
Більшість людей приземляються на Обіймати обличчя, втупитися в стіну з назвами моделей і клацнути далі протягом 30 секунд. Велика помилка.
Поки всі сперечаються про те, який AI інструмент вартий того, щоб за нього платити, десятки тисяч будівельників непомітно використовують Hugging Face для запуску, точного налаштування та судно AПрограми на базі I — абсолютно безкоштовно. Це's не просто бібліотека моделей. Це's платформа, де Google, Meta, Mistral та окремі розробники працюють в одному просторі.
більше 1 мільйон моделей, понад 500 тисяч наборів даних та безкоштовний хостинг додатків — під одним обліковим записом. Тут's повний розклад того, що це таке і як це насправді використовувати.
Що таке обіймати обличчя насправді (більшість людей помиляються)
ПодіяGitHub машинного навчання«Термін «» часто вживається. Він зосереджений в одному напрямку — публічні репозиторії, контроль версій, внесок спільноти. Але він швидко руйнується. Hugging Face також запускає живий висновок, розміщує додатки на базі штучного інтелекту та забезпечує повну навчальну інфраструктуру. GitHub нічого з цього не робить.
Сама компанія починала як стартап чат-ботів для NLP, а потім перейшла до розробки програмного забезпечення з відкритим вихідним кодом. AI інструменти, і ніколи не озирався назад. Публічна платформа is fвільний та керований громадою; корпоративні продукти – це спосіб заробляти гроші. Для початківців безкоштовний рівень охоплює все необхідне. Моделі публікуються тут. перед тим вони потрапляють у заголовки газет — якщо в ШІ з'являється щось нове, це спочатку відображається на Hugging Face.
Три стовпи — знайте їх, перш ніж будь-що інше
Все на Hugging Face зосереджено у трьох основних розділах:
| стовп | Що це | Чому це має значення |
|---|---|---|
| моделі | 1 млн+ попередньо навчених AI Моделі | Повністю пропустити навчання з нуля |
| Набори даних | Сирі дані для навчання та тестування | Стандартизовані, готові до завантаження дані |
| Приміщення | Безкоштовний хостинг AI додатка | Тестування моделей без дотику до коду розгортання |
Звикніть до всіх трьох — вони постійно взаємодіють під час будівництва.
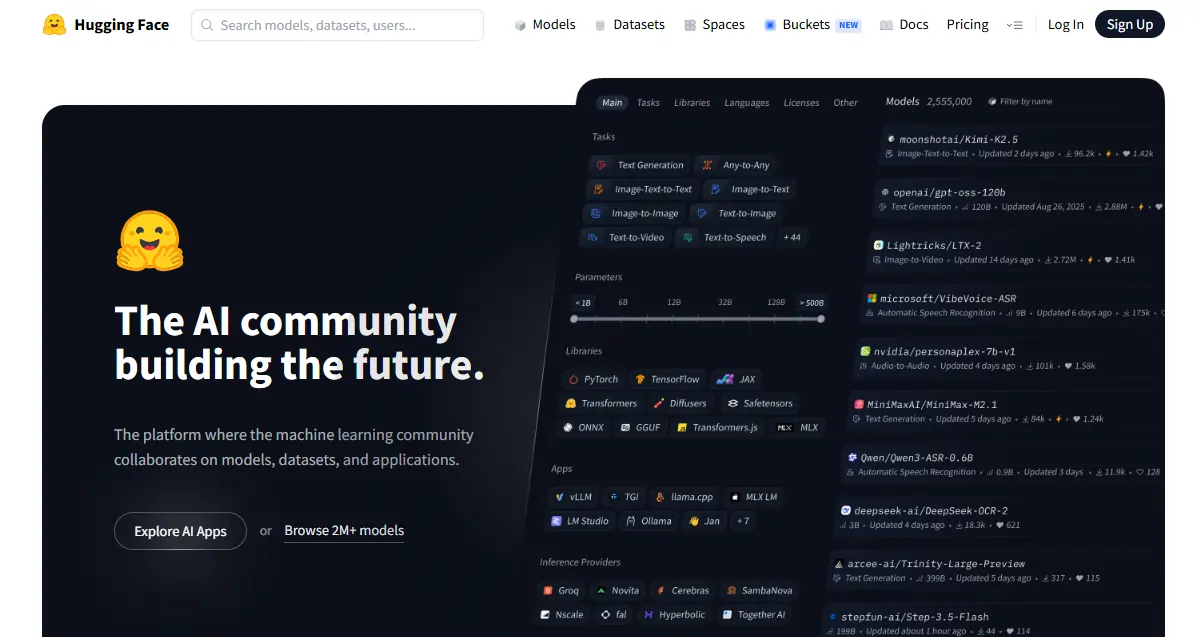
Центр моделей — місце, де ви проводитимете більшу частину свого часу
Панель фільтрів — ваш найкращий друг тут: тип завдання, фреймворк (PyTorch, TensorFlow, JAX), мова, ліцензія та розмір моделі. Сортувати за найбільше завантажується для перевірених у боях варіантів; сортувати за нещодавно оновлено коли вам потрібні свіжі варіанти.
