ดอกไม้ไฟ AI ข้อมูลเชิงลึกที่สำคัญ
Fireworks AI คืออะไร?
ดอกไม้ไฟเอไอ เป็นแพลตฟอร์มการอนุมานประสิทธิภาพสูงที่สร้างขึ้นโดยเฉพาะสำหรับนักพัฒนาและองค์กรที่ต้องการใช้งาน ปรับแต่ง และขยายขนาดซอฟต์แวร์โอเพนซอร์ส AI สร้างโมเดลด้วยความเร็วระดับใช้งานจริง แพลตฟอร์มนี้ก่อตั้งโดยอดีตสมาชิกทีม PyTorch ที่ Meta และนำเสนอโซลูชันแบบเปิดAI API ที่เข้ากันได้ซึ่งช่วยให้เข้าถึงโมเดลภาษาขนาดใหญ่ โมเดลการมองเห็น และโมเดลการสร้างภาพยอดนิยมกว่า 100 รายการ
ดอกไม้ไฟ AI ช่วยลดภาระการดำเนินงานในการจัดการโครงสร้างพื้นฐาน GPU โดยนำเสนอตัวเลือกการใช้งานทั้งแบบไร้เซิร์ฟเวอร์และแบบตามความต้องการ ธุรกิจต่างๆ ใช้ Fireworks AI เพื่อขับเคลื่อนแชทบอท ผู้ช่วยการเขียนโค้ดเครื่องมือค้นหา และตัวแทน AI เวิร์กโฟลว์ต่างๆ เอนจินการอนุมานที่สร้างขึ้นเองนี้ให้ประสิทธิภาพการประมวลผลสูงกว่าถึง 4 เท่า และความหน่วงต่ำกว่า 50% เมื่อเทียบกับระบบเซิร์ฟเวอร์โอเพนซอร์สมาตรฐาน ทำให้เป็นหนึ่งในระบบที่เร็วที่สุด AI ผู้ให้บริการ API ที่พร้อมใช้งานในปัจจุบันสำหรับการสร้างข้อมูลแบบเจเนอเรทีฟ AI ปริมาณงานการผลิต
เอนจินการประมวลผลแบบอนุมานที่เป็นกรรมสิทธิ์ของ Fireworks AI ถูกสร้างขึ้นมาตั้งแต่เริ่มต้นเพื่อความเร็วโดยเฉพาะ สามารถให้เวลาในการประมวลผลโทเค็นแรกต่ำกว่า 100 มิลลิวินาทีได้อย่างสม่ำเสมอในขนาดโมเดลที่หลากหลาย เหมาะสำหรับแอปพลิเคชันใดๆ ที่ต้องการการตอบสนองแบบเรียลไทม์ เช่น แชทบอทที่ใช้งานโดยลูกค้า หรือ ผู้ช่วยการเขียนโค้ดแบบตัวแทนข้อได้เปรียบด้านประสิทธิภาพนี้สามารถวัดผลได้และมีความสำคัญอย่างยิ่ง บริษัทต่างๆ เช่น Sourcegraph และ Notion ได้ประกาศต่อสาธารณะถึงปริมาณงานที่เพิ่มขึ้นหลังจากย้ายมาใช้แพลตฟอร์มนี้
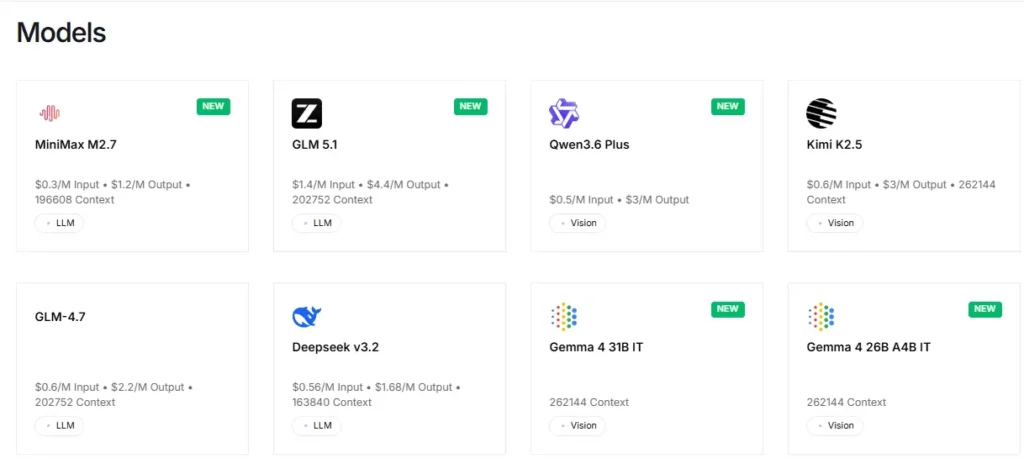
แพลตฟอร์มนี้ช่วยให้เข้าถึงโมเดลโอเพนซอร์สมากกว่า 100 โมเดลได้ทันที รวมถึง Llama, Qwen, DeepSeek, Kimi K2.5, GLM 5, Mixtral และ FLUX เครื่องกำเนิดภาพนักพัฒนาสามารถทดสอบและสลับระหว่างโมเดลต่างๆ ผ่าน API endpoint เดียวโดยไม่ต้องเปลี่ยนแปลงการตั้งค่าใดๆ ทำให้การสร้างต้นแบบอย่างรวดเร็วและการทดสอบ A/B ระหว่างตระกูลโมเดลต่างๆ มีประสิทธิภาพสูง
