
Одних быстрых изменений уже недостаточно для предприятий AI Системы. По мере того, как количество окон контекста модели превышает 200 тысяч токенов, инженеры теперь обертывают LLM документами, конвейерами поиска, блокнотами и вызовами инструментов — подход, получивший название контекстная инженерия.
Сдвиг произошел быстро.
Контекстная инженерия устраняет этот пробел, рассматривая весь AI охрана окружающей среды как систему, а не сосредотачиваясь на отдельных вкладах.
Контекстная инженерия:
Система, которая действительно работает
Контекстное проектирование рассматривает весь процесс до получения степени магистра права (LLM) как инженерную инфраструктуру. Представьте себе LLM.'s контекстное окно как ОЗУ — имеет ограниченную рабочую память, которая определяет, что может обработать модель.
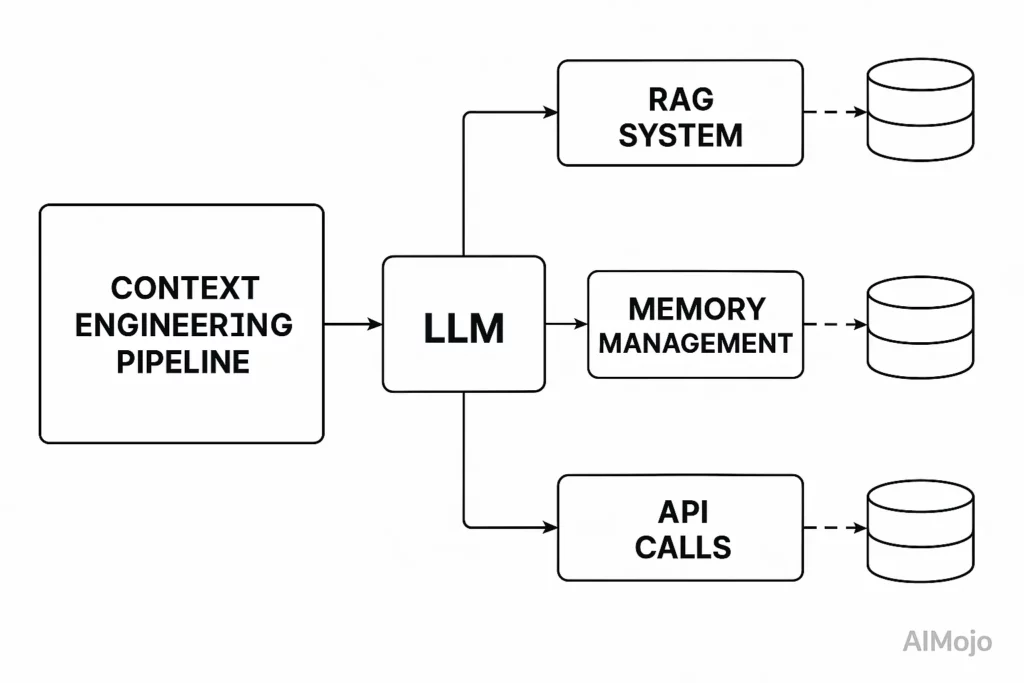
Так же, как операционная система тщательно управляет тем, что попадает в оперативную память, контекстная инженерия контролирует, какая информация заполняет память LLM's контекстное окно.
Здесь's что на самом деле включает в себя контекстная инженерия:
Контекстная инженерия против оперативной инженерии:
Цифры не лгут
| Аспект | Быстрый инжиниринг | Контекстная инженерия |
|---|---|---|
| Фокус | Создание одной входной строки | Организация каждого сигнала вокруг модели |
| Среднее время разработки | 70% быстрых доработок | 60% конвейеров данных, 20% правил памяти, 20% подсказок |
| Типичный вид отказа | Внезапное падение качества выходных данных из-за дрейфа данных | Устойчивость благодаря RAG, памяти, вызовам инструментов |
Быстрый пример: бот поддержки клиентов Обученный только на подсказках бот может вспомнить политику возврата, если его спросить напрямую. Когда пользователь упоминает «заказ 45791», он не срабатывает. Добавьте контекстную инженерию — историю разговоров и запрос RAG в базу данных заказов — и бот мгновенно извлечет информацию о покупке и порекомендует правильный способ возврата.
Четыре столпа контекстной инженерии, которые действительно имеют значение
1. Написание контекста (ваш ИИ)'s Система ведения заметок)
Написание контекста означает сохранение информации за пределами контекстное окно Для использования в будущем. Это позволяет сохранить ценное место на токенах, сохраняя при этом доступ к важным данным.
Блокноты Работает как конспектирование для агентов в течение одного сеанса.'s многоагентный исследователь сохраняет свой первоначальный план в «Память«потому что если контекст превышает 200,000 XNUMX токенов, он обрезается и план теряется.

