
Väčšina ľudí pristane na Objímajúca tvár, pozerať sa na stenu s názvami modelov a do 30 sekúnd kliknúť preč. Veľká chyba.
Zatiaľ čo sa všetci hádajú o tom, ktorý AI nástroj sa oplatí zaplatiť, desiatky tisíc staviteľov potichu používajú Hugging Face na spustenie, doladenie a loď AAplikácie s podporou I — úplne zadarmo. To's nie je to len modelová knižnica. Je to's platforma, kde Google, Meta, Mistral a sóloví vývojári pracujú v rovnakom priestore.
cez 1 milión modelov, viac ako 500 000 súborov údajov a bezplatný hosting aplikácií — pod jedným účtom. Tu's kompletný rozbor toho, čo to je a ako to vlastne používať.
Čo je to vlastne objímanie tváre (väčšina ľudí sa v tom mýli)
"GitHub strojového učeniaOznačenie „“ sa často používa. Drží sa jedného smeru – verejné repozitáre, správa verzií, príspevky komunity. Ale rýchlo sa rozpadá. Hugging Face tiež prevádzkuje živú inferenciu, hosťuje aplikácie s umelou inteligenciou a poskytuje kompletnú infraštruktúru pre školenia. GitHub nerobí nič z toho.
Samotná spoločnosť začínala ako startup zameraný na NLP chatboty, ktorý sa neskôr preorientoval na open source. AI nástroje a nikdy sa neobzrel späť. Verejná platforma is fvoľné a riadené komunitou; podnikové produkty sú spôsob, akým zarábajú peniaze. Pre začiatočníkov bezplatná úroveň pokrýva všetko, čo potrebujú. Modely sa zverejňujú tu. pred dostanú sa na titulné stránky novín – ak sa v oblasti umelej inteligencie objaví niečo nové, najprv sa to objaví na Hugging Face.
Tri piliere – poznajte ich skôr ako čokoľvek iné
Všetko na Hugging Face sa nachádza v troch základných sekciách:
| pilier | Čo to je | Prečo je to dôležité |
|---|---|---|
| Modely | 1 milión+ predškolených AI modely | Úplne preskočte tréning od začiatku |
| dátovej sady | Nespracované dáta pre tréning a testovanie | Štandardizované dáta pripravené na načítanie |
| Priestory | Bezplatné hosťovanie AI aplikácie | Testovacie modely bez dotyku kódu nasadenia |
Zoznámte sa so všetkými tromi – počas stavania sa neustále prepájajú.
Centrum modelov – miesto, kde strávite väčšinu času
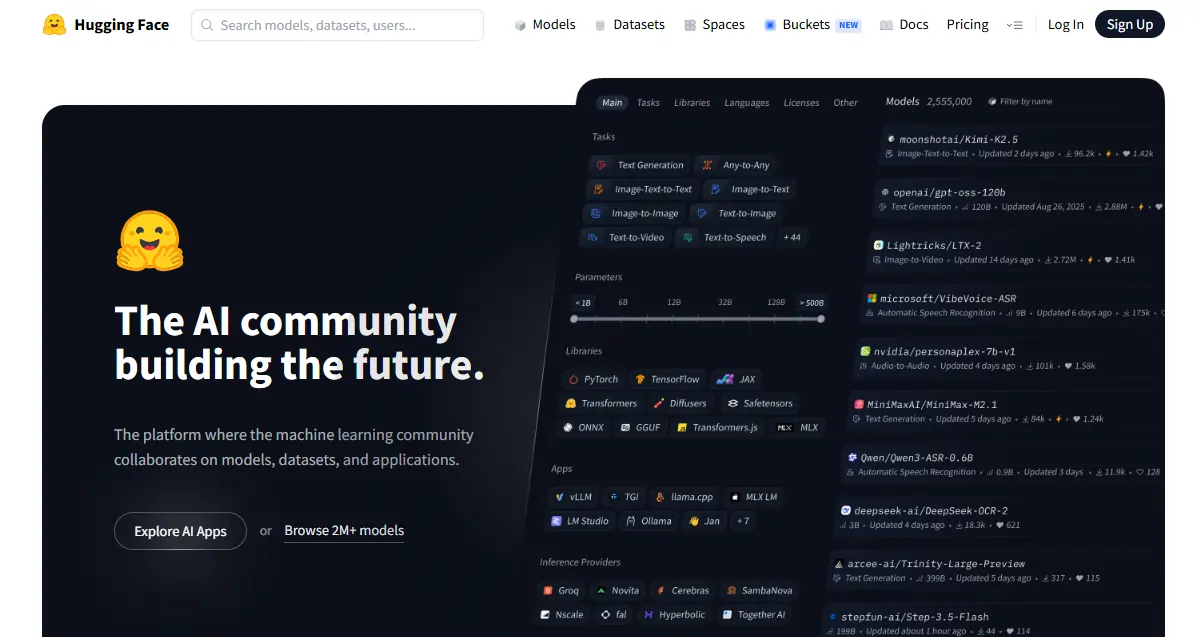
Panel filtrov je tu vaším najlepším priateľom: typ úlohy, framework (PyTorch, TensorFlow, JAX), jazyk, licencia a veľkosť modelu. Zoradiť podľa najviac stiahnuté pre overené tipy; zoradiť podľa nedávno aktualizované keď potrebujete čerstvé možnosti.
