爬行4AI 重要見解
Crawl4AI是什麼?
Crawl4AI 是一個免費的開源 Python 函式庫,可以將網頁轉換為大型語言模型可以直接使用的簡潔 Markdown、結構化的 JSON 或經過過濾的 HTML。它基於 Playwright 構建,用於瀏覽器自動化,服務構建 RAG 管道的開發者。 AI 該工具支援代理和自動化資料工作流程,同時支援基於 LLM 和不基於 LLM 的資料提取策略,使團隊能夠全面控製成本和輸出品質。
Crawl4 在 GitHub 上擁有超過 60,000 萬顆星,每月在 PyPI 上的下載量超過 900,000 萬次。AI 已成為最受歡迎的網路爬蟲工具之一 AI 工程社區。它完全運行在您自己的基礎設施上,因此無需 API 金鑰,也沒有按頁收費。適用於需要生產規模資料擷取的團隊。 業務自動化,Crawl4AI 它提供了與任何 LLM 提供者整合的靈活性,同時保持爬取層完全免費。
爬行4AI Markdown 產生兩種類型的輸出,其官方網站對此有詳細描述。 Clean Markdown 保留了頁面的正確格式,包括標題、表格、程式碼區塊和引用提示。 Fit Markdown 則應用基於啟發式的過濾方法,透過剪枝演算法或 BM25 相關性評分來去除樣板代碼、導航和頁腳等冗餘資訊。
這種雙輸出設計專為 RAG 管道和直接 LLM 攝取而設計。用戶還可以建立自訂輸出。 Markdown 生成 制定符合其具體管道需求的策略。
該工具提供兩種不同的提取路徑。對於佈局可預測的頁面,基於 CSS 和 XPath 的 JsonCssExtractionStrategy 會使用模式定義提取結構化的 JSON,並且無需呼叫任何 LLM。
對於複雜或不可預測的頁面,LLMExtractionStrategy 可連接到任何 LLM 提供者(OpenAI、Ollama、DeepSeek 等),並使用 Pydantic schemas 傳回結構完美的資料。分塊策略(包括主題、正規表示式和句子層級處理)可有效率地處理大型頁面。
自適應爬蟲作為crawl4ai.com網站上的旗艦功能發布,它使用資訊搜尋演算法,並採用三層評分系統來衡量覆蓋率、一致性和飽和度。它並非抓取網站上的每個頁面,而是評估… 內容相關性 每一步都會自動停止,當達到置信度閾值時自動停止。
它同時支援統計策略(快速、免費、基於詞項)和嵌入策略(基於查詢擴展的語義理解)。這可以防止過度爬取,並顯著節省計算資源。
在 v0.8.5 版本中引入的三層結構 反機器人檢測系統 它會檢查已知的供應商簽名、通用阻止指示器以及返回頁面的結構完整性。當偵測到封鎖時,系統會自動透過可設定的代理鏈進行重試,並使用備用獲取函數。結合模擬真實使用者行為的隱身模式和 v0.7.3 版本中的不被偵測到的瀏覽器模式,Crawl4 具備了這些功能。AI 一套強大的工具包,用於訪問受保護的網站。
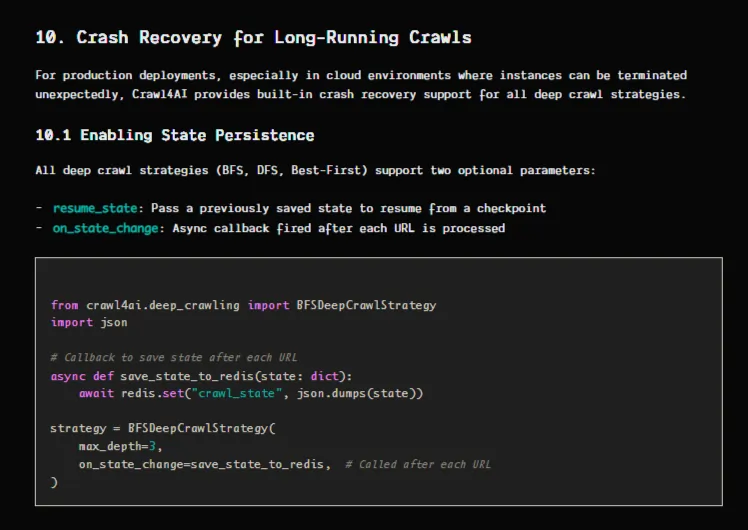
對於跨越數千頁的大規模作業,深度爬取策略(BFS、DFS、最佳優先)在 v0.8.0 版本中內建了崩潰復原功能。 on_state_change 回呼函數會在每個 URL 之後儲存狀態,而 resume_state 參數可讓您在失敗後從確切的檢查點繼續執行。
預取模式完全跳過 Markdown 產生和擷取,讓兩階段爬取工作流程的 URL 發現速度達到正常速度的 5 到 10 倍。
爬行4AI 它提供了一個優化的 Docker 映像,其中包含 FastAPI 伺服器、JWT 令牌認證、具有即時系統指標的即時監控儀表板,以及一個支援頁面預熱的三層瀏覽器池(永久、熱、冷)。互動式環境允許團隊測試爬蟲配置並產生請求程式碼,而無需編寫腳本。
MCP整合直接連接到 AI 類似 Claude Code 的工具。支援多架構,並可自動偵測 AMD64 和 ARM64,確保可在任何雲端服務供應商上運作。
爬行4AI 定價計劃
| 計劃名稱 | 價格 | 關鍵細節 |
|---|---|---|
| 開源(自架) | $0 | 無限次爬取,功能齊全,您只需提供基礎設施。 |
| 雲端 API(封閉測試版) | 定制配框 | 託管服務,申請優先體驗,名額有限。 |
| 信徒贊助商 | $ 5 /月 | 社區支持層級,並支持該項目 |
| 建設者贊助商 | $ 50 /月 | 優先支援和新功能搶先體驗 |
| 團隊贊助商 | $ 500 /月 | 每兩週同步和優化指導 |
| 數據基礎設施合作夥伴 | $ 2,000 /月 | 全力支持和全面合作 |
如何 Crawl4AI 是否支援 Markdown 產生?
爬行4AI 產生兩種類型的 Markdown 輸出。原始 Markdown 保留完整的頁面結構,包括導航元素和頁腳。擬合 Markdown 應用啟發式過濾,使用剪枝演算法或 BM25 相關性評分來去除噪聲,僅保留核心內容。這對於 RAG 流程尤其重要,因為嵌入品質取決於乾淨的輸入文字。
您也可以透過擴充基底類別來實作自訂 Markdown 產生策略,從而完全控制 HTML 元素如何對應到 Markdown 標記。引用系統會將頁面連結轉換為編號參考文獻,這有助於 LLM 在檢索任務期間追蹤來源歸屬。
利與弊
- 擁有超過 60,000 萬名活躍用戶的社群。
- Apache 2.0 寬鬆許可證。
- 適用於任何法學碩士(LLM)提供者。
- 採用非同步架構以提高速度。
- 內建深度爬取崩潰復原功能。
- 目前尚未提供託管雲端服務。
- 沒有圖形使用者介面或可視介面。
- 反機器人程式需要設定代理。