ดอกไม้ไฟ AI รองรับวิธีการปรับแต่งอย่างละเอียดครบวงจร รวมถึง LoRA, การปรับแต่งอย่างละเอียดแบบควบคุมพารามิเตอร์เต็มรูปแบบ, DPO (การจัดเรียงความชอบ) และการปรับแต่งอย่างละเอียดแบบเสริมแรง ที่สำคัญคือ โมเดลที่ได้รับการปรับแต่งอย่างละเอียดจะมีราคาเท่ากับโมเดลพื้นฐาน ซึ่งช่วยขจัดค่าใช้จ่ายที่สูงเกินควรที่คู่แข่งหลายรายเรียกเก็บ นอกจากนี้ยังรองรับการปรับแต่งอย่างละเอียดของโมเดลภาษาภาพ ทำให้ทีมต่างๆ สามารถปรับแต่งโมเดลมัลติโมดอลด้วยชุดข้อมูลภาพและข้อความของตนเองได้
สำหรับงานที่ต้องการทรัพยากรเฉพาะ Fireworks คือตัวเลือกที่เหมาะสม AI ข้อเสนอตามความต้องการ การใช้งาน GPU คิดค่าบริการเป็นรายวินาที ปัจจุบันฮาร์ดแวร์ที่รองรับได้แก่ GPU NVIDIA A100, H100, H200, B200 และ B300 ซึ่งช่วยให้ทีมวิศวกรรมมีความยืดหยุ่นในการเรียกใช้โมเดลแบบส่วนตัวและแยกต่างหาก พร้อมความจุที่รับประกันได้ และไม่มีปัญหาเรื่องเครื่องข้างเคียงรบกวน
Fire Pass เป็นบริการใหม่ล่าสุดที่สมัครสมาชิกสัปดาห์ละ 7 ดอลลาร์ ให้สิทธิ์การเข้าถึงโทเค็นแบบไม่จำกัดสำหรับรุ่น Kimi K2.5 Turbo ด้วยความเร็วประมาณ 200 ถึง 250 โทเค็นต่อวินาที ออกแบบมาโดยเฉพาะสำหรับนักพัฒนาที่ใช้เครื่องมือเขียนโค้ดแบบอัตโนมัติ เช่น Claude Code และ OpenCode โดยนำเสนอทางเลือกในราคาคงที่แทนการคิดค่าบริการต่อโทเค็นที่ไม่แน่นอน
ดอกไม้ไฟ AI แผนการกำหนดราคา
| ชื่อแผน | ราคา | รายละเอียดที่สำคัญ |
|---|---|---|
| เซิร์ฟเวอร์เลส (โมเดลขนาดเล็ก) | 0.10 ดอลลาร์ต่อ 1 ล้านโทเค็น | แบบจำลองภายใต้พารามิเตอร์ 4B |
| เซิร์ฟเวอร์เลส (ระดับกลาง) | 0.20 ดอลลาร์ต่อ 1 ล้านโทเค็น | พารามิเตอร์ของรุ่น 4B ถึง 16B |
| เซิร์ฟเวอร์เลส (สำหรับโมเดลขนาดใหญ่) | 0.90 ดอลลาร์ต่อ 1 ล้านโทเค็น | โมเดลที่มีพารามิเตอร์มากกว่า 16 พันล้านตัว |
| เซิร์ฟเวอร์เลส (โมเดล MoE) | ราคา 0.50 ถึง 1.20 ดอลลาร์สหรัฐต่อ 1 ล้านโทเค็น | ชั้นเรียน Mixtral การผสมผสานของแบบจำลองผู้เชี่ยวชาญ |
