
LLM API pricing in 2026 ranges from $0.10 to $30 per million tokens. That gap isn't a rounding error — it's the difference between a $200/month bill and a $9,000/month one for the same workload. This guide covers AI API dla programistów who are building real production apps, not weekend prototypes. No free-tier hobby tools here — if that's what you need, check the free AI APIs guide first.
What you'll get here: a hard look at cost, capability, and reliability across the APIs that actually matter when users are hitting your endpoints at 3AM.
Quick-Pick Guide — Best AI API by Developer Type
| Typ programisty | Najlepszy wybór | Czemu |
|---|---|---|
| Solo / indie hacker | Gemini Flash + DeepSeek V3.2 | Low cost, generous limits |
| Uruchomienie SaaS | GPT-5.4 mini or Claude Sonnet 4.6 | Quality + reliability balance |
| Enterprise / regulated | AWS Bedrock / Azure OpenAI | SLA, compliance, data residency |
| High-volume pipeline | DeepSeek V3.2 via OpenRouter | Cheapest at scale |
| Coding / dev tools | Sonet Claude'a 4.6 | Best coding benchmark in 2026 |
| Multimodal apps | Bliźnięta 2.5 Pro | Unified vision + text endpoint |
The 3-Factor Framework Before You Pick Any AI API
Before you commit to a provider, run every option through these three filters:
| Czynnik | Co mierzyć | Czerwona flaga |
|---|---|---|
| Koszty: | Input/output token rates, context pricing tiers, batch discounts | No published pricing page |
| Zdolność | Benchmark scores, context window, multimodal support | Vague “coming soon” features |
| Niezawodność | Uptime SLA, p99 latency, rate limit transparency | No public status page |
If a provider can't pass all three, it doesn't belong in your production stack — regardless of how good the demos look.
2026 AI API Pricing Breakdown — What You're Actually Paying Per Million Tokens
This is where most developers get surprised. Here's how the market splits in 2026:
Tier 1 — Frontier Models (Premium Pricing)
These are the most capable but hit your budget the hardest:
Tier 2 — Mid-Range Models (Best Price-Performance)
The sweet spot for most SaaS products:
Tier 3 — Budget & Open-Weight APIs
This is where high-volume pipelines live:
Full Pricing Reference Table:
| Provider | Model | Input (per 1M) | Output (per 1M) | Okno kontekstowe | Poziom bezpłatny |
|---|---|---|---|---|---|
| OpenAI | GPT-5.4 | $2.50 | $15.00 | 128 tysięcy | Nie |
| OpenAI | GPT-5.4 mini | $0.75 | $3.00 | 128 tysięcy | Ograniczony |
| Antropiczny | Sonet Claude'a 4.6 | $3.00 | $15.00 | 200 tysięcy | Nie |
| Bliźnięta 2.5 Pro | $ $ 1.25 2.50- | $10.00 | 1M | Tak | |
| Błysk Bliźniąt | $0.15 | $0.60 | 1M | Tak | |
| DeepSeek | V3.2 | $0.28 | $1.10 | 64 tysięcy | Ograniczony |
| Groq | Lama 4 Maverick | $0.20 | $0.60 | 128 tysięcy | Tak |
| Razem AI | Różne | od $0.90 | od $0.90 | Różnie | Tak |
Capability Comparison — Which API Actually Does the Job
Not every model is built for the same task. Picking the wrong one for your use case means paying more for worse results.
Best for General-Purpose / Chat
???? OtwarteAI GPT-5.4 — Still the strongest all-around benchmark performer in 2026. If your app needs consistent quality across diverse prompts, this is the default.
Best for Coding Tasks
???? Sonet Claude'a 4.6 — Outperforms GPT on generowanie kodu and multi-step reasoning tasks. The 200K context window means it can handle full codebases without chunking.
Best for Long-Context / Document Processing
???? Błysk Bliźniąt — Cheapest per-token for long-context reads. If you're processing legal docs, transcripts, or large knowledge bases, this is the only sensible option at scale.
Best for High-Volume / Agentic Pipelines
???? DeepSeek V3.2 + MiniMax M2.5 as cheap defaults with a premium fallback pattern. For pipelines doing 50K+ calls/day, this routing setup cuts costs by 10x–50x.
Best for Multimodal (Text + Vision + Audio)
???? Gemini 2.5 Pro via Google Vertex AI — One unified endpoint for text, vision, and audio. No stitching together separate APIs.
Use-Case Routing Reference:
| Przypadek użycia | Recommended API | Czemu |
|---|---|---|
| General chat/assistant | GPT-5.4 | Best all-around quality |
| Generowanie kodu | Sonet Claude'a 4.6 | Top coding benchmarks, large context |
| Long document processing | Błysk Bliźniąt | Cheapest at 1M token context |
| Rurociągi o dużej objętości | DeepSeek V3.2 | 90% cheaper at scale |
| Multimodal apps | Bliźnięta 2.5 Pro | Unified text + vision + audio |
Reliability in 2026 — Uptime Numbers That Actually Matter
Uptime percentages sound boring until your app goes down during peak traffic. Here's what those numbers mean in real time:
Dla production SaaS with real users, even 4 hours of downtime is a customer support nightmare. But uptime alone isn't the full story.
p99 latency is the metric most developers sleep on. If your p50 latency is 400ms but p99 is 4,000ms — that means 1 in 100 requests takes 10 seconds. Users don't care about your average. They notice the slow ones.
A healthy provider benchmark:
Run a 24-hour load test before committing any provider to production. What looks stable in a 5-minute test can collapse under sustained traffic.