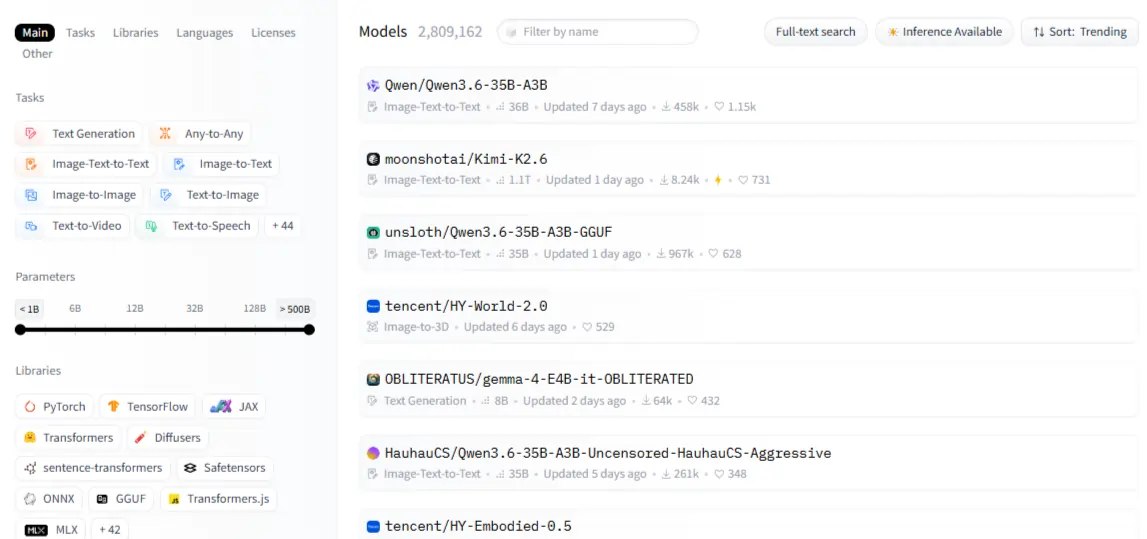
Кожна модель має картку — прочитайте її. У розділі «Призначення» зазначено, для чого була створена модель; розділ обмежень показує, де він зламався. Ця друга частина цінніша за будь-який бенчмарк. Категорії моделей охоплюють NLP (класифікація тексту, узагальнення, переклад, відповіді на запитання), зір (класифікація зображень, виявлення об'єктів, генерація), аудіо (ASR, TTS) та мультимодальні завдання як візуальні відповіді на запитання.
Одна річ, яку не помічають новачки: не всі моделі можна вільно завантажити. Моделі з обмеженим доступом, такі як Meta's Лама вимагають схвалення перед доступом. Після схвалення ви автентифікуєтесь за допомогою токена доступу. Завжди перевіряйте ліцензію перед складанням — деякі моделі повністю забороняють комерційне використання.
Бібліотека Трансформерів — Код, що виконує половину AI World
Команда transformers бібліотека – це єдиний Python пакет що стандартизує спосіб завантаження та запуску будь-якої моделі на хабі в PyTorch, TensorFlow та JAX з одним і тим самим API.

Команда pipeline() function — це те, з чого варто починати більшості новачків — вона об'єднує токенізацію, завантаження моделі та постобробку в один виклик. Аналіз почуттів, генерація тексту, класифікація зображень — усе це відбувається за однією й тією ж схемою. Щойно вам знадобиться детальний контроль над виходами, перейдіть до написання власного коду виводу. До того часу конвеєри обробляють усе.
Не пропускайте токенізацію. Необроблений текст не може безпосередньо потрапити в модель. AutoTokenizer обробляє конвертацію та завжди автоматично зіставляє правильний токенізатор із правильною контрольною точкою. Невідповідні токенізатори спричиняють найзаплутаніші помилки, з якими стикаються новачки, — і їх можна на 100% уникнути.
| Завдання | Назва трубопроводу | Приклад моделі |
|---|---|---|
| Аналіз почуттів | text-classification | Distilbert Base без корпусу |
| Генерація тексту | text-generation | Містраль-7Б |
| Узагальнення | summarization | facebook/bart-large-cnn |
| Розпізнавання мови | automatic-speech-recognition | openai/whisper-base |
| Класифікація зображень | image-classification | google/vit-base-patch16 |
Набори даних та простори — дві функції, якими ніхто не користується достатньо
Команда datasets Бібліотека завантажує дані у форматі Apache Arrow — швидко, ефективно використовує пам'ять та створена для обробки наборів даних, які не поміщаються в оперативну пам'ять. load_dataset("name", split="train") – це все, що потрібно для початку. Перш ніж використовувати будь-який набір даних для навчального запуску, скористайтеся Data Studio у браузері, щоб переглянути та відфільтрувати його без написання жодного рядка коду.