| ทางผ่านไฟ | $ 7 ต่อสัปดาห์ | โทเค็น Kimi K2.5 Turbo ไม่จำกัดจำนวน |
| ตามความต้องการ (H100) | ชั่วโมงการใช้งาน GPU 6.00 ดอลลาร์ | คิดค่าบริการเป็นรายวินาที สำหรับอินสแตนซ์เฉพาะ |
| ตามสั่ง (B200) | ชั่วโมงการใช้งาน GPU 9.00 ดอลลาร์ | GPU รุ่นล่าสุด คิดค่าบริการเป็นรายวินาที |
| Enterprise | แผ่นกระดาษ | ส่วนลดรายปี, ข้อตกลงระดับบริการ (SLA) และการใช้งานแบบส่วนตัว |
เริ่มต้นใช้งาน Fireworks AI กันเถอะ
- ขั้นตอนที่ 1: สร้างบัญชีที่ ดอกไม้ไฟ.aiคุณจะได้รับเครดิตฟรี 1 ดอลลาร์โดยอัตโนมัติเมื่อลงทะเบียน
- ขั้นตอนที่ 2: ไปที่ส่วน "คีย์ API" ในแดชบอร์ดของคุณ แล้วสร้างคีย์ API ใหม่
- ขั้นตอนที่ 3: ติดตั้งไคลเอ็นต์ Fireworks Python หรือใช้ OpenValue ใดก็ได้AI SDK ที่ใช้งานร่วมกันได้ ชี้ URL หลักของคุณไปยังปลายทาง API ของ Fireworks
- ขั้นตอนที่ 4: เลือกโมเดลจากคลังโมเดล เรียกใช้ API ครั้งแรก และตรวจสอบการใช้งานและค่าใช้จ่ายจากคอนโซล
ข้อดีและข้อเสีย
- ความเร็วในการประมวลผลที่เหนือกว่าผู้นำในอุตสาหกรรม
- มีโมเดลโอเพนซอร์สให้เลือกใช้มากกว่า 100 แบบ
- รวมขั้นตอนการปรับแต่งอย่างละเอียดครบถ้วน
- Fire Pass ให้บริการโทเค็นแบบไม่จำกัดจำนวน
- ฮาร์ดแวร์ GPU รุ่นล่าสุด (B300)
- สำหรับนักพัฒนาเท่านั้น ไม่ต้องเขียนโค้ด แดชบอร์ดนี้ใช้งานได้ฟรี
- ไม่มีเครื่องมือจัดการเวิร์กโฟลว์ทางธุรกิจในตัว
- การสนับสนุนลูกค้าอาจช้า
ดอกไม้ไฟที่ดีที่สุด AI ทางเลือก
| AI แพลตฟอร์มการอนุมานและการให้บริการโมเดล | ประสิทธิภาพการประมวลผลการอนุมาน | ประสิทธิภาพต้นทุน |
|---|---|---|
| ร่วมกันเอไอ | 917 TPS, ความหน่วงสูงขึ้น (0.78 วินาที) | อัตราต่อโทเค็นใกล้เคียงกัน แต่ความหลากหลายของ GPU น้อยกว่า |
| กรู | ประมวลผล 456 TPS ผ่าน LPU แบบกำหนดเอง ความหน่วง 0.19 วินาที | ราคาเริ่มต้นต่ำกว่า แต่มีรุ่นให้เลือกจำกัด |
| ทำซ้ำ | ความเร็วปานกลาง ใช้คอนเทนเนอร์ | ระบบคิดค่าบริการตามการคาดการณ์แบบง่าย ไม่ต้องปรับแต่งมากนัก |
| บาสเตน | โครงสร้างพื้นฐานที่ปรับแต่งได้ ความเร็วปานกลาง | มีความยืดหยุ่น แต่ต้องมีการตั้งค่าเพิ่มเติม |

