烟花爆竹 AI 重要见解
什么是烟火人工智能?
烟花人工智能 是一个高性能推理平台,专为需要运行、微调和扩展开源程序的开发者和企业而构建。 AI 以生产级速度运行模型。该平台由 Meta 的前 PyTorch 团队成员创立,提供开放的AI 兼容的 API,可访问 100 多个流行的大型语言模型、视觉模型和图像生成模型。
烟花爆竹 AI Fireworks 提供无服务器和按需部署选项,从而消除了管理 GPU 基础设施的运维负担。企业都在使用 Fireworks。 AI 为聊天机器人提供动力, 编码助手搜索引擎和代理 AI 工作流程。其自主开发的推理引擎可提供比标准开源服务栈高出 4 倍的吞吐量和低 50% 的延迟,使其成为速度最快的服务栈之一。 AI 目前可用于生成式编程的 API 提供商 AI 生产工作负载。
Fireworks AI 的专有推理引擎从一开始就以速度为核心构建。它在各种模型规模下都能始终如一地实现低于 100 毫秒的首令牌延迟。对于任何需要实时响应的应用,例如面向客户的聊天机器人或 代理编码助手这种性能优势是可衡量的,而且非常显著。Sourcegraph 和 Notion 等公司都公开表示,迁移到该平台后,吞吐量得到了提升。
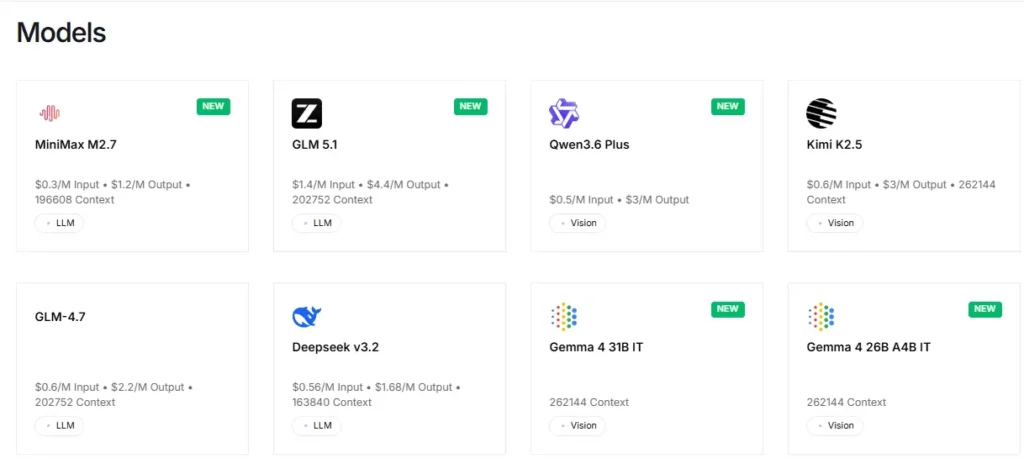
该平台提供对超过 100 种开源模型的即时访问,包括 Llama、Qwen、DeepSeek、Kimi K2.5、GLM 5、Mixtral 和 FLUX。 图像生成器开发者可以通过单个 API 接口测试和切换不同模型,无需任何配置更改。这使得跨模型系列的快速原型设计和 A/B 测试变得极其高效。
烟花爆竹 AI 支持包括LoRA、全参数监督微调、DPO(偏好对齐)和强化学习微调在内的全套微调方法。至关重要的是,微调后的模型与基础模型价格相同,避免了许多竞争对手收取额外费用的情况。此外,还支持视觉语言模型微调,允许团队使用自己的图像和文本数据集定制多模态模型。
对于需要专用资源的工作负载,Fireworks AI 按需提供 GPU部署 按秒计费。硬件产品线现已包含 NVIDIA A100、H100、H200、B200 和 B300 GPU。这使工程团队能够灵活地运行私有、隔离的模型实例,确保容量充足且不会受到邻近实例干扰。
近期推出的 Fire Pass 是一项每周 7 美元的订阅服务,可提供 Kimi K2.5 Turbo 型号的无限量代币访问,速度约为每秒 200 至 250 个代币。它专为使用 Claude Code 和 OpenCode 等代理编码工具的开发者设计,提供了一种固定费用方案,避免了按代币计费带来的不确定性。
烟花爆竹 AI 定价计划
| 计划名称 | Cost | 特点 |
|---|---|---|
| 无服务器(小型模型) | 每 0.10 万个代币 1 美元 | 4B参数下的模型 |
| 无服务器(中层) | 每 0.20 万个代币 1 美元 | 模型 4B 至 16B 参数 |
| 无服务器(大型模型) | 每 0.90 万个代币 1 美元 | 模型参数超过16亿个 |
| 无服务器(MoE 模型) | 每百万代币0.50美元至1.20美元 | 专家模型的混合类混合 |
| 火径 | 每周$ 7每 | 无限量的 Kimi K2.5 Turbo 代币 |
| 按需(H100) | 每GPU小时6.00美元 | 按秒计费,专用实例 |
| 按需供应(B200) | 每GPU小时9.00美元 | 最新一代GPU,按秒计费 |
| 企业版 | 定制化 | 年度折扣、服务水平协议和私有部署 |
Fireworks AI 入门指南
- 第三步: 在创建新帐户 烟花.ai注册后您将自动获得 1 美元的免费积分。
- 第三步: 导航至控制面板中的 API 密钥部分,并生成新的 API 密钥。
- 第三步: 安装 Fireworks Python 客户端或使用任何 OpenAI 兼容的 SDK。将您的基本 URL 指向 Fireworks API 端点。
- 第三步: 从模型库中选择一个模型,进行第一次 API 调用,然后从控制台监控使用情况和计费情况。
利与弊
- 业界领先的推理速度。
- 提供 100 多个开源模型。
- 包含完整的微调流程。
- 火焰通行证提供无限代币。
- 最新一代GPU硬件(B300)。
- 仅限开发者使用,无需代码的免费仪表盘。
- 没有内置的业务流程工具。
- 客户支持可能会很慢。

