Focuri de artificii AI Insights cheie
Ce este Fireworks AI?
Artificii AI este o platformă de inferență de înaltă performanță, special concepută pentru dezvoltatori și companii care au nevoie să ruleze, să ajusteze și să scaleze tehnologii open source. AI modele la viteză de producție. Fondată de foști membri ai echipei PyTorch de la Meta, platforma oferă o platformă deschisăAI API compatibilă care oferă acces la peste 100 de modele populare de limbaj mare, modele de vizualizare și modele de generare de imagini.
Focuri de artificii AI elimină povara operațională a gestionării infrastructurii GPU oferind opțiuni de implementare atât fără server, cât și la cerere. Companiile utilizează Fireworks AI pentru a alimenta chatboții, asistenți de codare, motoare de căutare și agenție AI fluxuri de lucru. Motorul său de inferență personalizat oferă un randament de până la 4 ori mai mare și o latență cu 50% mai mică decât stivele standard de servire open source, ceea ce îl face unul dintre cele mai rapide AI Furnizori de API disponibili astăzi pentru generativ AI sarcini de lucru de producție.
Motorul de inferență proprietar al Fireworks AI este construit de la zero pentru viteză. Acesta oferă în mod constant o latență a primului token sub 100 de milisecunde pe o gamă largă de dimensiuni de model. Pentru orice aplicație care necesită răspuns în timp real, cum ar fi chatboții orientați către client sau asistenți de codare agentică, acest avantaj de performanță este măsurabil și semnificativ. Companii precum Sourcegraph și Notion au remarcat public creșteri ale randamentului după migrarea către platformă.
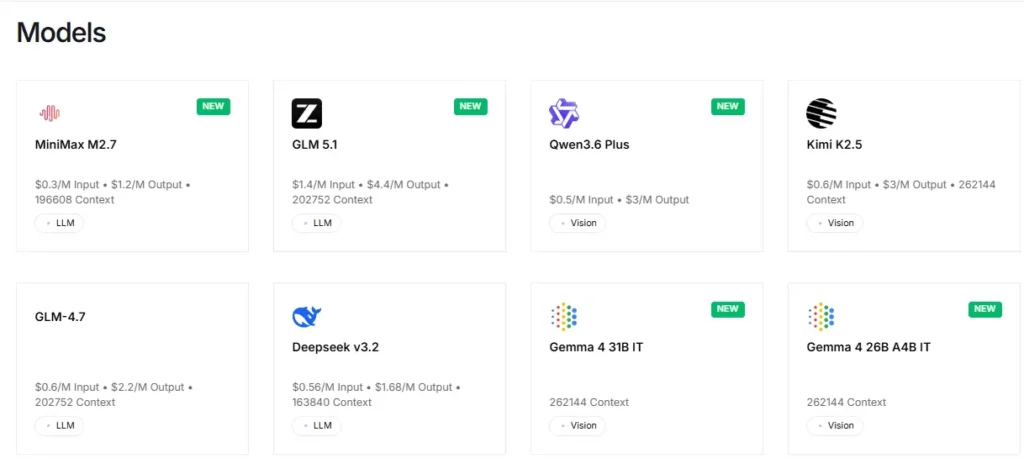
Platforma oferă acces instantaneu la peste 100 de modele open source, inclusiv Llama, Qwen, DeepSeek, Kimi K2.5, GLM 5, Mixtral și FLUX. generatoare de imaginiDezvoltatorii pot testa și schimba între modele printr-un singur punct final API, fără modificări de configurație. Acest lucru face ca prototiparea rapidă și testarea A/B în cadrul familiilor de modele să fie extrem de eficiente.
Focuri de artificii AI Acceptă întreaga gamă de metode de reglare fină, inclusiv LoRA, reglarea fină supravegheată complet de parametri, DPO (alinierea preferințelor) și reglarea fină a armăturilor. Este esențial faptul că modelele reglate fin sunt oferite la același preț ca modelele de bază, eliminând penalizarea de cost pe care o impun mulți concurenți. De asemenea, este acceptată reglarea fină a modelului de limbaj vizual, permițând echipelor să personalizeze modelele multimodale cu propriile seturi de date de imagine și text.