Простори – це місце, де AI Демо-версії публікуються безкоштовно. Ваша програма отримує URL-адресу, якою можна поділитися, за лічені хвилини без жодних зусиль DevOps. Безкоштовний рівень процесора обробляє легкі демо-версії; платні Spaces з підтримкою графічного процесора обробляють складніші моделі.
Скористайтеся кнопкою Градіо для швидких демонстрацій моделей з мінімальним кодом; використовуйте Стрітліт коли вашому додатку потрібен макет панелі інструментів з більшою кількістю даних. Клонування трендового простору — це найшвидший спосіб почати: виберіть один у своїй категорії, розщепіть його та налаштуйте.
Правильне налаштування облікового запису
Безкоштовний рівень охоплює перегляд моделей, простори процесора, виклики API з обмеженою швидкістю та повний доступ до спільноти. Pro додає пріоритетні простори графічного процесора, розширений висновок та приватні репозиторії. Для більшості початківців безкоштовного варіанту достатньо.
Згенеруйте токен доступу в розділі налаштування → Токени доступуТокени читання працюють для завантаження; токени запису потрібні для надсилання моделей або наборів даних. Аутентифікація в Python за допомогою huggingface_hub.login()Для вашої установки:

бити
pip install transformers datasets huggingface_hubдодавати accelerate, peft та trl якщо планується точне налаштування. Google Colab — найшвидше середовище для абсолютних початківців — безкоштовне GPU, нічого не потрібно налаштовувати локально.
Запуск вашої першої моделі, а потім її адаптація до вашої
Для аналізу настроїв: call pipeline("text-classification"), передати рядок, прочитати label та score назад. Для генерації тексту: використовуйте max_new_tokens, temperature та do_sample контролювати, наскільки креативним чи послідовним є результат. Те саме pipeline() Шаблон працює для перекладу, розпізнавання мовлення та класифікації зображень — API не змінюється, змінюється лише назва завдання.
Коли щось ламається:
Щойно основи зрозуміють, наступним кроком буде точне налаштування. Попередньо навчені моделі є загальними; точно налаштовані моделі є точними. Точне налаштування виключає підказки, коли ви працюєте з даними, специфічними для предметної області, потребуєте узгодженої поведінки або хочете зменшити витрати на висновок, запустивши меншу спеціалізовану модель.
PEFT Заморожує більшу частину моделі та навчає лише легкі адаптери — графічний процесор вартістю 10 тисяч доларів не потрібен. QLoRA розвиває цю функцію завдяки квантуванню, що робить можливим точне налаштування моделі 7B параметрів на одному споживчому графічному процесорі.
Команда Trainer API керує всім циклом — пакетною обробкою, оцінкою, контрольними точками — а повернення до хабу займає один рядок після завершення.
Висновок без власного сервера
Розміщений API Inference миттєво надає вам кінцеву точку REST для будь-якої публічної моделі. Безкоштовний рівень обмежений швидкістю — підходить для тестування, а не для продакшену. Для реальних застосунків, Кінцеві точки висновку надають спеціалізований, приватний API, який автоматично масштабується до нуля під час простою, забезпечуючи керованість витрат для змінного трафіку.
