
仅靠及时调整已不再适合企业 AI 系统。随着模型上下文窗口数量超过 200 万个令牌,工程师们现在用文档、检索管道、便笺簿和工具调用来包装 LLM——这种方法被称为 情境工程.
转变发生得很快。
情境工程通过处理整个 AI 环境 作为一个系统而不是专注于个别的投入。
上下文工程:
真正有效的系统
上下文工程将 LLM 入学前的整个流程视为可工程化的基础设施。想象一下 LLM's 上下文窗口作为 RAM——它具有有限的工作内存,决定了模型可以处理什么。
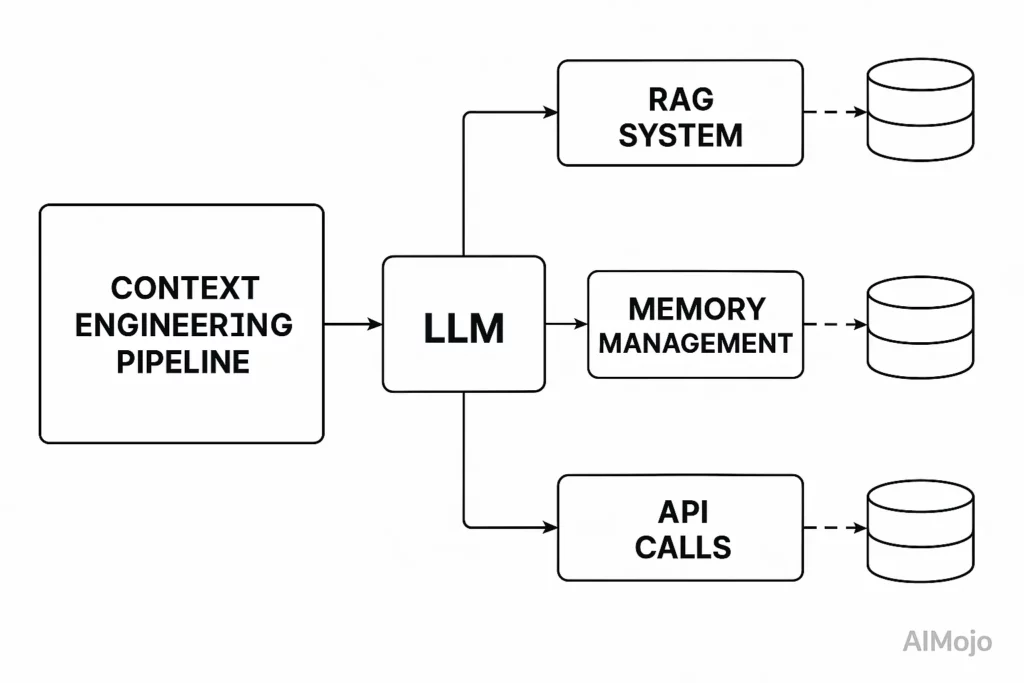
就像操作系统会仔细管理进入 RAM 的内容一样,上下文工程会管理填充 LLM 的信息's 上下文窗口。
服务's 背景工程实际上包括:
情境工程 vs 即时工程:
数字不会说谎
| 方面 | 即时工程 | 情境工程 |
|---|---|---|
| 专注 | 制作一个输入字符串 | 围绕模型协调每个信号 |
| 平均开发时间 | 70% 的及时调整 | 60% 数据管道、20% 内存规则、20% 提示 |
| 典型故障模式 | 数据漂移后输出质量突然下降 | 通过 RAG、内存、工具调用实现弹性 |
快速示例:一个 客户支持机器人 仅通过提示进行训练的机器人,在直接询问时就能想起退款政策。但当用户提到“订单 45791”时,它却记不住。添加上下文工程——对话历史记录加上 RAG 查询到订单数据库——机器人就能立即提取购买详情,并推荐正确的退款流程。
真正重要的情境工程四大支柱
1. 写作背景(你的人工智能's 笔记系统
编写上下文意味着保存 上下文窗口 以供将来使用。这节省了宝贵的令牌空间,同时保持了对重要数据的访问。
便笺簿 就像在单个会话中为代理做笔记一样工作。Anthropic's 多智能体研究人员将其初始计划保存为“内存“因为如果上下文超过 200,000 个标记,它会被截断并且计划会丢失。

长期记忆 跨多个会话保留信息。例如,ChatGPT 可以根据对话自动生成用户偏好设置,以及 Cursor/Windsurf 学习 编码模式 和项目背景。

关键洞察:信息量并不总是越大越好。有效的情境工程意味着针对每项具体任务选择正确的组合。
3. 上下文压缩(用更少的内容填充更多内容)
当对话变得太长,超出 LLM's 记忆 窗口,上下文压缩变得至关重要。代理通常通过总结对话的早期部分来实现这一点。