Долгосрочные воспоминания Сохранение информации в течение нескольких сеансов. Примеры включают автоматическую генерацию пользовательских настроек ChatGPT на основе разговоров и обучение курсору/Windsurf. шаблоны кодирования и контекст проекта.

2. Выбор контекста (искусство выбора важного)
Выбор контекста позволяет получить только необходимую информацию для решения поставленной задачи.
Когда AI тренер по фитнесу генерирует план тренировки, он должен выбрать контекстные данные, которые включают пользователя's рост, вес и уровень активности, игнорируя нерелевантную информацию.
Ключевое понимание: Больше информации не всегда значит лучше. Эффективное проектирование контекста подразумевает выбор правильной комбинации для каждой конкретной задачи.
3. Сжатие контекста (втиснуть больше в меньшее)
Когда разговоры становятся настолько длинными, что выходят за рамки LLM's Память В этом окне сжатие контекста становится критически важным. Агенты обычно добиваются этого, суммируя предыдущие фрагменты разговора.

4. Изоляция контекста (разделяй и властвуй)
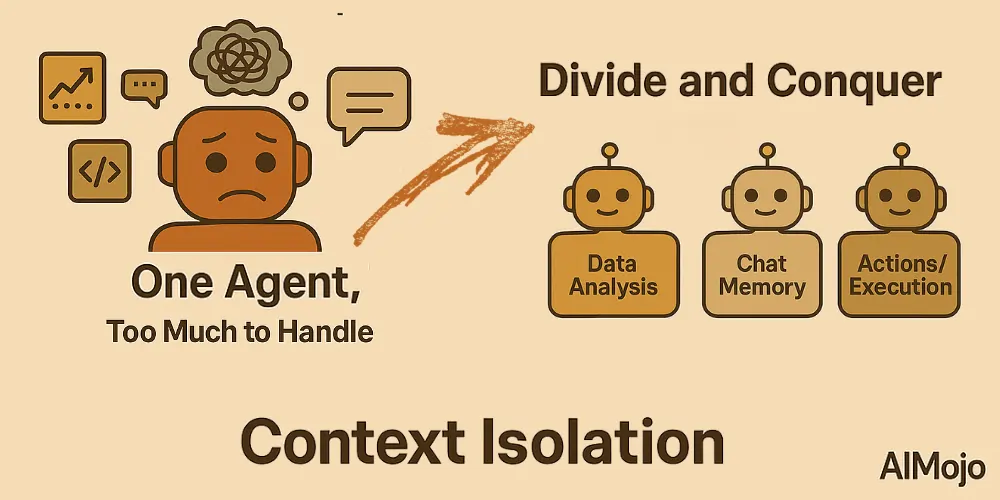
Изоляция контекста означает разбиение информации на отдельные фрагменты, чтобы агенты могли лучше справляться со сложными задачами. Вместо того, чтобы впихивать все знания в одну большую подсказку, разработчики распределяют контекст между специализированными подагентами или изолированные среды.
Реальная контекстная инженерия в действии
Революция в обслуживании клиентов
| До контекстной инженерии | После контекстной инженерии |
|---|---|
| Обычные чат-боты, которые забывают предыдущие разговоры и дают нерелевантные ответы. | AI агенты, которые запоминают историю ваших покупок, имеют доступ к данным о запасах в режиме реального времени и при необходимости координируют свои действия с агентами-людьми. |
Помощник по программированию, который никогда не забывает
Система: Когда вы спрашиваете: «Как исправить эту ошибку аутентификации?», система проектирования контекста автоматически:

Вместо общих советов по кодированию вы получаете конкретные решения, адаптированные к вашей реальной кодовой базе.
Техническая архитектура, лежащая в основе контекстной инженерии
Динамическая сборка контекста
Контекст формируется на ходу, развиваясь по мере развития разговора. Он включает в себя:
- Получение соответствующих документов
- Поддержание памяти
- Обновление состояния пользователя
- API-вызовы и запросы к базе данных
Управление контекстным окном
С фиксированным размером лимиты токенов (32K, 100K, 1M), инженеры должны разумно сжимать и приоритизировать информацию, используя:
- Оценочные функции (TF-IDF, встраивание, эвристика внимания)
- Резюмирование и извлечение значимости
- Стратегии фрагментации и настройка перекрытия

Безопасность и последовательность
Применяйте такие принципы, как быстрое обнаружение инъекции, очистка контекста, Редакция PIIи управление контекстным доступом на основе ролей.
Создание вашей первой системы контекстной инженерии
Создание рабочего процесса контекстной инженерии — это не просто теория.'s повторяемый процесс, который можно операционализировать и даже автоматизировать. Вот как это можно реализовать на практике:
Шаг 1: Составьте карту своих контекстных источников
Определите, откуда вашему агенту необходимо извлекать информацию (документы, базы данных, API, предыдущие чаты и т. д.).
питон
# Example: Fetching relevant documents using embeddings
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer("all-MiniLM-L6-v2")
query = "project status update"
corpus = ["spec doc", "requirements", "last week's meeting notes"]
query_embedding = model.encode(query, convert_to_tensor=True)
corpus_embeddings = model.encode(corpus, convert_to_tensor=True)
hits = util.semantic_search(query_embedding, corpus_embeddings, top_k=2)[0]
relevant_docs = [corpus[hit['corpus_id']] for hit in hits]
Шаг 2: Реализовать память и контекст письма
Сохраняйте важную информацию, чтобы она всегда была под рукой для будущих задач.
питон
import json
def save_to_memory(memory_path, user_id, data):
with open(memory_path, "r+") as file:
memory = json.load(file)
memory[user_id] = data
file.seek(0)
json.dump(memory, file)
file.truncate()Шаг 3: Логика выбора контекста и сжатия сборки
Разрабатывайте правила или модели, которые выбирают только то, что наиболее актуально для задачи. Сжимайте длинные истории в краткие формы.
питон
def summarize_conversation(history):
# Placeholder for use with an LLM summarizer or custom rules
return history[-5:] # Only the last 5 messagesШаг 4: Изолируйте контексты для координации агентов
Разделите информацию, чтобы каждый агент или компонент обрабатывал только то, что ему следует.
питон
user_profile_ctx = {"user_goals": "..."}
task_specific_ctx = {"current_task": "..."}
external_data_ctx = {"live_data": "..."}
full_context = {**user_profile_ctx, **task_specific_ctx, **external_data_ctx}Шаг 5: Структурирование выходных данных и готовность API
Форматируйте выходной контекст последовательно, чтобы он's предсказуемо для нисходящих вызовов LLM или конечных точек API.
питон
schema = {
"user": {"age": 35, "goal": "muscle gain"},
"plan": "high protein, 3x/week weight training"
}Шаг 6: Мониторинг, итерация и обеспечение безопасности
Отслеживайте сбои, проверяйте качество контекста и улучшайте логику включения, запоминания и извлечения контекста. Всегда проверяйте входные данные, чтобы избежать немедленного ввода и утечек данных.
Почему контекстная инженерия выгоднее оперативной инженерии
Компаниям нужны инженеры, способные создавать системы, обеспечивающие ИИ правильный контекст, обеспечивающие точность и актуальность информации и защищающие пользователей путем добавления правил безопасности.
Реальность рынка: Контекстное проектирование требует кросс-функциональных навыков, включающих понимание вариантов использования в бизнесе, определение результатов и структурирование информации, чтобы LLM могли выполнять сложные задачи.
Итог: Написать подсказки может каждый. Создание контекстно-зависимых агентов, которые запоминают, адаптируются и выбирают контекст в любом масштабе? Именно так разработчики обеспечивают будущее своих навыков и создают реальную ценность с помощью продвинутых приложений LLM.



 БОНУС: Получите наши 200 долларов “AI «Мастерский набор инструментов» БЕСПЛАТНО при регистрации!
БОНУС: Получите наши 200 долларов “AI «Мастерский набор инструментов» БЕСПЛАТНО при регистрации!



![7 лучших бесплатных AI Генераторы людей в 2026 году [Обзор и рейтинг]](https://aimojo.io/wp-content/uploads/2023/11/Best-Free-AI-Human-Generator-100x100.webp)


