爬行4AI 重要见解
Crawl4AI是什么?
Crawl4AI 是一个免费的开源 Python 库,可以将网页转换为大型语言模型可以直接使用的简洁 Markdown、结构化的 JSON 或经过过滤的 HTML。它基于 Playwright 构建,用于浏览器自动化,服务于构建 RAG 管道的开发者。 AI 该工具支持代理和自动化数据工作流程,同时支持基于 LLM 和不基于 LLM 的数据提取策略,使团队能够全面掌控成本和输出质量。
Crawl4 在 GitHub 上拥有超过 60,000 万颗星,每月在 PyPI 上的下载量超过 900,000 万次。AI 已成为最受欢迎的网络爬虫工具之一 AI 工程社区。它完全运行在您自己的基础设施上,因此无需 API 密钥,也没有按页收费。适用于需要生产规模数据提取的团队。 业务自动化,Crawl4AI 它提供了与任何 LLM 提供商集成的灵活性,同时保持爬取层完全免费。
爬行4AI Markdown 生成两种类型的输出,其官方网站对此有详细描述。Clean Markdown 保留了页面的正确格式,包括标题、表格、代码块和引用提示。Fit Markdown 则应用基于启发式的过滤方法,通过剪枝算法或 BM25 相关性评分来去除样板代码、导航和页脚等冗余信息。
这种双输出设计专为 RAG 管道和直接 LLM 摄取而设计。用户还可以构建自定义输出。 Markdown 生成 制定符合其具体管道需求的策略。
该工具提供两种不同的提取路径。对于布局可预测的页面,基于 CSS 和 XPath 的 JsonCssExtractionStrategy 会使用模式定义提取结构化的 JSON,并且无需调用任何 LLM。
对于复杂或不可预测的页面,LLMExtractionStrategy 可连接到任何 LLM 提供商(OpenAI、Ollama、DeepSeek 等),并使用 Pydantic schemas 返回结构完美的数据。分块策略(包括基于主题、正则表达式和句子级处理)可高效地处理大型页面。
自适应爬虫作为crawl4ai.com网站上的旗舰功能发布,它使用信息搜寻算法,并采用三层评分系统来衡量覆盖率、一致性和饱和度。它并非抓取网站上的每个页面,而是评估…… 内容相关性 每一步都会自动停止,当达到置信度阈值时自动停止。
它同时支持统计策略(快速、免费、基于词项)和嵌入策略(基于查询扩展的语义理解)。这可以防止过度爬取,并显著节省计算资源。
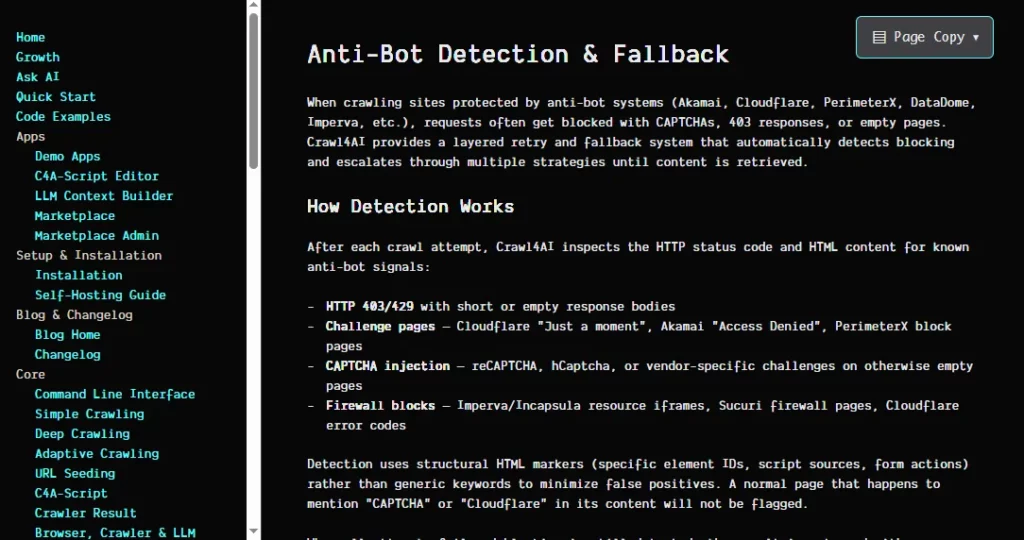
在 v0.8.5 版本中引入的三层结构 反机器人检测系统 它会检查已知的供应商签名、通用阻止指示器以及返回页面的结构完整性。当检测到阻止时,系统会自动通过可配置的代理链进行重试,并使用备用获取函数。结合模拟真实用户行为的隐身模式和 v0.7.3 版本中的不被检测到的浏览器模式,Crawl4 具备了这些功能。AI 一套强大的工具包,用于访问受保护的网站。
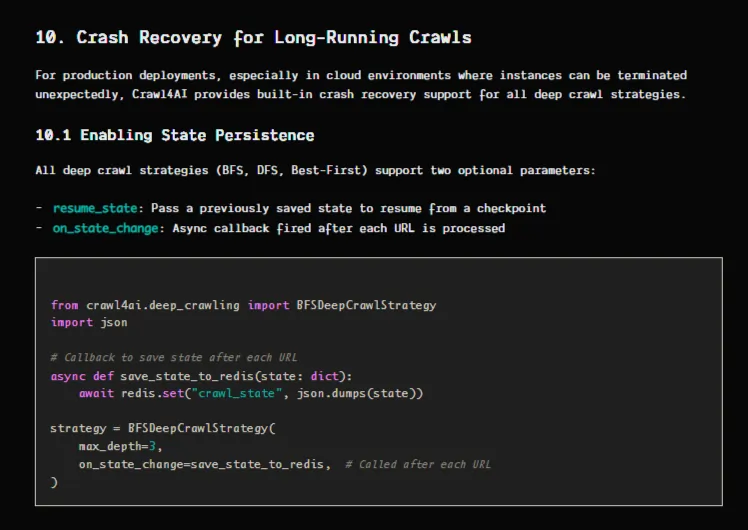
