
Ajustes rápidos por si só não são mais suficientes para as empresas AI sistemas. À medida que as janelas de contexto do modelo ultrapassam 200 mil tokens, os engenheiros agora envolvem o LLM com documentos, pipelines de recuperação, blocos de anotações e chamadas de ferramentas — uma abordagem marcada engenharia de contexto.
A mudança aconteceu rápido.
A engenharia de contexto preenche essa lacuna ao tratar todo o AI meio Ambiente como um sistema em vez de focar em contribuições individuais.
Engenharia de Contexto:
O sistema que realmente funciona
A engenharia de contexto trata todo o pipeline antes da chamada do LLM como uma infraestrutura engenheirável. Pense em um LLM's janela de contexto como RAM – ela tem memória de trabalho limitada que determina o que o modelo pode processar.
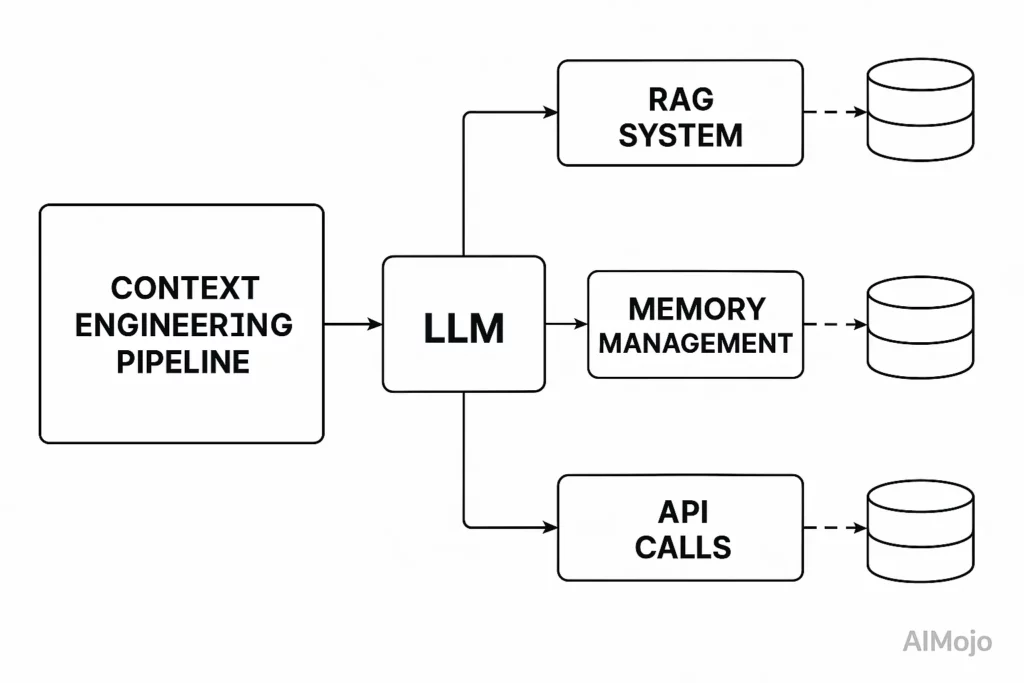
Assim como um sistema operacional gerencia cuidadosamente o que vai para a RAM, a engenharia de contexto seleciona quais informações preenchem o LLM's janela de contexto.
Aqui você encontra's o que a engenharia de contexto realmente inclui:
Engenharia de Contexto vs Engenharia de Prompt:
Os números não mentem
| Aspecto | Engenharia imediata | Engenharia de Contexto |
|---|---|---|
| Foco | Criando uma string de entrada | Orquestrando cada sinal em torno do modelo |
| Tempo médio de desenvolvimento | 70% de ajustes rápidos | 60% pipelines de dados, 20% regras de memória, 20% prompts |
| Modo de falha típico | Queda repentina na qualidade da saída após desvio de dados | Resiliente via RAG, memória, chamadas de ferramentas |
Exemplo rápido: UMA bot de suporte ao cliente Treinados apenas com prompts, conseguem lembrar a política de reembolso quando questionados diretamente. Quando o usuário menciona "pedido 45791", a resposta falha. Adicione engenharia de contexto — histórico de conversas mais uma consulta RAG no banco de dados de pedidos — e o bot instantaneamente extrai os detalhes da compra e recomenda o processo de reembolso correto.
Os quatro pilares da engenharia de contexto que realmente importam
1. Contexto de escrita (sua IA's Sistema de anotações)
Escrever contexto significa salvar informações fora do contexto janela de contexto para uso futuro. Isso preserva o valioso espaço do token, mantendo o acesso a dados importantes.
Blocos de rascunho funcionam como anotações para agentes em uma única sessão. Antrópico's pesquisador multiagente salva seu plano inicial para “Memória"porque se o contexto exceder 200,000 tokens, ele será truncado e o plano será perdido.

