magkasama AI Mga Pangunahing Pananaw
Ano ang Together AI?
Magkasama AI ay isang buong stack AI Isang cloud platform na ginawa para sa mga developer at ML engineer na nangangailangan ng mabilis at matipid na access sa mga open source na malalaking language model. Itinatag noong 2020, ang platform ay nag-aalok ng serverless inference, model fine tuning, mga nakalaang GPU endpoint, at mga on demand GPU cluster lahat sa ilalim ng iisang bubong. Sinusuportahan nito ang mahigit 200 modelo mula sa mga pamilya kabilang ang Llama 4, DeepSeek V3, Qwen 3.5, Mistral, at FLUX para sa pagbuo ng imahe.
magkasama AI inaalis ang pasanin ng pamamahala ng imprastraktura ng GPU upang ang mga koponan ay makapagtuon sa pagbuo AI mga katutubong aplikasyon. Bukas ItoAI Ang tugmang API ay nangangahulugan na ang mga umiiral na codebase ay maaaring lumipat nang may kaunting pagbabago. Para sa mga negosyong naghahanap ng malaking volume AI mga workload sa mas maliit na bahagi ng mga gastos sa proprietary API, Sama-sama AI ay nasa isang matibay na posisyon bilang isang tagapagbigay ng hinuha at pagsasanay para sa antas ng produksyon.
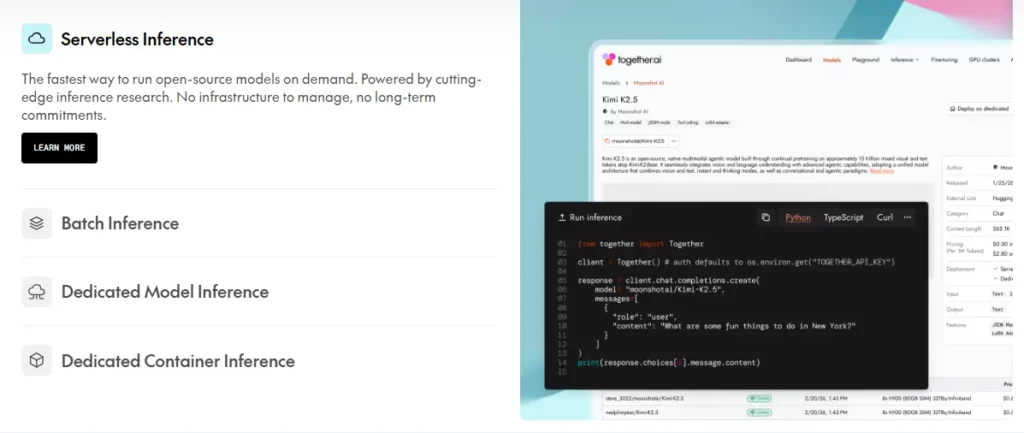
magkasama AI nagho-host ng higit sa 200 open source na mga modelo Saklaw nito ang teksto, imahe, video, audio, mga embedding, at pagbuo ng code. Maaaring tawagan ng mga developer ang anumang modelo sa pamamagitan ng isang API nang hindi nagpo-provision ng mga server. Ang mga modelong tulad ng Llama 4 Maverick ay tumatakbo sa humigit-kumulang $0.27 bawat milyong input token, na ginagawang mas mura ang mga workload ng mataas na volume ng produksyon kaysa sa mga alternatibong pagmamay-ari. Kasama rin sa platform ang isang Batch API para sa mga hindi agarang trabaho sa mas mababang gastos.
Ang proprietary inference engine ng AI ay gumagamit ng FlashAttention 3 at ng ATLAS speculator system upang makapaghatid ng hanggang 3.5x na mas mabilis na inference kaysa sa mga karaniwang implementasyon. Sa NVIDIA H100 hardware, nakakamit nito ang humigit-kumulang 840 TFLOPs/s na may katumpakan ng BF16. Ang resulta sa totoong mundo ay humigit-kumulang 400 token kada segundo sa produksyon, humigit-kumulang 2.5 hanggang 4 na beses na mas mabilis kaysa sa bilis ng output ng GPT 4 Turbo.
