Sztuczne ognie AI Kluczowe spostrzeżenia
Czym jest Fireworks AI?
Fajerwerki AI to wydajna platforma wnioskowania stworzona specjalnie dla deweloperów i przedsiębiorstw, które muszą uruchamiać, dostrajać i skalować oprogramowanie typu open source AI Modele z prędkością produkcyjną. Założona przez byłych członków zespołu PyTorch w Meta, platforma zapewnia otwarteAI zgodny interfejs API zapewniający dostęp do ponad 100 popularnych dużych modeli językowych, modeli wizji i modeli generowania obrazów.
Sztuczne ognie AI Eliminuje obciążenie operacyjne związane z zarządzaniem infrastrukturą GPU, oferując opcje wdrażania bezserwerowego i na żądanie. Firmy korzystają z Fireworks AI do zasilania chatbotów, asystenci kodowania, wyszukiwarek i agentów AI przepływy pracy. Jego autorski silnik wnioskowania zapewnia do 4 razy wyższą przepustowość i o 50% niższe opóźnienia niż standardowe stosy serwerów open source, co czyni go jednym z najszybszych AI Dostawcy API dostępni obecnie dla generatywnych AI obciążenia produkcyjne.
Opatentowany silnik inferencyjny Fireworks AI został stworzony od podstaw z myślą o szybkości. Zapewnia on stałe opóźnienie pierwszego tokena poniżej 100 milisekund w szerokim zakresie rozmiarów modeli. Dla każdej aplikacji wymagającej reakcji w czasie rzeczywistym, takiej jak chatboty obsługujące klienta lub… asystenci kodowania agentówTa przewaga wydajnościowa jest mierzalna i znacząca. Firmy takie jak Sourcegraph i Notion publicznie odnotowały wzrost przepustowości po migracji na platformę.
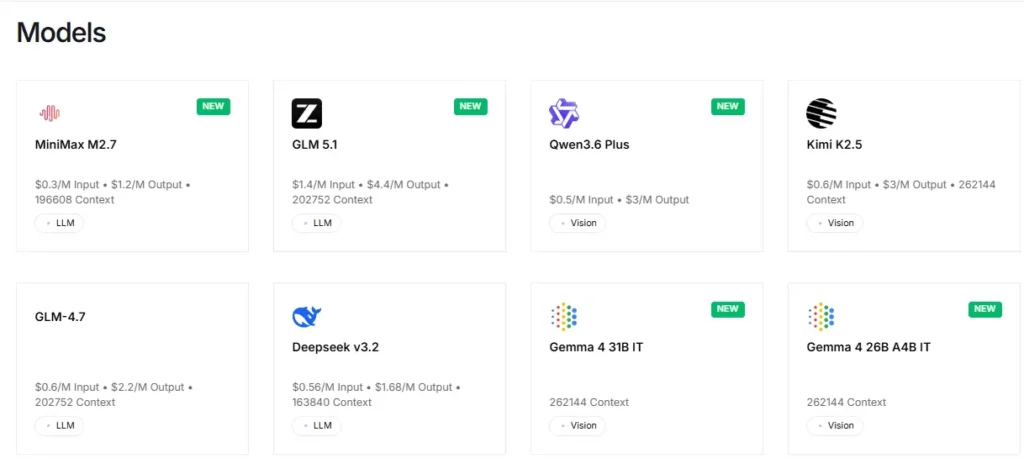
Platforma zapewnia natychmiastowy dostęp do ponad 100 modeli open source, w tym Llama, Qwen, DeepSeek, Kimi K2.5, GLM 5, Mixtral i FLUX generatory obrazówProgramiści mogą testować i przełączać się między modelami za pośrednictwem jednego punktu końcowego API bez konieczności zmiany konfiguracji. Dzięki temu szybkie prototypowanie i testy A/B w różnych rodzinach modeli są niezwykle wydajne.
Sztuczne ognie AI Obsługuje pełen zakres metod precyzyjnego dostrajania, w tym LoRA, precyzyjne dostrajanie z pełnym nadzorem parametrów, DPO (wyrównanie preferencji) oraz precyzyjne dostrajanie wzmocnień. Co istotne, modele precyzyjnie dostrojone są oferowane w tej samej cenie, co modele bazowe, co eliminuje dodatkowe koszty, które narzuca wielu konkurentów. Obsługiwane jest również precyzyjne dostrajanie modeli języka wizji, co pozwala zespołom dostosowywać modele multimodalne do własnych zestawów danych graficznych i tekstowych.