Memórias de longo prazo retêm informações em várias sessões. Exemplos incluem o ChatGPT, que gera automaticamente as preferências do usuário a partir de conversas, e o aprendizado do Cursor/Windsurf. padrões de codificação e contexto do projeto.

2. Seleção de Contexto (A Arte de Escolher o que Importa)
A seleção de contexto traz apenas as informações relevantes para a tarefa em questão.
Quando um AI preparador físico gera um plano de treino, ele deve selecionar detalhes de contexto que incluam o usuário's altura, peso e nível de atividade, ignorando informações irrelevantes.
O insight principal: Mais informação nem sempre é melhor. Uma engenharia de contexto eficaz significa selecionar a combinação certa para cada tarefa específica.
3. Compressão de contexto (encaixando mais em menos)
Quando as conversas se tornam tão longas que ultrapassam o LLM's memória janela, a compressão de contexto torna-se crítica. Os agentes normalmente fazem isso resumindo partes anteriores da conversa.

4. Isolamento de contexto (dividir e conquistar)
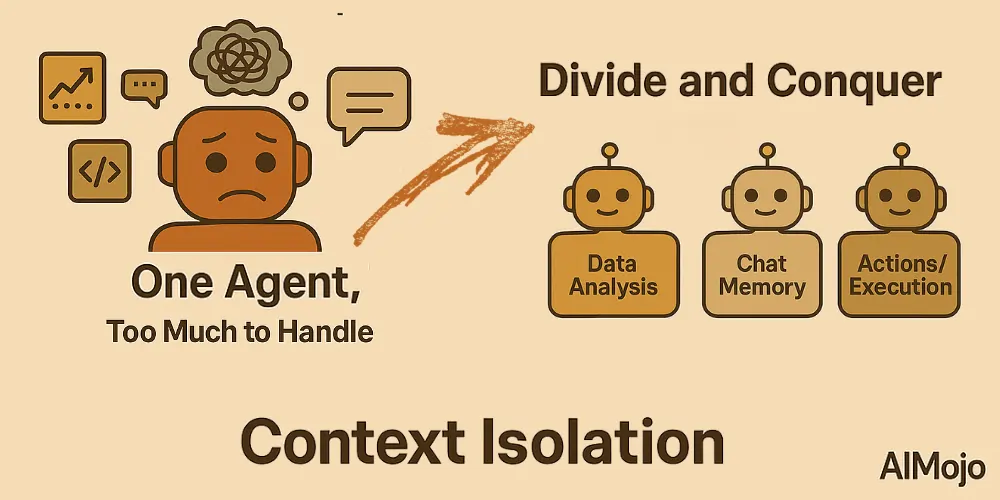
Isolamento de contexto significa dividir as informações em partes separadas para que os agentes possam lidar melhor com tarefas complexas. Em vez de acumular todo o conhecimento em um único prompt enorme, os desenvolvedores dividem o contexto entre subagentes especializados ou ambientes em área restrita.
Engenharia de contexto do mundo real em ação
A Revolução do Atendimento ao Cliente
| Antes da engenharia de contexto | Após a engenharia de contexto |
|---|---|
| Chatbots genéricos que esquecem conversas anteriores e fornecem respostas irrelevantes. | AI agentes que lembram seu histórico de compras, acessam dados de estoque em tempo real e coordenam com agentes humanos quando necessário. |
O assistente de codificação que nunca esquece
O sistema:Quando você pergunta “Como faço para corrigir esse bug de autenticação?”, o sistema de engenharia de contexto automaticamente:

Em vez de conselhos genéricos sobre codificação, você obtém soluções específicas adaptadas à sua base de código real.
A arquitetura técnica que impulsiona a engenharia de contexto
Montagem de Contexto Dinâmico
O contexto é construído dinamicamente, evoluindo conforme as conversas progridem. Isso inclui:
- Recuperando documentos relevantes
- Manter a memória
- Atualizando o estado do usuário
- Chamadas de API e consultas de banco de dados
Gerenciamento de janela de contexto
Com tamanho fixo limites de token (32K, 100K, 1M), os engenheiros devem compactar e priorizar as informações de forma inteligente usando:
- Funções de pontuação (TF-IDF, embeddings, heurísticas de atenção)
- Sumarização e extração de saliência
- Estratégias de fragmentação e ajuste de sobreposição

Segurança e Consistência
Aplicar princípios como detecção rápida de injeção, sanitização de contexto, Redação de PIIe controle de acesso ao contexto baseado em funções.
Construindo seu primeiro sistema de engenharia de contexto
Construir um fluxo de trabalho de engenharia de contexto não é apenas teoria―é's Um processo repetível que pode ser operacionalizado e até automatizado. Veja como você pode colocá-lo em prática:
Passo 1: Mapeie suas fontes de contexto
Identifique de onde seu agente precisa extrair informações (documentos, bancos de dados, APIs, chats anteriores, etc.).
python
# Example: Fetching relevant documents using embeddings
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer("all-MiniLM-L6-v2")
query = "project status update"
corpus = ["spec doc", "requirements", "last week's meeting notes"]
query_embedding = model.encode(query, convert_to_tensor=True)
corpus_embeddings = model.encode(corpus, convert_to_tensor=True)
hits = util.semantic_search(query_embedding, corpus_embeddings, top_k=2)[0]
relevant_docs = [corpus[hit['corpus_id']] for hit in hits]
Passo 2: Implementar contexto de memória e escrita
Armazene informações importantes para que elas estejam sempre disponíveis para tarefas futuras.
python
import json
def save_to_memory(memory_path, user_id, data):
with open(memory_path, "r+") as file:
memory = json.load(file)
memory[user_id] = data
file.seek(0)
json.dump(memory, file)
file.truncate()Passo 3: Construir lógica de seleção e compressão de contexto
Desenvolva regras ou modelos que selecionem apenas o que é mais relevante para a tarefa. Comprima históricos longos em formatos resumidos.
python
def summarize_conversation(history):
# Placeholder for use with an LLM summarizer or custom rules
return history[-5:] # Only the last 5 messagesPasso 4: Isolar contextos para coordenação de agentes
Divida as informações para que cada agente ou componente cuide apenas do que deve.
python
user_profile_ctx = {"user_goals": "..."}
task_specific_ctx = {"current_task": "..."}
external_data_ctx = {"live_data": "..."}
full_context = {**user_profile_ctx, **task_specific_ctx, **external_data_ctx}Passo 5: Estruturação de saída e prontidão da API
Formate o contexto de saída de forma consistente para que's previsível para chamadas LLM downstream ou endpoints de API.
python
schema = {
"user": {"age": 35, "goal": "muscle gain"},
"plan": "high protein, 3x/week weight training"
}Passo 6: Monitorar, iterar e proteger
Rastreie falhas, audite a qualidade do contexto e aprimore a lógica para inclusão, memória e recuperação de contexto. Sempre higienize as entradas para evitar injeção de prompts e vazamentos de dados.
Por que a engenharia de contexto paga mais do que a engenharia de prompt
As empresas precisam de engenheiros que possam criar sistemas que forneçam o contexto certo para a IA, mantenham as informações precisas e atualizadas e protejam os usuários adicionando diretrizes de segurança.
A realidade do mercado:A engenharia de contexto requer habilidades multifuncionais que envolvem a compreensão de casos de uso de negócios, a definição de saídas e a estruturação de informações para que os LLMs possam realizar tarefas complexas.
Bottom line: Qualquer pessoa pode escrever prompts. Construir agentes sensíveis ao contexto que memorizam, adaptam e selecionam contexto em escala? É assim que os desenvolvedores preparam suas habilidades para o futuro e entregam valor real com aplicativos avançados de LLM.



 BONUS: Receba nossos $ 200 “AI “Kit de ferramentas de domínio” GRÁTIS ao se inscrever!
BONUS: Receba nossos $ 200 “AI “Kit de ferramentas de domínio” GRÁTIS ao se inscrever!