对于跨越数千页的大规模作业,深度爬取策略(BFS、DFS、最佳优先)在 v0.8.0 版本中内置了崩溃恢复功能。on_state_change 回调函数会在每个 URL 之后保存状态,而 resume_state 参数允许您在失败后从确切的检查点继续执行。
预取模式完全跳过 Markdown 生成和提取,使两阶段爬取工作流程的 URL 发现速度达到正常速度的 5 到 10 倍。
爬行4AI 它提供了一个优化的 Docker 镜像,其中包含 FastAPI 服务器、JWT 令牌认证、带有实时系统指标的实时监控仪表板,以及一个支持页面预热的三层浏览器池(永久、热、冷)。交互式环境允许团队测试爬虫配置并生成请求代码,而无需编写脚本。
MCP集成直接连接到 AI 类似 Claude Code 的工具。支持多架构,并可自动检测 AMD64 和 ARM64,确保可在任何云服务提供商上运行。
爬行4AI 定价计划
| 计划名称 | Cost | 特点 |
|---|---|---|
| 开源(自托管) | $0 | 无限次爬取,功能齐全,您只需提供基础设施。 |
| 云 API(封闭测试版) | 定制化 | 托管服务,申请优先体验,名额有限。 |
| 信徒赞助商 | $ 5 /月 | 社区支持层级,支持该项目 |
| 建设者赞助商 | $ 50 /月 | 优先支持和新功能抢先体验 |
| 团队赞助商 | $ 500 /月 | 每两周同步和优化指导 |
| 数据基础设施合作伙伴 | $ 2,000 /月 | 专注支持与全面合作 |
如何 Crawl4AI 是否支持 Markdown 生成?
爬行4AI 生成两种类型的 Markdown 输出。原始 Markdown 保留完整的页面结构,包括导航元素和页脚。拟合 Markdown 应用启发式过滤,使用剪枝算法或 BM25 相关性评分来去除噪声,仅保留核心内容。这对于 RAG 流程尤为重要,因为嵌入质量取决于干净的输入文本。
您还可以通过扩展基类来实现自定义 Markdown 生成策略,从而完全控制 HTML 元素如何映射到 Markdown 标记。引用系统会将页面链接转换为编号参考文献,这有助于 LLM 在检索任务期间跟踪来源归属。
利与弊
- 拥有超过 60,000 万名活跃用户的社区。
- Apache 2.0 宽松许可证。
- 适用于任何法学硕士(LLM)提供商。
- 采用异步架构以提高速度。
- 内置深度爬取崩溃恢复功能。
- 目前尚未提供托管云服务。
- 没有图形用户界面或可视界面。
- 反机器人程序需要设置代理。
最佳爬行4AI 备择方案
| AI 网络爬虫和抓取器 | 自托管选项 | LLM 无萃取 |
|---|---|---|
| 火爬 | 有限(受AGPL 3.0限制约束) | 不,需要 LLM 来处理结构化 JSON |
| 阿皮菲 | 不,完全依赖云的平台 | 不,取决于 AI 解析模型 |
| ScrapeGraphAI | 是的,开源Python库(MIT)。 | 不,每次提取都需要 LLM 调用。 |