Každý model má kartu – prečítajte si ju. V časti o zamýšľanom použití sa dozviete, na čo bol model vyrobený; sekcia obmedzení vám povie, kde sa to zlomí. Táto druhá časť je cennejšia ako akékoľvek benchmarkové skóre. Kategórie modelov zahŕňajú NLP (klasifikácia textu, sumarizácia, preklad, odpovedanie na otázky), zrak (klasifikácia obrázkov, detekcia objektov, generovanie), zvuk (ASR, TTS) a multimodálne úlohy ako vizuálne odpovede na otázky.
Jedna vec, ktorú začiatočníci prehliadajú: nie všetky modely sú voľne na stiahnutie. Uzavreté modely ako napríklad meta's lama vyžadujú schválenie pred prístupom. Po schválení sa overíte pomocou prístupového tokenu. Pred zostavením si vždy skontrolujte licenciu – niektoré modely úplne zakazujú komerčné použitie.
Knižnica Transformerov — Kód bežiaci polovicu AI Svet
transformers knižnica je zjednotený Pytón balíček ktorý štandardizuje spôsob načítavania a spúšťania akéhokoľvek modelu v centre v PyTorch, TensorFlow a JAX s rovnakým API.

pipeline() funkcia je miestom, kde by mala väčšina začiatočníkov začať – zabalí tokenizáciu, načítanie modelu a následné spracovanie do jedného volania. Analýza sentimentu, generovanie textu, klasifikácia obrázkov – všetky sa riadia úplne rovnakým vzorom. V momente, keď potrebujete jemnú kontrolu nad výstupmi, prejdite na písanie vlastného inferenčného kódu. Dovtedy sa o všetko postarajú pipeline.
Nevynechávajte tokenizáciu. Nespracovaný text sa nedá vložiť priamo do modelu. AutoTokenizer spracováva konverziu a vždy automaticky priraďuje správny tokenizátor k správnemu kontrolnému bodu. Nezhodné tokenizátory spôsobujú najmätúcnejšie chyby, s ktorými sa začiatočníci stretávajú – a dá sa im na 100 % vyhnúť.
| úloha | Názov potrubia | Príklad modelu |
|---|---|---|
| Analýza sentimentu | text-classification | Distilbert-base-uncauled |
| Generovanie textu | text-generation | Mistral-7B |
| sumarizácie | summarization | facebook/bart-large-cnn |
| Rozpoznávanie reči | automatic-speech-recognition | openai/whisper-base |
| Klasifikácia obrázkov | image-classification | google/vit-base-patch16 |
Dátové súbory a priestory – dve funkcie, ktoré nikto dostatočne nevyužíva
datasets knižnica načítava dáta vo formáte Apache Arrow – rýchle, pamäťovo efektívne a vytvorené na spracovanie súborov údajov, ktoré sa nezmestia do pamäte RAM. load_dataset("name", split="train") je všetko, čo potrebujete na začiatok. Predtým, ako sa zaviažete k akejkoľvek množine údajov pre tréningový beh, použite Data Studio v prehliadači na zobrazenie ukážky a filtrovanie bez napísania jediného riadku kódu.
Priestory sú miestom, kde AI Demá sú zverejnené zadarmo. Vaša aplikácia získa zdieľateľnú URL adresu v priebehu niekoľkých minút bez nutnosti riešiť problém s DevOps. Bezplatná úroveň CPU zvládne ľahké demá; platené Spaces s podporou GPU zvládnu náročnejšie modely.
Použitie GRADIA pre rýchle ukážky modelov s minimálnym kódom; použite Streamlit keď vaša aplikácia potrebuje rozloženie dashboardu s väčším objemom dát. Najrýchlejší spôsob, ako začať, je klonovanie trendového priestoru – vyberte si jeden vo svojej kategórii, rozveďte ho a prispôsobte.