4. 上下文隔离(分而治之)
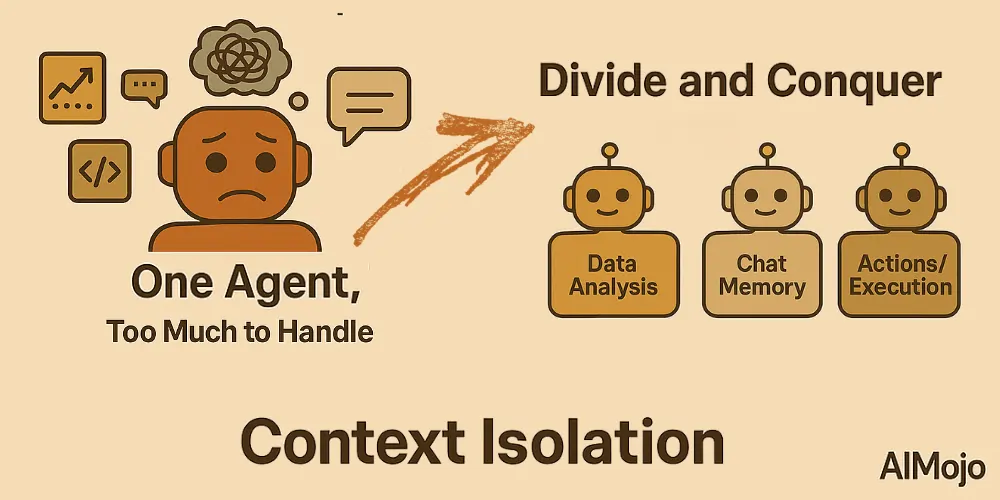
上下文隔离意味着将信息分解成独立的部分,以便智能体能够更好地处理复杂的任务。开发人员不会将所有知识塞进一个庞大的提示中,而是将上下文拆分给专门的子智能体,或者 沙盒环境.
现实世界情境工程的实际应用
客户服务革命
| 上下文工程之前 | 上下文工程之后 |
|---|---|
| 通用聊天机器人会忘记之前的对话并提供不相关的答案。 | AI 代理会记住您的购买历史记录、访问实时库存数据并在需要时与人工代理协调。 |
永不忘记的编码助手
该系统:当您询问“如何修复此身份验证错误?”时,上下文工程系统会自动:

您获得的不是通用的编码建议,而是针对您的实际代码库量身定制的具体解决方案。
支持情境工程的技术架构
动态上下文组装
上下文是即时构建的,并随着对话的进展而不断演变。这包括:
- 检索相关文件
- 保持记忆
- 更新用户状态
- API 调用和数据库查询
上下文窗口管理
固定大小 代币限制 (32K、100K、1M),工程师必须使用以下方式智能地压缩和优先处理信息:
- 评分函数(TF-IDF、嵌入、注意力启发式)
- 摘要和显著性提取
- 分块策略和重叠调整

安全性和一致性
应用诸如及时注入检测等原则, 上下文清理, PII 编辑以及基于角色的上下文访问控制。
构建您的第一个上下文工程系统
构建上下文工程工作流程不仅仅是理论——它's 这是一个可重复、可操作甚至可自动化的流程。以下是如何将其付诸实践:
第三步: 绘制上下文来源
确定您的代理需要从哪里提取信息(文档、数据库、API、以前的聊天等)。
蟒蛇
# Example: Fetching relevant documents using embeddings
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer("all-MiniLM-L6-v2")
query = "project status update"
corpus = ["spec doc", "requirements", "last week's meeting notes"]
query_embedding = model.encode(query, convert_to_tensor=True)
corpus_embeddings = model.encode(corpus, convert_to_tensor=True)
hits = util.semantic_search(query_embedding, corpus_embeddings, top_k=2)[0]
relevant_docs = [corpus[hit['corpus_id']] for hit in hits]
第三步: 实现记忆和写作语境
存储重要信息,以便在将来的任务中随时可用。
蟒蛇
import json
def save_to_memory(memory_path, user_id, data):
with open(memory_path, "r+") as file:
memory = json.load(file)
memory[user_id] = data
file.seek(0)
json.dump(memory, file)
file.truncate()第三步: 构建上下文选择和压缩逻辑
制定规则或模型,只挑选与任务最相关的内容。将冗长的历史记录压缩成摘要形式。
蟒蛇
def summarize_conversation(history):
# Placeholder for use with an LLM summarizer or custom rules
return history[-5:] # Only the last 5 messages第三步: 隔离上下文以协调代理
分割信息,以便每个代理或组件只处理其应该处理的信息。
蟒蛇
user_profile_ctx = {"user_goals": "..."}
task_specific_ctx = {"current_task": "..."}
external_data_ctx = {"live_data": "..."}
full_context = {**user_profile_ctx, **task_specific_ctx, **external_data_ctx}第三步: 输出结构和 API 准备
格式化输出上下文,使其's 对于下游 LLM 调用或 API 端点而言是可预测的。
蟒蛇
schema = {
"user": {"age": 35, "goal": "muscle gain"},
"plan": "high protein, 3x/week weight training"
}第三步: 监控、迭代和安全
跟踪故障,审核上下文质量,并改进上下文包含、内存和检索的逻辑。始终对输入进行清理,以避免提示注入和数据泄露。
为什么情境工程比即时工程收益更高
公司需要能够构建系统的工程师,该系统可以为人工智能提供正确的背景,保持信息的准确性和最新性,并通过添加安全指南来保护用户。
市场现实:上下文工程需要跨职能技能,包括理解业务用例、定义输出和构建信息,以便 LLM 能够完成复杂的任务。
底线: 任何人都可以编写提示。构建能够大规模记忆、调整和选择上下文的上下文感知代理?这就是开发人员如何通过高级 LLM 应用程序确保其技能面向未来并创造实际价值的方法。



 奖金: 获得我们的 200 美元“AI 注册即可免费获得“精通工具包”!
奖金: 获得我们的 200 美元“AI 注册即可免费获得“精通工具包”!