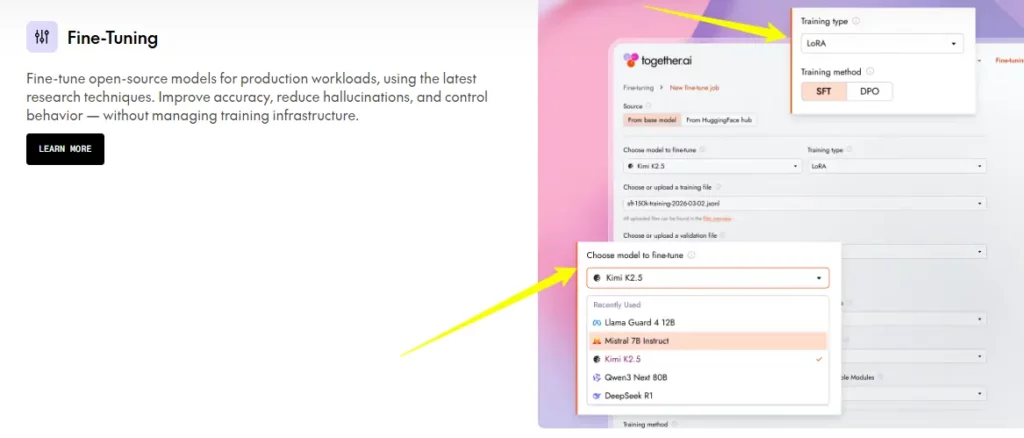
Sinusuportahan ng platform ang parehong LoRA (Low Rank Adaptation) at full weight fine tuning para sa mga modelong hanggang 100B parameters. Nagsisimula ang presyo sa $0.48 bawat milyong token para sa LoRA sa mga modelong hanggang 16B. Maaaring sanayin ng mga team ang mga modelo gamit ang proprietary data upang lumikha ng mga task specific system para sa legal, medikal, o... mga aplikasyon ng suporta sa customer at pagkatapos ay agad na i-deploy ang mga ito sa inference stack ng Together AI.
Para sa mga pangkat na nangangailangan ng nakalaang compute, Sama-sama AI Nag-aalok ng agarang access sa NVIDIA H100, H200, B200, at sa pinakabagong GB200 at GB300 NVL72 racks. Ang on demand na presyo ay nagsisimula sa $3.49 kada oras para sa isang H100 node, na may reserved pricing na bababa sa $2.55 kada oras para sa mas mahahabang commitment. Ginagawa itong isang matibay na alternatibo sa AWS, GCP, o Azure para sa mga workload ng ML training.
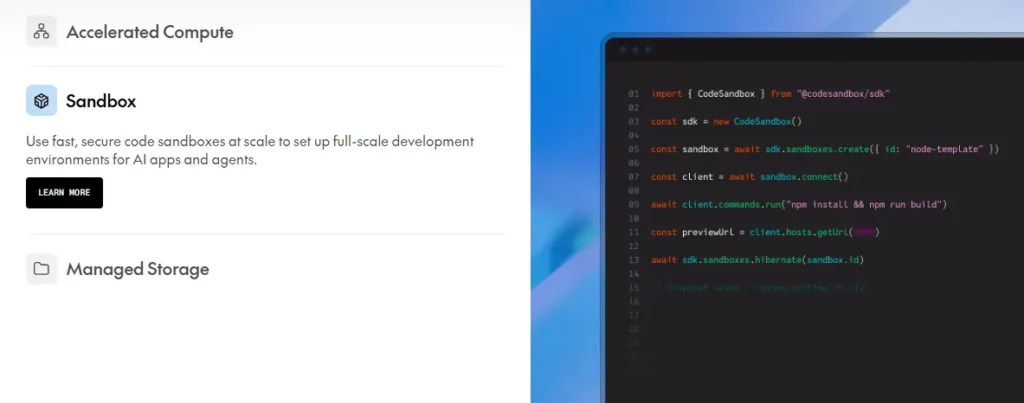
Paglipat mula sa API ng OpenAI patungo sa Together AI nangangailangan lamang ng pagbabago ng base URL. Nagbibigay din ang platform ng Code Interpreter na nagpapatupad Kodigo na nabuo ng LLM sa mga sandboxed environment sa halagang $0.03 bawat session, kasama ang isang kumpletong Code Sandbox para sa mas malalaking development environment na sinisingil kada vCPU hour.