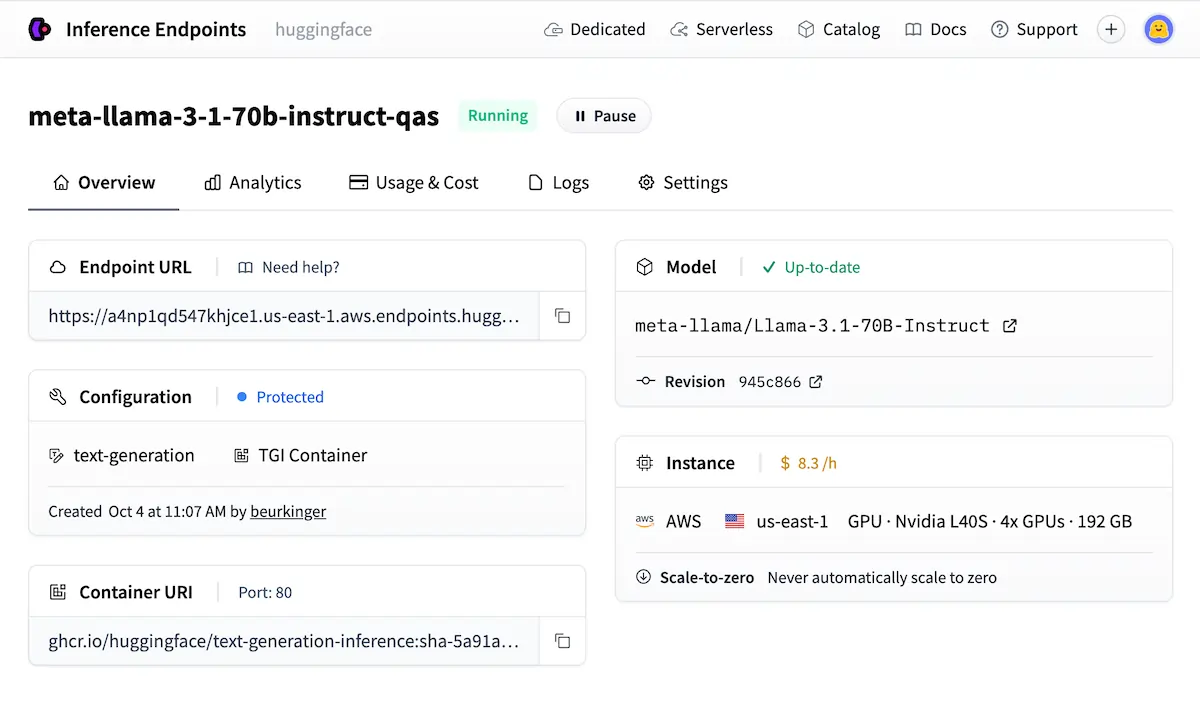
Коли конфіденційність даних або затримка не підлягають обговоренню, самостійний хостинг з TGI (Висновок про генерацію тексту) or vLLM це шлях, готовий до виробництва.
Спільнота, таблиці лідерів та чому вона перевершує все інше
Команда Відкрийте таблицю лідерів LLM ранжує моделі за бенчмарком — корисно для формування короткого списку, але завжди перевіряйте фактичний варіант використання, перш ніж довіряти оцінкам. Облікові записи організацій дозволяють командам керувати спільними колекціями моделей з контрольованим доступом; Meta AI, Google та EleutherAI усі облікові записи організацій керують безпосередньо на хабі.
Підписка на дослідників та організації надає вам інформацію про нові моделі в режимі реального часу без необхідності стежити за соціальними мережами.
| платформа | Open Source | Сорт моделі | Безкоштовний рівень | Інструменти точного налаштування |
|---|---|---|---|---|
| Обіймати обличчя | ✅ Повний | ✅ 1 млн+ | ✅ Щедрий | ✅ Повний стек |
| Концентратор TensorFlow | ✅ Так | 🔶 Обмежена | ✅ Так | ❌ Базовий |
| Модельний сад Google | ❌ Часткове | 🔶 Куратор | 🔶 Тільки GCP | 🔶 Тільки GCP |
| відкритийAI API | ❌ Ні | ❌ Закрито | ❌ Тільки платно | 🔶 Обмежена |
Помилки, які коштуватимуть вам годин
- Вибір найбільшої моделі, коли менша, призначена для виконання конкретних завдань, працює швидше та дешевше.
- Пропускання картки моделі's розділ обмежень, перш ніж створювати щось на його основі
- Не закріплення редакцій моделі — моделі оновлюються непомітно, а вихідні дані зміщуються без попередження
- Використання безкоштовного API Inference для будь-чого, що потребує стабільної безперебійної роботи
- Передача необробленого тексту безпосередньо в модель без попередньої пропуски через токенізатор
АйМоджо рекомендує:
Куди піти
Обіймати обличчя's безкоштовні курси at hf.co/learn охоплювати NLP, аудіо та глибоке навчання з підкріпленням у структурованих шляхах, створених спеціально для цієї платформи. Найкращий перший проект: налаштувати класифікатор тексту на власному наборі даних, обгорнути його в Gradio та розгорнути як простір.
Ця єдина збірка охоплює моделі, набори даних, точне налаштування та простори одним махом. Як тільки це станеться's в режимі реального часу, завантажте модель та напишіть відповідну картку моделі, яка охоплює цільове використання, навчальні дані та обмеження.
Що's як робляться корисні громадські внески, і це's як почати будувати справжню присутність у ШІ з відкритим кодом просторі.



 БОНУС: Отримайте наші 200 доларівAI «Набір інструментів майстерності» БЕЗКОШТОВНО при реєстрації!
БОНУС: Отримайте наші 200 доларівAI «Набір інструментів майстерності» БЕЗКОШТОВНО при реєстрації!






