一同 AI 重要见解
什么是 Together AI?
一起人工智能 是一个全栈 AI 这是一个专为需要快速、经济高效地访问开源大型语言模型的开发者和机器学习工程师打造的云平台。该平台成立于 2020 年,提供无服务器推理、模型微调、专用 GPU 端点和按需 GPU 集群等一站式服务。它支持来自 Llama 4、DeepSeek V3、Qwen 3.5、Mistral 和 FLUX(用于图像生成)等系列的 200 多个模型。
一同 AI 减轻了管理 GPU 基础设施的负担,使团队能够专注于构建。 AI 原生应用程序。它是开放的AI 兼容的 API 意味着现有代码库只需进行极少的更改即可迁移。对于希望运行高容量业务的企业而言,这一点尤为重要。 AI 以远低于专有 API 的成本实现工作负载,共同 AI 作为一家生产级推理和训练提供商,它占据着强大的市场地位。
一同 AI 接待超过 200 名 开源模型 该平台涵盖文本、图像、视频、音频、嵌入和代码生成等多种数据类型。开发者可以通过单一 API 调用任何模型,无需配置服务器。例如,Llama 4 Maverick 等模型的运行成本约为每百万输入令牌 0.27 美元,这使得高容量生产工作负载的成本远低于专有替代方案。此外,该平台还包含一个批量 API,用于以更低的成本处理非紧急任务。
Together AI 的专有推理引擎采用 FlashAttention 3 和 ATLAS 推测器系统,推理速度比标准实现快 3.5 倍。在 NVIDIA H100 硬件上,该引擎在 BF16 精度下可达到约 840 TFLOPs/s 的运算速度。实际生产环境中,其运算速度约为每秒 400 个 token,比 GPT 4 Turbo 的输出速度快约 2.5 到 4 倍。
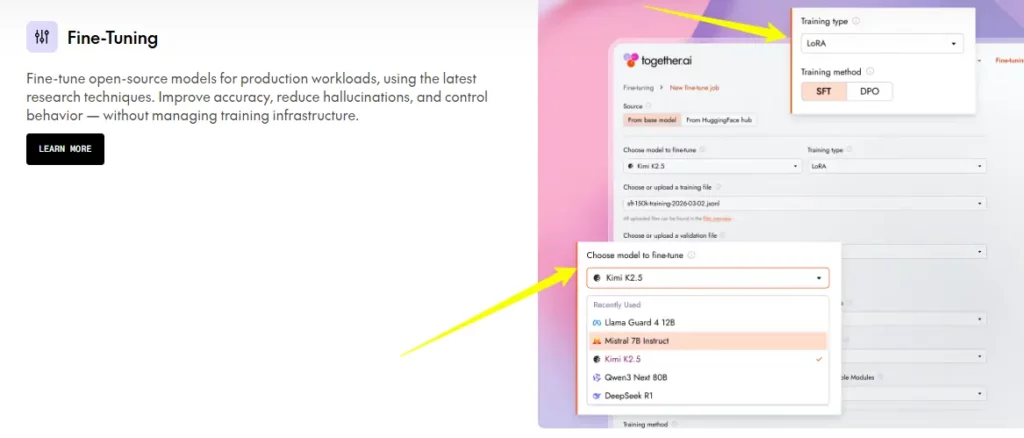
该平台支持 LoRA(低秩自适应)和全权重微调,模型参数上限为 100 亿。LoRA 定价为每百万代币 0.48 美元起,模型参数上限为 16 亿。团队可以使用专有数据训练模型,为法律、医疗或其他特定领域创建任务专用系统。 客户支持应用程序 然后立即将它们部署到 Together AI 的推理堆栈上。
对于需要专用计算的团队来说,Together AI 可即时访问 NVIDIA H100、H200、B200 以及最新的 GB200 和 GB300 NVL72 机架。按需付费价格从每小时 3.49 美元起(H100 节点),长期预留价格可降至每小时 2.55 美元。这使其成为 AWS、GCP 或 Azure 之外的机器学习训练工作负载的有力替代方案。
从 OpenAI 的 API 迁移到 Together AI 只需更改基本 URL。该平台还提供了一个代码解释器来执行以下命令。 LLM生成的代码 在沙盒环境中,每次会话收费 0.03 美元;此外,还提供完整的代码沙盒,用于更大的开发环境,按 vCPU 小时计费。
一同 AI 定价计划
| 租赁计划 | Cost | 特点 |
|---|---|---|
| 无服务器推理 | 每百万代币0.02美元至7.00美元 | 因模型而异。输出代币的成本高于输入代币。 |
| 专用端点 | 每小时 3.99 美元起 | 单租户 GPU,性能有保障 |
| GPU集群(按需) | $ 3.49 /小时 | 按小时计费,无需长期合约 |
| GPU集群(预留) | 每小时 2.55 美元至 7.15 美元 | 1周至6个月以上的付款期限,批量购买可享折扣 |
| 微调(LoRA) | 每百万代币0.48美元至2.90美元 | 根据模型尺寸(最高 100B) |
| 微调(完整版) | 每百万代币0.54美元至3.20美元 | 所有权重已更新 |
| 代码解释器 | 每节$ 0.03 | 沙盒代码执行 |
| 共享文件系统 | 每 GiB/月 0.16 美元 | 高带宽并行存储 |
一同 AI 研究和开源贡献
一同 AI 不仅仅是一家基础设施提供商。该公司积极推动 AI 该团队的研究取得了长足进步。他们开发了 FlashAttention,如今已成为业界通用的标准注意力机制。其他贡献包括混合代理(Mixture of Agents)、Red Pajama 开放数据集、DeepCoder 和开放数据科学家代理(Open Data Scientist Agent)。
这种以研究为先的方法意味着最新的 优化技术 从平台上线之日起,各种模型架构即可使用。对于重视模型性能前沿性的工程团队而言,这一持续的研究流程提供了强大的支持。 AI 这是纯粹的云计算经销商根本无法匹敌的技术优势。
利与弊
- 提供 200 多个开源模型。
- 业界领先的推理速度。
- 可选AI 兼容的API迁移。
- 灵活的GPU集群选项。
- 强大的微调支持。
- 有效 AI 研究贡献
- 没有永久的免费套餐。
- 仅限开发者使用,不适合新手。
- 成本预测可能很困难。


