
Szybkie poprawki same w sobie nie wystarczą już w przypadku przedsiębiorstw AI W miarę jak okna kontekstu modelu przekraczają 200 tys. tokenów, inżynierowie opakowują teraz LLM w dokumenty, potoki pobierania, notatniki i wywołania narzędzi – podejście znane jako inżynieria kontekstowa.
Zmiana nastąpiła szybko.
Inżynieria kontekstowa niweluje tę lukę, traktując całość AI środowisko jako system, a nie skupiając się na poszczególnych danych wejściowych.
Inżynieria kontekstu:
System, który naprawdę działa
Inżynieria kontekstowa traktuje cały proces przed wywołaniem LLM jako infrastrukturę inżynieryjną. Wyobraź sobie LLM.'s okno kontekstowe jako pamięć RAM – ma ograniczoną pamięć roboczą, która określa, co model może przetworzyć.
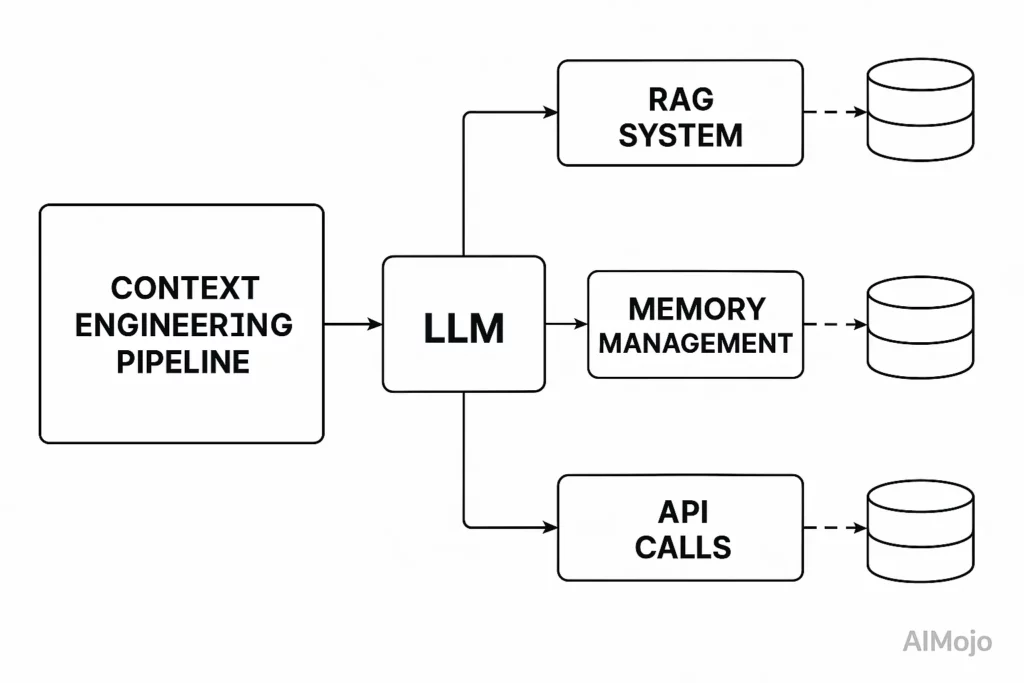
Podobnie jak system operacyjny starannie zarządza tym, co trafia do pamięci RAM, inżynieria kontekstowa wybiera informacje, które wypełniają LLM's okno kontekstowe.
Tutaj's co właściwie obejmuje inżynieria kontekstu:
Inżynieria kontekstowa kontra inżynieria podpowiedzi:
Liczby nie kłamią
| WYGLĄD | Szybka inżynieria | Inżynieria kontekstowa |
|---|---|---|
| Skupiać | Tworzenie jednego ciągu wejściowego | Orkiestracja każdego sygnału wokół modelu |
| Średni czas rozwoju | 70% szybkich poprawek | 60% potoków danych, 20% reguł pamięci, 20% monitów |
| Typowy tryb awarii | Nagły spadek jakości wyjściowej po dryfcie danych | Odporny poprzez RAG, pamięć, wywołania narzędzi |
Szybki przykład: bot obsługi klienta Bot, który został przeszkolony wyłącznie z monitów, potrafi przywołać zasady zwrotu, gdy zostanie o to bezpośrednio zapytany. Gdy użytkownik odwołuje się do „zamówienia 45791”, bot nie zwraca zwrotu. Dodaj inżynierię kontekstową – historię konwersacji i zapytanie RAG do bazy danych zamówień – a bot natychmiast pobierze szczegóły zakupu i zaleci właściwy proces zwrotu.
Cztery filary inżynierii kontekstu, które naprawdę mają znaczenie
1. Pisanie kontekstu (Twoja sztuczna inteligencja)'s System robienia notatek)
Pisanie kontekstu oznacza zapisywanie informacji poza kontekstem okno kontekstowe do wykorzystania w przyszłości. Pozwala to zachować cenną przestrzeń tokenów, a jednocześnie zachować dostęp do ważnych danych.
Brudnopisy działa jak robienie notatek dla agentów w ramach jednej sesji. Antropiczny's badacz wieloagentowy zapisuje swój początkowy plan w „Pamięć„ponieważ jeśli kontekst przekracza 200,000 XNUMX tokenów, zostaje on obcięty, a plan utracony.