Správne nastavenie účtu
Bezplatná verzia zahŕňa prehliadanie modelov, priestory CPU, volania API s obmedzenou rýchlosťou a plný prístup komunity. Pro verzia pridáva prioritné priestory GPU, rozšírenú inferenciu a súkromné repozitáre. Pre väčšinu začiatočníkov stačí bezplatná verzia.
Vygenerujte prístupový token v rámci nastavenia → Prístupové tokenyTokeny na čítanie fungujú na sťahovanie; tokeny na zápis sú potrebné na odosielanie modelov alebo súborov údajov. Autentifikácia v Pythone pomocou huggingface_hub.login()Pre vašu inštaláciu:

tresnúť
pip install transformers datasets huggingface_hubpridať accelerate, pefta trl ak je na pláne doladenie. Google Colab je najrýchlejšie prostredie pre úplných začiatočníkov – zadarmo GPU, nie je potrebné nič lokálne konfigurovať.
Spustenie prvého modelu a jeho následné prispôsobenie
Pre analýzu sentimentu: volania pipeline("text-classification"), odovzdať reťazec, prečítať label a score späť. Pre generovanie textu: použite max_new_tokens, temperaturea do_sample kontrolovať, aký kreatívny a konzistentný je výstup. To isté pipeline() Vzor funguje na preklad, rozpoznávanie reči a klasifikáciu obrázkov – API sa nemení, nemení sa iba názov úlohy.
Keď sa veci pokazia:
Keď pochopíte základy, ďalším krokom je doladenie. Vopred trénované modely sú všeobecné; doladené modely sú presné. Doladenie eliminuje výzvy, keď pracujete s údajmi špecifickými pre danú doménu, potrebujete konzistentné správanie alebo chcete znížiť náklady na inferenciu spustením menšieho špecializovaného modelu.
PEFT zmrazí väčšinu modelu a trénuje iba ľahké adaptéry – nevyžaduje sa grafická karta s nákladom 10 000 dolárov. QLoRA Posúva to ďalej s kvantizáciou, ktorá umožňuje jemné doladenie modelu 7B parametrov na jednej spotrebiteľskej GPU.
Trainer API spravuje celú slučku – dávkovanie, vyhodnocovanie, kontrolné body – a odosielanie späť do centra trvá jeden riadok, keď skončíte.
Inferencia bez vlastného servera
Hostované Inference API vám okamžite poskytne REST endpoint pre akýkoľvek verejný model. Bezplatná úroveň je obmedzená rýchlosťou – je vhodná na testovanie, nie na produkciu. Pre skutočné aplikácie, Koncové body inferencie poskytujú vyhradené, súkromné API, ktoré sa v prípade nečinnosti automaticky škáluje na nulu, čím udržiavajú náklady zvládnuteľné pri variabilnej prevádzke.
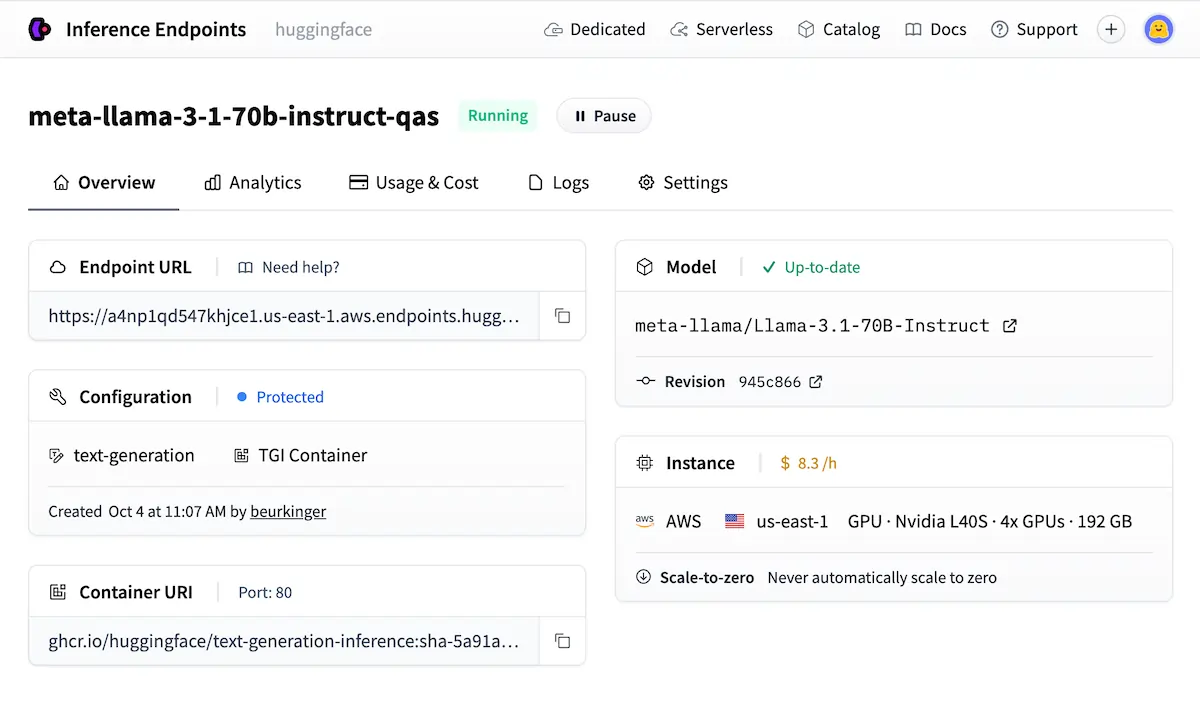
