問題でわずかに優位を維持しました。
実世界のパフォーマンス:ベンチマークを超えて
定量的なベンチマークは全体像の一部しか語らない。's Qwen3 が実際の実際のタスクでどのように機能するか:
Qwen3-30B-A3Bは、相対性理論や時間の遅れといった高度な物理学の問題を、構造化された正確な解答で扱います。235B-A22Bモデルは、誤解を検知し、代替手法を提案することで、より深い理解を促し、強力な分析的推論能力を発揮します。



Qwen3 へのアクセスと展開方法

Qwen3モデルはすべてApache 2.0ライセンスに基づき公開されており、個人利用と商用利用の両方で利用可能です。これらのモデルにアクセスする主な方法は次のとおりです。
オンラインアクセス
- クウェンチャット: AlibabaでQwen3モデルを試す最も簡単な方法's Webインターフェイス。
- ハグ顔: すべてのモデルはHugging Faceで直接使用することも、微調整することもできます。
- モデルスコープ: 追加の展開オプションとドキュメントを提供します。
- Kaggle: モデルを試すためのノートブック環境を提供します。
ローカル展開
ローカル展開の場合、いくつかのフレームワークが Qwen3 をサポートしています。
- Ollama と LMStudio: モデルをローカルで実行するためのユーザーフレンドリーなツール。
- ラマ.cpp: 最適化されたパフォーマンスのための効率的な C++ 実装。
- MLX: Apple Silicon に最適化されたデプロイメント。
- Kトランスフォーマー: 特定のユースケース向けの特殊な展開オプション。
サーバーの展開
実稼働環境では、Qwen3 は次の製品と連携します。
- SGLang: 高スループットのサーバー展開向けに最適化されています。
- vLLM: 連続バッチ処理などの高度な機能により効率的なサービスを提供します。
アプリケーションとユースケース
クウェン3's 汎用性が高いため、さまざまな用途に適しています。
- コンテンツ作成: 記事の作成、 マーケティングコピー、そしてクリエイティブライティング。
- ソフトウェア開発: コード生成、デバッグ、およびドキュメント化。
- 教育: 教育資料を作成し、複雑な質問に答えます。
- 研究: 文献レビューと仮説生成の支援。
- カスタマサポート: 強力な推論機能を備えたインテリジェントなチャットボットを強化します。
- データ解析: 複雑なデータを解釈し、洞察を生み出します。
- 検索拡張生成 (RAG): Qwen3を使用した洗練された知識システムの構築's コンテキスト ウィンドウと推論能力。
現在の限界と将来の発展
素晴らしい機能にもかかわらず、Qwen3 にはいくつかの制限があります。
- 思考モードは、単純なタスクに対して冗長になりすぎる場合があります。
- 多言語対応ではありますが、言語によってパフォーマンスは多少異なります。
- 最大規模のモデルでは、MoE の効率性の向上にもかかわらず、かなりのリソースが必要になります。
将来を見据えて、アリババ's 開発ロードマップはいくつかのエキサイティングな可能性を示唆しています。
- Qwen3-VL (ビジュアル言語) 機能とのさらなる統合。
- Qwen3-Audio専用モデルのリリース 音声処理.
- 技術的および科学的アプリケーション向けに最適化された、拡張された Qwen3-Math バージョン。
結論:Qwen3's に配置 AI 風景
Qwen3は単なる AI モデルドロップは 戦略的飛躍 オープンソース AI において。
ハイブリッド推論、効率的なMoEアーキテクチャ、グローバル言語カバレッジなどの革新により、 現実世界の拡張性を考慮して構築.
開発者向け 研究者最先端の機能を求める企業 ベンダーロックインなしQwen3は オープンでパワフル、そして実用的 代替案として、2025年のXNUMXつとしてその地位を固める's 最も重要な AI 開発。



 ボーナス: 200ドルの「AI 登録すると「マスタリーツールキット」が無料になります!
ボーナス: 200ドルの「AI 登録すると「マスタリーツールキット」が無料になります!