W przypadku obciążeń wymagających dedykowanych zasobów program Fireworks AI oferty na żądanie Wdrożenia GPU Rozliczane sekundowo. Oferta sprzętowa obejmuje teraz procesory graficzne NVIDIA A100, H100, H200, B200 i B300. Daje to zespołom inżynierskim elastyczność w uruchamianiu prywatnych, odizolowanych instancji modelowych z gwarantowaną pojemnością i bez problemów z sąsiedztwem.
Niedawno dodany Fire Pass to subskrypcja w cenie 7 dolarów tygodniowo, która zapewnia nieograniczony dostęp do tokenów w modelu Kimi K2.5 Turbo z prędkością około 200–250 tokenów na sekundę. Został on zaprojektowany specjalnie dla programistów korzystających z narzędzi do kodowania agentowego, takich jak Claude Code i OpenCode, oferując alternatywę w postaci stałej stawki dla nieprzewidywalnego rozliczenia za token.
Sztuczne ognie AI Plany taryfowe
| Nazwa planu | Koszty: | Kluczowe Szczegóły |
|---|---|---|
| Bezserwerowe (małe modele) | 0.10 USD za 1 mln tokenów | Modele o parametrach 4B |
| Bezserwerowy (średni poziom) | 0.20 USD za 1 mln tokenów | Parametry modeli 4B do 16B |
| Bezserwerowe (duże modele) | 0.90 USD za 1 mln tokenów | Modele o parametrach powyżej 16 mld |
| Bezserwerowe (modele MoE) | Od 0.50 do 1.20 USD za 1 mln tokenów | Mieszane modele klasy mieszanej ekspertów |
| Przepustka Ognista | 7 $ tygodniowo | Nieograniczone tokeny Kimi K2.5 Turbo |
| Na żądanie (H100) | 6.00 USD za godzinę GPU | Rozliczane sekundowo, dedykowana instancja |
| Na żądanie (B200) | 9.00 USD za godzinę GPU | Najnowsza generacja procesora graficznego, rozliczana sekundowo |
| Enterprise | warunki indywidualne | Roczne rabaty, umowy SLA i wdrożenia prywatne |
Wprowadzenie do Fireworks AI
- Krok 1: Załóż konto w fajerwerki.aiPo rejestracji automatycznie otrzymasz 1 dolara w formie darmowych kredytów.
- Krok 2: Przejdź do sekcji Klucze API na pulpicie nawigacyjnym i wygeneruj nowy klucz API.
- Krok 3: Zainstaluj klienta Fireworks Python lub użyj dowolnego OpenAI zgodny zestaw SDK. Skieruj swój adres URL bazowy do punktu końcowego API Fireworks.
- Krok 4: Wybierz model z biblioteki modeli, wykonaj pierwsze wywołanie API i monitoruj wykorzystanie oraz rozliczenia z poziomu konsoli.
Plusy i minusy
- Najwyższa w branży szybkość wnioskowania.
- Ponad 100 dostępnych modeli open source.
- W zestawie pełen proces dostrajania.
- Fire Pass oferuje nieograniczoną liczbę żetonów.
- Najnowsza generacja sprzętu GPU (B300).
- Tylko dla programistów, panel sterowania bez konieczności pisania kodu.
- Brak wbudowanych narzędzi do zarządzania przepływem pracy w firmie.
- Obsługa klienta może być powolna.
Najlepsze fajerwerki AI Podobne produkty
| AI Platforma wnioskowania i obsługi modeli | Przepustowość wnioskowania | Efektywność kosztowa |
|---|---|---|
| Razem AI | 917 TPS, wyższe opóźnienie (0.78 s) | Podobne stawki za token, mniejsza różnorodność GPU |
| Groq | 456 TPS przez niestandardowe jednostki LPU, opóźnienie 0.19 s | Niższa cena początkowa, ograniczony wybór modeli |
| Replika | Umiarkowana prędkość, oparta na kontenerach | Proste rozliczanie na podstawie przewidywań, mniej dostrajania |
| Baseten | Możliwość dostosowania infrastruktury, umiarkowana prędkość | Elastyczny, ale wymaga większej konfiguracji |