Keď je ochrana súkromia údajov alebo latencia nepodstatná, je potrebné zabezpečiť vlastné hostingové služby s... TGI (Inferencia generovania textu) or vLLM je cesta pripravená na produkciu.
Komunita, rebríčky a prečo poráža všetko ostatné
Rebríček Open LLM zoradí modely podľa benchmarku – užitočné pre užší výber, ale vždy overte skutočný prípad použitia predtým, ako dôverujete skóre. Účty organizácií umožňujú tímom spravovať zdieľané kolekcie modelov s kontrolovaným prístupom; Meta AI, Google a EleutherAI všetky účty organizácie spúšťajú priamo v centre.
Sledovanie výskumníkov a organizácií vám poskytuje aktuálny prehľad o nových modeloch bez nutnosti monitorovať sociálne médiá.
| Plošina | Open Source | Odroda modelu | Úroveň zadarmo | Nástroje na jemné doladenie |
|---|---|---|---|---|
| Objímajúca tvár | ✅ Plná | ✅ 1 milión+ | ✅ Štedrý | ✅ Plný zásobník |
| Rozbočovač TensorFlow | ✅ Áno | 🔶 Obmedzené | ✅ Áno | ❌ Základné |
| Modelová záhrada Google | ❌ Čiastočné | 🔶 Vybrané | 🔶 Iba GCP | 🔶 Iba GCP |
| OtvorenýAI API | ❌ Nie | ❌ Zatvorené | ❌ Iba platené | 🔶 Obmedzené |
Chyby, ktoré vás budú stáť hodiny
- Získanie najväčšieho modelu, keď menší, určený na špecifické úlohy, beží rýchlejšie a lacnejšie
- Preskočenie karty modelu's sekcia obmedzení predtým, ako na nej niečo vytvoríte
- Nepripínanie revízií modelu – modely sa aktualizujú ticho a výstupy sa menia bez varovania
- Používanie bezplatného rozhrania Inference API pre čokoľvek, čo vyžaduje konzistentnú prevádzkyschopnosť
- Priame odovzdávanie surového textu do modelu bez jeho predchádzajúceho spustenia cez tokenizátor
AiMojo odporúča:
Kam ísť odtiaľto
Objímajúca tvár's bezplatné kurzy at hf.co/learn pokrývajú NLP, audio a hlboké posilňovacie učenie v štruktúrovaných cestách vytvorených špeciálne pre túto platformu. Najlepší prvý projekt: doladiť textový klasifikátor na vlastnej množine údajov, zabaliť ho do Gradia a nasadiť ho ako priestor.
Toto jediné zostavenie sa dotkne modelov, súborov údajov, jemného doladenia a priestorov naraz. Akonáhle to bude's naživo, nahrajte model a napíšte správnu kartu modelu – zahŕňajúcu zamýšľané použitie, tréningové údaje a obmedzenia.
Že's ako sa vytvárajú užitočné verejné príspevky a's ako začať budovať skutočnú prítomnosť v open-source AI priestor.



 BONUS: Získajte našich 200 dolárovAI „Súprava nástrojov pre majstrovstvo“ ZADARMO pri registrácii!
BONUS: Získajte našich 200 dolárovAI „Súprava nástrojov pre majstrovstvo“ ZADARMO pri registrácii!






