Crawl4AI Основные сведения
Что такое Crawl4AI?
Crawl4AI Это бесплатная библиотека Python с открытым исходным кодом, которая преобразует веб-страницы в чистый Markdown, структурированный JSON или отфильтрованный HTML, которые могут напрямую обрабатываться большими языковыми моделями. Созданная на основе Playwright для автоматизации браузера, она предназначена для разработчиков, создающих RAG-конвейеры. AI агенты и автоматизированные рабочие процессы обработки данных. Инструмент поддерживает как стратегии извлечения данных с использованием LLM, так и стратегии без использования LLM, предоставляя командам полный контроль над затратами и качеством выходных данных.
Crawl4 имеет более 60 000 звезд на GitHub и более 900 000 ежемесячных загрузок на PyPI.AI стал одним из самых популярных инструментов для веб-скрейпинга. AI Инженерное сообщество. Работает полностью на вашей собственной инфраструктуре, поэтому не требуются ключи API и нет платы за страницу. Для команд, которым необходимо извлечение данных в производственных масштабах. автоматизация бизнеса, Crawl4AI Предлагает гибкость для подключения к любому поставщику LLM, сохраняя при этом слой обхода веб-страниц полностью бесплатным.
Crawl4AI Создает два типа выходных файлов Markdown, как описано на официальном сайте. Clean Markdown сохраняет точное форматирование страницы с заголовками, таблицами, блоками кода и подсказками по цитированию. Fit Markdown применяет эвристическую фильтрацию с помощью алгоритма отсечения или оценки релевантности BM25 для удаления шаблонного текста, навигации и лишнего содержимого нижнего колонтитула.
Этот двухканальный выход специально разработан для конвейеров RAG и прямого приема LLM-данных. Пользователи также могут создавать собственные пользовательские решения. генерация Markdown стратегии, точно соответствующие их потребностям в разработке трубопроводов.
Инструмент предоставляет два различных способа извлечения данных. Для страниц с предсказуемой структурой JsonCssExtractionStrategy, основанный на CSS и XPath, извлекает структурированный JSON, используя определения схемы, и не требует вызовов LLM.
Для сложных или непредсказуемых страниц стратегия LLMExtractionStrategy подключается к любому поставщику LLM (OpenAI, Ollama, DeepSeek и другим) и использует схемы Pydantic для возврата идеально структурированных данных. Стратегии сегментации, включая обработку на основе тем, регулярных выражений и предложений, эффективно обрабатывают большие страницы.
Адаптивное сканирование, анонсированное на crawl4ai.com как флагманская функция, использует алгоритмы поиска информации с трехуровневой системой оценки, измеряющей охват, согласованность и насыщенность. Вместо сканирования каждой страницы сайта, оно оценивает релевантность содержания на каждом этапе и автоматически останавливается при достижении пороговых значений достоверности.
Он поддерживает как статистическую стратегию (быструю, бесплатную, основанную на терминах), так и стратегию встраивания (семантическое понимание с расширением запроса). Это предотвращает избыточное сканирование и значительно экономит вычислительные ресурсы.
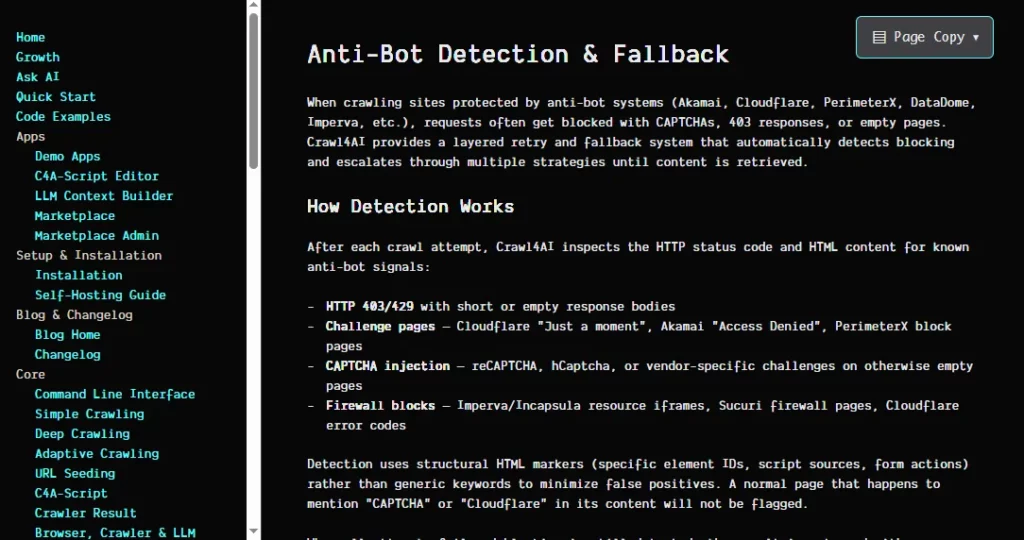
Введенная в версии 0.8.5 трехуровневая структура система обнаружения ботов Проверяет известные подписи поставщиков, общие индикаторы блокировки и структурную целостность возвращаемых страниц. При обнаружении блокировки система автоматически повторяет попытку через настраиваемую цепочку прокси-серверов с резервными функциями выборки. В сочетании со скрытым режимом, имитирующим поведение реального пользователя, и режимом невидимого браузера из версии 0.7.3, это дает Crawl4AI мощный набор инструментов для доступа к защищенным сайтам.
