Mga paputok AI Mga Pangunahing Pananaw
Ano ang Fireworks AI?
Fireworks AI ay isang high performance inference platform na ginawa para sa mga developer at enterprise na kailangang magpatakbo, mag-fine tune, at mag-scale ng open source. AI mga modelo sa bilis ng antas ng produksyon. Itinatag ng mga dating miyembro ng pangkat ng PyTorch sa Meta, ang plataporma ay nagbibigay ng isang BukasAI isang tugmang API na nagbibigay ng access sa mahigit 100 sikat na malalaking modelo ng wika, mga modelo ng paningin, at mga modelo ng pagbuo ng imahe.
Mga paputok AI Tinatanggal ang pasanin sa pagpapatakbo ng pamamahala ng imprastraktura ng GPU sa pamamagitan ng pag-aalok ng parehong mga opsyon sa pag-deploy nang walang server at on demand. Gumagamit ang mga negosyo ng Fireworks AI para paganahin ang mga chatbot, mga katulong sa coding, mga search engine, at mga ahente AI mga daloy ng trabaho. Ang custom-built inference engine nito ay naghahatid ng hanggang 4x na mas mataas na throughput at 50% na mas mababang latency kaysa sa mga karaniwang open source serving stack, na ginagawa itong isa sa pinakamabilis AI Mga API provider na available ngayon para sa generative AI mga workload sa produksyon.
Ang proprietary inference engine ng Fireworks AI ay binuo mula sa simula para sa bilis. Palagi itong naghahatid ng first token latency sa loob ng 100 milliseconds sa iba't ibang laki ng modelo. Para sa anumang aplikasyon na nangangailangan ng real time responsiveness, tulad ng mga customer facing chatbot o mga katulong sa pag-coding ng ahente, ang bentahe sa pagganap na ito ay masusukat at makabuluhan. Ang mga kumpanyang tulad ng Sourcegraph at Notion ay hayagan nang nagtala ng mga pagtaas sa throughput pagkatapos lumipat sa platform.
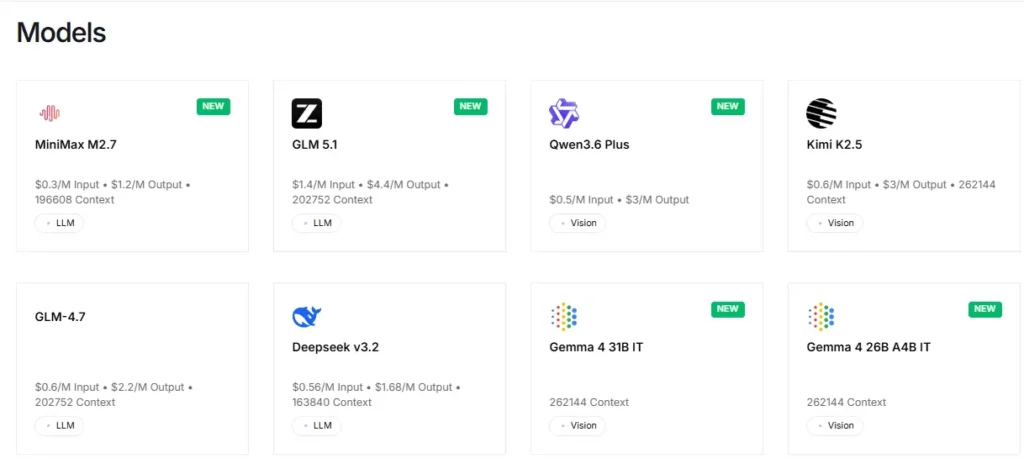
Ang plataporma ay nagbibigay ng agarang access sa mahigit 100 open source na modelo, kabilang ang Llama, Qwen, DeepSeek, Kimi K2.5, GLM 5, Mixtral, at FLUX. mga generator ng imaheMaaaring subukan at magpalitan ang mga developer sa pagitan ng mga modelo sa pamamagitan ng iisang API endpoint nang walang mga pagbabago sa configuration. Ginagawa nitong lubos na mabisa ang rapid prototyping at A/B testing sa iba't ibang pamilya ng modelo.
Mga paputok AI Sinusuportahan ang buong hanay ng mga pamamaraan ng fine tuning kabilang ang LoRA, full parameter supervised fine tuning, DPO (preference alignment), at reinforcement fine tuning. Mahalaga, ang mga fine tuned na modelo ay inihahain sa parehong presyo tulad ng mga base na modelo, na nag-aalis ng cost penalty na ipinapataw ng maraming kakumpitensya. Sinusuportahan din ang fine tuning ng vision language model, na nagbibigay-daan sa mga team na i-customize ang mga multimodal na modelo gamit ang kanilang sariling mga dataset ng imahe at teksto.