Pamięć długotrwała Zachowywanie informacji w wielu sesjach. Przykładami są automatyczne generowanie preferencji użytkownika przez ChatGPT na podstawie rozmów oraz uczenie się kursora/windsurfingu. wzorce kodowania i kontekst projektu.

2. Wybór kontekstu (sztuka wybierania tego, co ważne)
Wybór kontekstu pozwala na wyświetlanie tylko informacji istotnych dla danego zadania.
Kiedy AI trener fitnessu generuje plan treningowy, musi wybrać szczegóły kontekstu, które obejmują użytkownika's wzrost, wagę i poziom aktywności, ignorując przy tym informacje nieistotne.
Kluczowa informacja:Więcej informacji nie zawsze znaczy lepiej. Skuteczna inżynieria kontekstu oznacza dobór odpowiedniej kombinacji do każdego konkretnego zadania.
3. Kompresja kontekstu (zmieszczenie większej ilości w mniejszej ilości)
Kiedy rozmowy stają się tak długie, że przekraczają LLM's pamięć W oknie kompresja kontekstu staje się kluczowa. Agenci zazwyczaj osiągają to poprzez podsumowanie wcześniejszych części konwersacji.

4. Izolacja kontekstu (dziel i zwyciężaj)
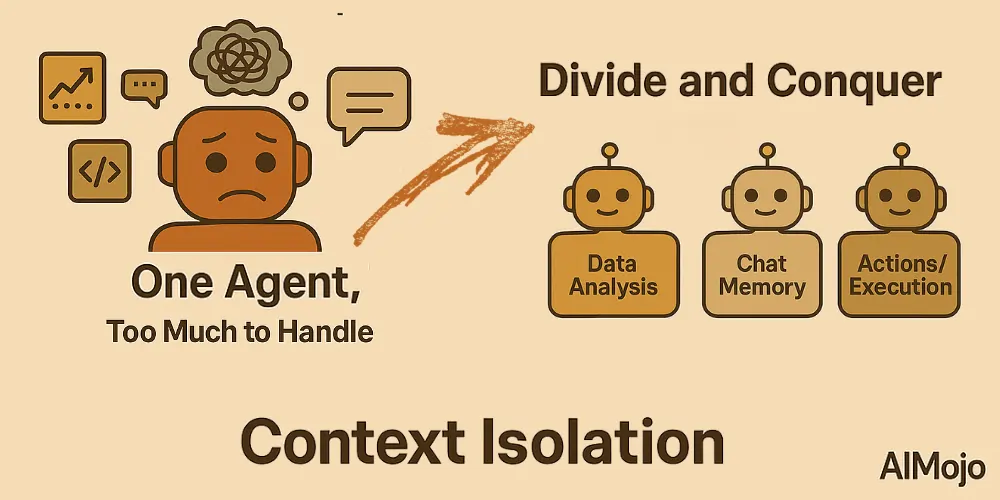
Izolacja kontekstu oznacza rozbicie informacji na oddzielne części, aby agenci mogli lepiej radzić sobie ze złożonymi zadaniami. Zamiast upychać całą wiedzę w jednym, ogromnym monicie, programiści dzielą kontekst na wyspecjalizowane podagencje lub środowiska piaskownicowe.
Inżynieria kontekstu rzeczywistego w działaniu
Rewolucja w obsłudze klienta
| Przed inżynierią kontekstową | Po inżynierii kontekstowej |
|---|---|
| Ogólne chatboty, które zapominają o poprzednich rozmowach i udzielają nieistotnych odpowiedzi. | AI agenci, którzy zapamiętują historię Twoich zakupów, mają dostęp do danych o stanie magazynowym w czasie rzeczywistym i w razie potrzeby współpracują z agentami. |
Asystent kodowania, który nigdy nie zapomina
System:Gdy zapytasz „Jak naprawić ten błąd uwierzytelniania?”, system inżynierii kontekstu automatycznie:

Zamiast ogólnych porad dotyczących kodowania otrzymujesz konkretne rozwiązania dostosowane do Twojej rzeczywistej bazy kodu.
Architektura techniczna, która napędza inżynierię kontekstu
Dynamiczny montaż kontekstu
Kontekst jest tworzony na bieżąco i ewoluuje w miarę rozwoju rozmów. Obejmuje to:
- Pobieranie odpowiednich dokumentów
- Utrzymywanie pamięci
- Aktualizowanie stanu użytkownika
- Wywołania API i zapytania do bazy danych
Zarządzanie oknem kontekstowym
Z ustalonym rozmiarem limity tokenów (32 tys., 100 tys., 1 mln) – inżynierowie muszą inteligentnie kompresować i ustalać priorytety informacji, korzystając z:
- Funkcje punktowe (TF-IDF, osadzenia, heurystyka uwagi)
- Podsumowanie i ekstrakcja saliencji
- Strategie fragmentacji i dostrajanie nakładania się

Bezpieczeństwo i spójność
Zastosuj zasady takie jak szybkie wykrywanie wstrzyknięć, dezynfekcja kontekstu, Redakcja PIIi kontrola dostępu do kontekstu oparta na rolach.
Zbuduj swój pierwszy system inżynierii kontekstu
Tworzenie przepływu pracy inżynierii kontekstu to nie tylko teoria – to's Powtarzalny proces, który można zoperacjonalizować, a nawet zautomatyzować. Oto jak możesz go wdrożyć w praktyce:
Krok 1: Zaplanuj źródła kontekstu
Określ, skąd agent powinien pobierać informacje (dokumenty, bazy danych, API, poprzednie czaty itp.).
pyton
# Example: Fetching relevant documents using embeddings
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer("all-MiniLM-L6-v2")
query = "project status update"
corpus = ["spec doc", "requirements", "last week's meeting notes"]
query_embedding = model.encode(query, convert_to_tensor=True)
corpus_embeddings = model.encode(corpus, convert_to_tensor=True)
hits = util.semantic_search(query_embedding, corpus_embeddings, top_k=2)[0]
relevant_docs = [corpus[hit['corpus_id']] for hit in hits]
Krok 2: Wdrażanie kontekstu pamięci i pisania
Przechowuj ważne informacje, aby zawsze były pod ręką na wypadek przyszłych zadań.
pyton
import json
def save_to_memory(memory_path, user_id, data):
with open(memory_path, "r+") as file:
memory = json.load(file)
memory[user_id] = data
file.seek(0)
json.dump(memory, file)
file.truncate()Krok 3: Zbuduj logikę wyboru kontekstu i kompresji
Opracuj reguły lub modele, które wybierają tylko te elementy, które są najbardziej istotne dla danego zadania. Skompresuj długie historie do postaci streszczonych.
pyton
def summarize_conversation(history):
# Placeholder for use with an LLM summarizer or custom rules
return history[-5:] # Only the last 5 messagesKrok 4: Wyizoluj konteksty do koordynacji agentów
Podziel informacje tak, aby każdy agent lub komponent zajmował się tylko tym, czym powinien.
pyton
user_profile_ctx = {"user_goals": "..."}
task_specific_ctx = {"current_task": "..."}
external_data_ctx = {"live_data": "..."}
full_context = {**user_profile_ctx, **task_specific_ctx, **external_data_ctx}Krok 5: Strukturyzacja wyników i gotowość API
Sformatuj kontekst wyjściowy w sposób spójny, aby's przewidywalne dla dalszych wywołań LLM lub punktów końcowych API.
pyton
schema = {
"user": {"age": 35, "goal": "muscle gain"},
"plan": "high protein, 3x/week weight training"
}Krok 6: Monitoruj, iteruj i zabezpieczaj
Śledź awarie, audytuj jakość kontekstu i ulepszaj logikę uwzględniania kontekstu, pamięci i pobierania. Zawsze czyść dane wejściowe, aby uniknąć szybkiego wstrzyknięcia i wycieków danych.
Dlaczego inżynieria kontekstowa jest bardziej opłacalna niż inżynieria natychmiastowa
Firmy potrzebują inżynierów, którzy potrafią tworzyć systemy zapewniające właściwy kontekst dla sztucznej inteligencji, dbać o dokładność i aktualność informacji oraz chronić użytkowników poprzez dodawanie wytycznych dotyczących bezpieczeństwa.
Rzeczywistość rynkowa:Inżynieria kontekstu wymaga umiejętności wielofunkcyjnych, które obejmują zrozumienie przypadków użycia w biznesie, definiowanie wyników i strukturyzowanie informacji, aby LLM-y mogły realizować złożone zadania.
Podsumowując: Każdy może pisać podpowiedzi. Tworzenie agentów zależnych od kontekstu, które zapamiętują, adaptują i wybierają kontekst na dużą skalę? W ten sposób programiści rozwijają swoje umiejętności i dostarczają rzeczywistą wartość dzięki zaawansowanym aplikacjom LLM.



 BONUS: Odbierz nasze 200 dolarówAI „Zestaw narzędzi Mastery Toolkit” GRATIS po rejestracji!
BONUS: Odbierz nasze 200 dolarówAI „Zestaw narzędzi Mastery Toolkit” GRATIS po rejestracji!