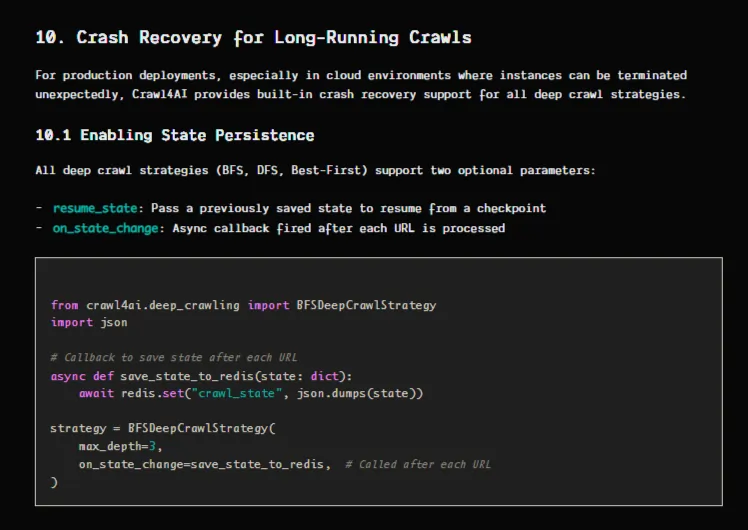
Для масштабных задач, охватывающих тысячи страниц, стратегии глубокого сканирования (BFS, DFS, Best First) включают встроенную функцию восстановления после сбоя, реализованную в версии 0.8.0. Функция обратного вызова on_state_change сохраняет состояние после каждого URL-адреса, а параметр resume_state позволяет продолжить работу с той же контрольной точки после сбоя.
В режиме предварительной загрузки полностью пропускается генерация и извлечение Markdown-кода, что позволяет обнаруживать URL-адреса в 5-10 раз быстрее, чем обычно, в двухэтапных процессах сканирования.
Crawl4AI В комплект входит оптимизированный образ Docker, включающий сервер FastAPI, аутентификацию с помощью JWT-токенов, панель мониторинга в реальном времени с актуальными системными метриками и трехуровневый пул браузеров (постоянный, горячий, холодный) с предварительным прогревом страниц. Интерактивная среда тестирования позволяет командам тестировать конфигурации сканирования и генерировать код запросов без написания скриптов.
Интеграция MCP напрямую подключается к AI Инструменты, такие как Claude Code. Поддержка нескольких архитектур с автоматическим определением AMD64 и ARM64 гарантирует работу на любом облачном провайдере.
Crawl4AI Тарифный план
| план Имя | Стоимость | Основные характеристики |
|---|---|---|
| Открытый исходный код (самостоятельное размещение) | $0 | Неограниченное количество сканирований, полный набор функций, вы предоставляете инфраструктуру. |
| Облачный API (закрытое бета-тестирование) | На заказ | Услуги по управлению сервисом, подайте заявку на ранний доступ, количество мест ограничено. |
| Спонсор "Верующий" | $ 5 / мес | Уровень поддержки сообщества: поддержите проект! |
| Строитель Спонсор | $ 50 / мес | Приоритетная поддержка и ранний доступ к новым функциям |
| Спонсор растущей команды | $ 500 / мес | Рекомендации по синхронизации и оптимизации, предоставляемые раз в две недели. |
| Партнер по инфраструктуре данных | $ 2,000 / мес | Специализированная поддержка и полное партнерство. |
Как Crawl4AI Обрабатывает генерацию Markdown?
Crawl4AI Создаются два типа выходных файлов Markdown. Raw Markdown сохраняет полную структуру страницы, включая элементы навигации и нижние колонтитулы. Fit Markdown применяет эвристическую фильтрацию с использованием алгоритма обрезки или оценки релевантности BM25 для удаления лишнего контента и сохранения только основного содержимого. Это особенно ценно для конвейеров RAG, где качество встраивания зависит от чистоты входного текста.
Вы также можете реализовать собственные стратегии генерации Markdown, расширив базовый класс, что даст вам полный контроль над тем, как HTML-элементы сопоставляются с токенами Markdown. Система цитирования преобразует ссылки на страницы в нумерованные ссылки, что помогает магистрам права отслеживать указание источника при выполнении задач поиска информации.
Плюсы и минусы
- Активное сообщество с более чем 60 000 звезд.
- Лицензия Apache 2.0 (разрешительная лицензия).
- Работает с любым поставщиком программ магистратуры в области права.
- Асинхронная архитектура для повышения скорости.
- Встроенная функция восстановления после сбоя при глубоком погружении.
- Пока нет управляемого облачного сервиса.
- Отсутствует графический интерфейс пользователя или визуальный интерфейс.
- Для защиты от ботов необходима настройка прокси-сервера.
Лучший Crawl4AI альтернативы
| AI Веб-краулер и парсер | Вариант с самостоятельным размещением | Экстракция без LLM |
|---|---|---|
| Firecrawl | Ограниченное использование (действуют ограничения AGPL 3.0) | Нет, для работы со структурированным JSON требуется степень магистра права (LLM). |
| апифай | Нет, это полностью облачная платформа. | Нет, полагается на AI модели для синтаксического анализа |
| ScrapeGraphAI | Да, это библиотека Python с открытым исходным кодом (MIT). | Нет, для каждой операции извлечения требуется звонок от специалиста по управлению учебными заведениями (LLM). |