Para sa mga workload na nangangailangan ng mga nakalaang resources, Fireworks AI mga alok kapag hiniling Mga pag-deploy ng GPU sinisingil kada segundo. Kasama na ngayon sa hanay ng hardware ang mga NVIDIA A100, H100, H200, B200, at B300 GPU. Nagbibigay ito sa mga engineering team ng kakayahang umangkop upang magpatakbo ng pribado at nakahiwalay na mga modelo ng instance na may garantisadong kapasidad at walang maingay na isyu sa kapitbahay.
Isang kamakailang karagdagan, ang Fire Pass ay isang $7 kada linggong subscription na nagbibigay ng walang limitasyong token access sa modelong Kimi K2.5 Turbo sa bilis na humigit-kumulang 200 hanggang 250 token kada segundo. Ito ay partikular na idinisenyo para sa mga developer na gumagamit ng mga agentic coding tool tulad ng Claude Code at OpenCode, na nag-aalok ng alternatibong flat rate sa hindi mahuhulaan na pagsingil kada token.
Mga paputok AI Mga Plano sa Pagpepresyo
| Pangalan ng Plano | gastos | key Detalye |
|---|---|---|
| Walang Server (Maliliit na Modelo) | $0.10 bawat 1M token | Mga modelo sa ilalim ng mga parameter ng 4B |
| Walang Server (Katamtamang Antas) | $0.20 bawat 1M token | Mga parametro ng Modelo 4B hanggang 16B |
| Walang Server (Malalaking Modelo) | $0.90 bawat 1M token | Mga modelong higit sa 16B na mga parameter |
| Walang Server (Mga Modelo ng MoE) | $0.50 hanggang $1.20 bawat 1M token | Pinaghalong klase ng mga modelo ng eksperto |
| Sunog Pass | $ 7 bawat linggo | Walang limitasyong mga token ng Kimi K2.5 Turbo |
| On Demand (H100) | $6.00 kada oras ng GPU | Sinisingil kada segundo, nakalaang instance |
| On Demand (B200) | $9.00 kada oras ng GPU | Pinakabagong henerasyon ng GPU, sinisingil kada segundo |
| enterprise | Pasadya | Mga taunang diskwento, SLA, at mga pribadong pag-deploy |
Pagsisimula sa Fireworks AI
- Hakbang 1: Gumawa ng isang account sa paputok.aiAwtomatiko kang makakatanggap ng $1 na libreng kredito sa pag-sign up.
- Hakbang 2: Mag-navigate sa seksyong API Keys sa iyong dashboard at bumuo ng bagong API key.
- Hakbang 3: I-install ang Fireworks Python client o gumamit ng anumang OpenAI tugmang SDK. Ituro ang iyong base URL sa endpoint ng Fireworks API.
- Hakbang 4: Pumili ng modelo mula sa model library, gawin ang iyong unang API call, at subaybayan ang paggamit at pagsingil mula sa console.
Mga kalamangan at kahinaan
- Nangunguna sa industriya ang bilis ng paghihinuha.
- Mahigit 100 open source na modelo ang magagamit.
- Kasama ang kumpletong fine tuning pipeline.
- Nag-aalok ang Fire Pass ng walang limitasyong mga token.
- Pinakabagong henerasyon ng hardware ng GPU (B300).
- Para sa developer lamang, walang libreng code sa dashboard.
- Walang built-in na mga tool sa daloy ng trabaho sa negosyo.
- Maaaring mabagal ang suporta sa customer.
Pinakamahusay na Paputok AI Alternatibo
| AI Plataporma ng Paghahatid ng Hinuha at Modelo | Inference Throughput | Kahusayan ng Gastos |
|---|---|---|
| Magkasama AI | 917 TPS, mas mataas na latency (0.78s) | Parehong rate kada token, mas kaunting uri ng GPU |
| Groq | 456 TPS sa pamamagitan ng mga pasadyang LPU, 0.19s latency | Mas mababang presyo para sa pagpasok, limitadong pagpipilian ng modelo |
| Magtiklop | Katamtamang bilis, nakabatay sa lalagyan | Simpleng pagsingil kada hula, mas kaunting pinong pag-tune |
| Baseten | Nako-customize na infra, katamtamang bilis | Flexible ngunit nangangailangan ng mas maraming configuration |