Pentru sarcini de lucru care necesită resurse dedicate, Fireworks AI oferte la cerere Implementări GPU facturat pe secundă. Gama de hardware include acum GPU-uri NVIDIA A100, H100, H200, B200 și B300. Acest lucru oferă echipelor de inginerie flexibilitatea de a rula instanțe de model private, izolate, cu capacitate garantată și fără probleme legate de vecinii zgomotoși.
O adăugare recentă, Fire Pass este un abonament de 7 dolari pe săptămână care oferă acces nelimitat la modelul Kimi K2.5 Turbo prin intermediul token-urilor, la viteze cuprinse între 200 și 250 de token-uri pe secundă. Este conceput special pentru dezvoltatorii care utilizează instrumente de codare agentică precum Claude Code și OpenCode, oferind o alternativă forfetară la facturarea imprevizibilă per token.
Focuri de artificii AI Planuri tarifare
| Numele planului | Costat | Detalii cheie |
|---|---|---|
| Serverless (Modele mici) | 0.10 USD per 1 milion de jetoane | Modele sub parametrii 4B |
| Fără server (nivel mediu) | 0.20 USD per 1 milion de jetoane | Parametrii modelelor 4B până la 16B |
| Fără server (modele mari) | 0.90 USD per 1 milion de jetoane | Modele cu parametri peste 16B |
| Fără server (modele MoE) | 0.50 USD până la 1.20 USD per 1 milion de token-uri | Modele de amestec de experți din clasa Mixtral |
| Pasul de Foc | 7 $ pe săptămână | Jetoane Kimi K2.5 Turbo nelimitate |
| La cerere (H100) | 6.00 USD pe oră GPU | Facturat pe secundă, instanță dedicată |
| La cerere (B200) | 9.00 USD pe oră GPU | GPU de ultimă generație, facturat pe secundă |
| Enterprise | pachet personalizat | Reduceri anuale, acorduri de nivel de serviciu și implementări private |
Noțiuni introductive despre Fireworks AI
- Pasul 1: Creați un cont la artificii.aiVei primi automat 1 dolar în credite gratuite la înscriere.
- Pasul 2: Navigați la secțiunea Chei API din tabloul de bord și generați o nouă cheie API.
- Pasul 3: Instalați clientul Fireworks Python sau utilizați orice aplicație OpenAI SDK compatibil. Indică adresa URL de bază către punctul final al API-ului Fireworks.
- Pasul 4: Alegeți un model din biblioteca de modele, efectuați primul apel API și monitorizați utilizarea și facturarea din consolă.
Argumente pro şi contra
- Viteză de inferență de top în industrie.
- Peste 100 de modele open source disponibile.
- Include conductă completă de reglare fină.
- Fire Pass oferă jetoane nelimitate.
- Hardware GPU de ultimă generație (B300).
- Tablou de bord gratuit, doar pentru dezvoltatori, fără cod.
- Fără instrumente de flux de lucru încorporate.
- Asistența pentru clienți poate fi lentă.
Cele mai bune artificii AI Alternative
| AI Platformă de inferență și servire a modelelor | Randamentul inferenței | Eficiența costurilor |
|---|---|---|
| Împreună AI | 917 TPS, latență mai mare (0.78 s) | Rate similare per token, mai puțină varietate de GPU-uri |
| Groq | 456 TPS prin LPU-uri personalizate, latență de 0.19 s | Preț de intrare mai mic, selecție limitată de modele |
| replicate | Viteză moderată, bazată pe containere | Facturare simplă per predicție, mai puține ajustări fine |
| Baseten | Infrastructură personalizabilă, viteză moderată | Flexibil, dar necesită mai multă configurare |