Reliability Quick Reference:
| Provider | Gwarantowana dostępność | Rate Limit Transparency | Strona ze statusem publicznym |
|---|---|---|---|
| OpenAI | 99.9% | udokumentowane | Tak |
| Antropiczny | 99.9% | udokumentowane | Tak |
| Wierzchołek Google | 99.95% | udokumentowane | Tak |
| DeepSeek | ~% 99.5 | Częściowa | Tak |
| Groq | 99.9% | udokumentowane | Tak |
| Razem AI | 99.5% | Częściowa | Tak |
How Top Developers Use 2–3 APIs, Not One
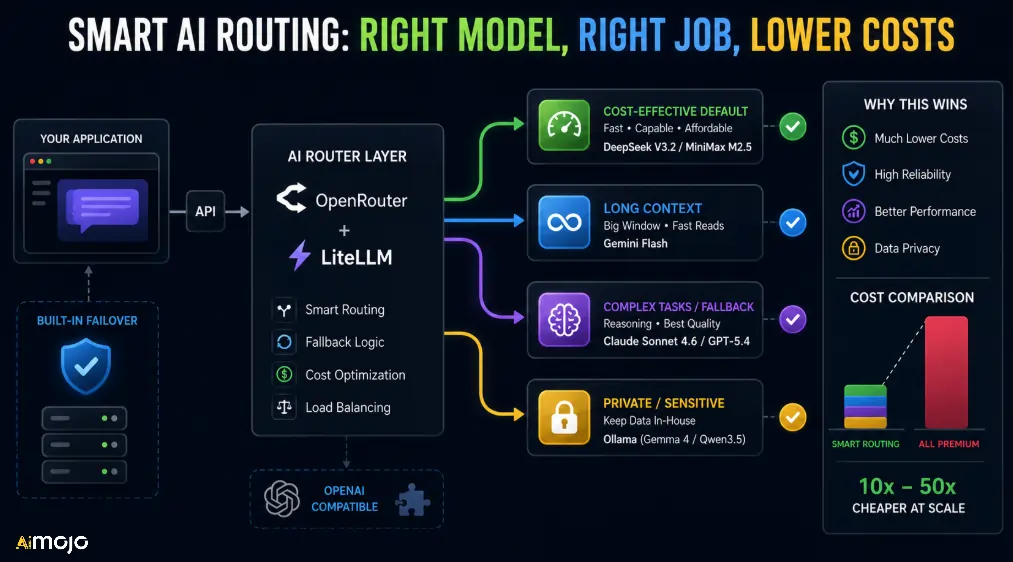
Locking into a single AI API provider in 2026 is like having a single server with no failover. Here's the routing pattern that's becoming the production standard:
- Default traffic → DeepSeek V3.2 or MiniMax M2.5 (cheapest capable model)
- Long-context reads → Gemini Flash
- Complex tasks / fallback → Claude Sonnet 4.6 or GPT-5.4
- Private or sensitive workloads → Local inference via Ollama (Gemma 4 / Qwen3.5)
Tools that make this easy: OtwórzRouter for unified model access, LiteLLM for a self-hosted routing layer with fallback logic. Both support drop-in Zgodny z OpenAI endpoints so you're not rewriting your API calls.
The cost difference between a “cheap default + premium fallback” setup vs. routing everything through GPT-5.4 can be 10x–50x per month na wadze.
Hidden Costs Most Developers Ignore
The per-token rate on the pricing page is never the full story.
FAQs Related to Developer AI Pszczoła
Co jest najtańsze AI API for production use in 2026?
DeepSeek V3.2 at $0.28/1M input tokens is currently the cheapest production-viable option. Groq with Llama 4 Maverick is close behind at $0.20/1M with faster inference speeds.
Który AI API has the highest uptime SLA?
Wierzchołek Google AI offers a 99.95% uptime SLA, putting it ahead of OpenAI and Anthropic's 99.9% commitments for enterprise workloads.
How do I calculate my monthly AI API cost before going live?
Estimate average prompt length + response length in tokens, multiply by your expected daily call volume, then apply the provider's input/output token rates. Most providers now offer cost calculators — use them before you commit.
Is DeepSeek API reliable enough for production?
It works well for non-critical or high-volume default traffic in a multi-provider routing setup. For mission-critical workloads where downtime is unacceptable, use it as a primary with a more reliable fallback like GPT-5.4 or Claude.
Co's Różnica między AI API rate limits and context limits?
Rate limits cap how many requests you can send per minute or day. Context limits cap how much text a single request can include. Both affect how you architect your app — don't confuse them.
Czy mogę użyć wielu AI APIs together in one app?
Yes, and most production setups in 2026 do exactly that. Tools like OpenRouter and LiteLLM make multi-provider routing straightforward with minimal code changes.
Który AI API is best for building a coding assistant?
Claude Sonnet 4.6 leads on coding benchmarks in 2026, with a 200K context window that handles real-world codebases without chunking.
AiMojo poleca:


![10 najlepszych sprzątaczy AI Alternatywy z czatem NSFW [lipiec 2026]](https://aimojo.io/wp-content/uploads/2024/01/Best-Janitor-AI-Alternatives-450x338.webp)
 BONUS: Odbierz nasze 200 dolarówAI „Zestaw narzędzi Mastery Toolkit” GRATIS po rejestracji!
BONUS: Odbierz nasze 200 dolarówAI „Zestaw narzędzi Mastery Toolkit” GRATIS po rejestracji!