magkasama AI Mga Plano sa Pagpepresyo
| Plano | gastos | key Detalye |
|---|---|---|
| Hinuha nang Walang Server | $0.02 hanggang $7.00 bawat 1M token | Nag-iiba-iba depende sa modelo. Mas mahal ang mga output token kaysa sa input. |
| Mga Nakalaang Endpoint | Mula $3.99/oras | Single tenant GPU na may garantisadong pagganap |
| Mga Kumpol ng GPU (On Demand) | $ 3.49 / oras | Pagsingil kada oras, walang pangako |
| Mga Kumpol ng GPU (Nakareserba) | $2.55/oras hanggang $7.15/oras | 1 linggo hanggang 6+ buwang termino na may mga diskwento sa dami |
| Pagpino ng Pag-tune (LoRA) | $0.48 hanggang $2.90 bawat 1M token | Batay sa laki ng modelo (hanggang 100B) |
| Pag-fine Tune (Buo) | $0.54 hanggang $3.20 bawat 1M token | Na-update ang lahat ng timbang |
| Tagapagsalin ng Kodigo | $ 0.03 bawat session | Pagpapatupad ng naka-sandbox na code |
| Ibinahaging Filesystem | $0.16 kada GiB/buwan | Mataas na bandwidth na parallel storage |
magkasama AI Pananaliksik at Mga Kontribusyon ng Open Source
magkasama AI ay hindi lamang isang tagapagbigay ng imprastraktura. Aktibong itinutulak ng kumpanya AI pasulong na pananaliksik. Ang pangkat nito ang lumikha ng FlashAttention, na ngayon ay ang karaniwang mekanismo ng atensyon na ginagamit sa buong industriya. Kabilang sa iba pang mga kontribusyon ang Mixture of Agents, ang Red Pajama open datasets, DeepCoder, at ang Open Data Scientist Agent.
Ang pamamaraang ito na unang pananaliksik ay nangangahulugang ang pinakabago mga pamamaraan sa pag-optimize at ang mga arkitektura ng modelo ay makukuha na sa platform mula sa unang araw. Para sa mga pangkat ng inhinyero na pinahahalagahan ang pananatili sa hangganan ng pagganap ng modelo, ang patuloy na pipeline ng pananaliksik na ito ay nagbibigay ng Sama-sama AI isang teknikal na kalamangan na hindi kayang tapatan ng mga purong cloud compute reseller.
Mga kalamangan at kahinaan
- Mahigit 200 open source na modelo ang magagamit.
- Nangunguna sa industriya ang bilis ng paghihinuha.
- PagbubukasAI paglipat ng katugmang API.
- Mga opsyon sa flexible na GPU cluster.
- Malakas na suporta sa pinong pag-tune.
- Aktibo AI kontribusyon sa pananaliksik
- Walang permanenteng libreng antas.
- Developer lamang, hindi angkop para sa mga baguhan.
- Maaaring mahirap hulaan ang gastos.
Pinakamahusay na Magkasama AI Alternatibo
| AI Plataporma ng Imprastraktura / MLOps | Kahusayan ng Gastos | Lapad ng Modelo |
|---|---|---|
| Magtiklop | Bayad kada segundong pagsingil, mainam para sa mabilis na pagkarga ng trabaho | Mahigit 100 modelo, malakas sa pagpapalaganap at pasadyang mga modelo |
| OpenRouter | Pinagsasama-sama ang mga provider para sa pinakamababang gastos sa bawat token | Mahigit 200 modelo sa maraming backend |
| Fireworks AI | Kompetitibong presyong walang server, mabilis na paghihinuha | Nakatuon sa mga nangungunang open source na LLM |
| Mga Endpoint ng Hinuha sa Pagyakap sa Mukha | Libreng tier na magagamit, flexible na pag-deploy | Pinakamalaking open source model hub |


