Fyrverkeri AI Nøkkelinnsigelser
Hva er fyrverkeri AI?
Fyrverkeri AI er en høytytende inferensplattform spesialbygd for utviklere og bedrifter som trenger å kjøre, finjustere og skalere åpen kildekode AI modeller i produksjonshastighet. Plattformen ble grunnlagt av tidligere medlemmer av PyTorch-teamet hos Meta, og tilbyr en åpenAI kompatibelt API som gir tilgang til over 100 populære store språkmodeller, visjonsmodeller og bildegenereringsmodeller.
Fyrverkeri AI eliminerer den driftsmessige byrden ved å administrere GPU-infrastruktur ved å tilby både serverløse og distribusjonsalternativer på forespørsel. Bedrifter bruker Fireworks AI å drive chatboter, kodeassistenter, søkemotorer og agenter AI arbeidsflyter. Den spesialbygde inferensmotoren leverer opptil 4 ganger høyere gjennomstrømning og 50 % lavere latens enn standard åpen kildekode-serverstabler, noe som gjør den til en av de raskeste AI API-leverandører tilgjengelig i dag for generativ AI produksjonsarbeidsmengder.
Fireworks AIs proprietære inferensmotor er bygget fra grunnen av for hastighet. Den leverer konsekvent første token-forsinkelse på under 100 millisekunder på tvers av et bredt spekter av modellstørrelser. For enhver applikasjon som krever sanntidsrespons, for eksempel kundevendte chatboter eller agentkodingsassistenter, denne ytelsesfordelen er målbar og betydelig. Selskaper som Sourcegraph og Notion har offentlig notert seg gjennomstrømningsøkninger etter migreringen til plattformen.
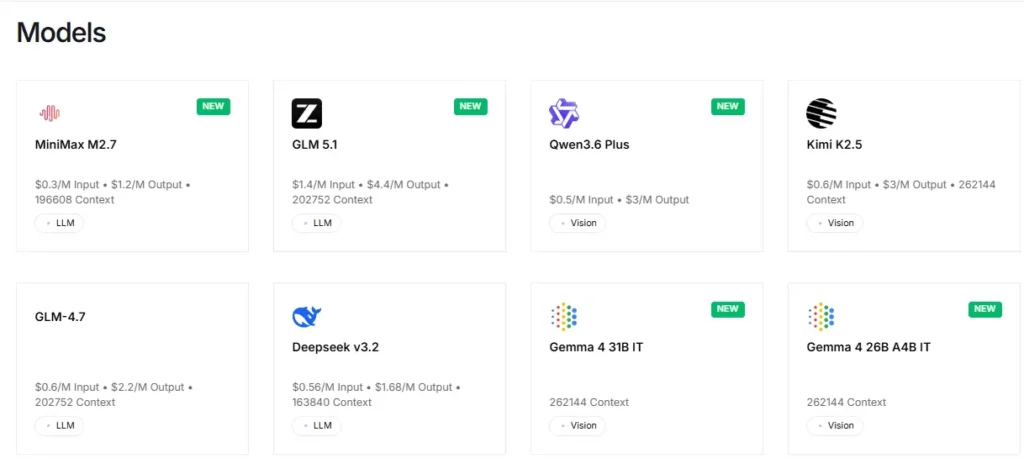
Plattformen gir umiddelbar tilgang til mer enn 100 modeller med åpen kildekode, inkludert Llama, Qwen, DeepSeek, Kimi K2.5, GLM 5, Mixtral og FLUX. bildegeneratorerUtviklere kan teste og bytte mellom modeller gjennom et enkelt API-endepunkt uten konfigurasjonsendringer. Dette gjør rask prototyping og A/B-testing på tvers av modellfamilier ekstremt effektiv.
Fyrverkeri AI støtter hele spekteret av finjusteringsmetoder, inkludert LoRA, fullstendig parameterovervåket finjustering, DPO (preferansejustering) og forsterkningsfinjustering. Det er viktig at finjusterte modeller leveres til samme pris som basismodeller, noe som fjerner kostnadsstraffen som mange konkurrenter påfører. Finjustering av visjonsspråkmodeller støttes også, slik at team kan tilpasse multimodale modeller med sine egne bilde- og tekstdatasett.
For arbeidsmengder som krever dedikerte ressurser, Fireworks AI tilbud på forespørsel GPU-distribusjoner fakturert per sekund. Maskinvareutvalget inkluderer nå NVIDIA A100, H100, H200, B200 og B300 GPU-er. Dette gir ingeniørteam fleksibiliteten til å kjøre private, isolerte modellforekomster med garantert kapasitet og uten problemer med støyende naboer.
Fire Pass er et nylig tillegg, et abonnement på 7 dollar per uke som gir ubegrenset token-tilgang til Kimi K2.5 Turbo-modellen med hastigheter rundt 200 til 250 tokens per sekund. Det er spesielt utviklet for utviklere som bruker agentiske kodeverktøy som Claude Code og OpenCode, og tilbyr et flatprisalternativ til uforutsigbar fakturering per token.
Fyrverkeri AI Prisplaner
| Plan Navn | Kostnad | viktige detaljer |
|---|---|---|
| Serverløs (små modeller) | $0.10 per 1 million tokens | Modeller under 4B-parametere |
| Serverløs (mellomnivå) | $0.20 per 1 million tokens | Parametre for modell 4B til 16B |
| Serverløs (store modeller) | $0.90 per 1 million tokens | Modeller over 16B parametere |
| Serverløs (MoE-modeller) | $0.50 til $1.20 per 1 million tokens | Mixtral klasse blanding av ekspertmodeller |
| Brannpass | $ 7 per uke | Ubegrensede Kimi K2.5 Turbo-poletter |
| På forespørsel (H100) | 6.00 dollar per GPU-time | Fakturert per sekund, dedikert instans |
| På forespørsel (B200) | 9.00 dollar per GPU-time | Siste generasjons GPU, fakturert per sekund |
| Enterprise | Custom | Årlige rabatter, tjenestenivåavtaler og private implementeringer |
Komme i gang med fyrverkeri AI
- Trinn 1: Opprett en konto på fyrverkeri.aiDu vil automatisk motta $1 i gratis kreditter når du registrerer deg.
- Trinn 2: Naviger til API-nøkler-delen i dashbordet ditt og generer en ny API-nøkkel.
- Trinn 3: Installer Fireworks Python-klienten eller bruk en hvilken som helst åpen programvare.AI kompatibel SDK. Pek basis-URL-en din til Fireworks API-endepunktet.
- Trinn 4: Velg en modell fra modellbiblioteket, utfør ditt første API-kall, og overvåk bruk og fakturering fra konsollen.
Fordeler og ulemper
- Bransjeledende inferenshastighet.
- 100+ modeller med åpen kildekode tilgjengelig.
- Full finjusteringsrørledning inkludert.
- Fire Pass tilbyr ubegrensede tokens.
- Nyeste generasjon GPU-maskinvare (B300).
- Kun for utviklere, intet kodefritt dashbord.
- Ingen innebygde verktøy for arbeidsflyt for bedrifter.
- Kundesupporten kan være treg.
Beste fyrverkeri AI Alternatives
| AI Plattform for servering av inferens og modeller | Inferensgjennomstrømning | Kostnadseffektivitet |
|---|---|---|
| Sammen AI | 917 TPS, høyere latens (0.78 sekunder) | Lignende priser per token, mindre GPU-variasjon |
| Groq | 456 TPS via tilpassede LPU-er, 0.19 sekunders latens | Lavere inngangspris, begrenset modellutvalg |
| Gjenskape | Moderat hastighet, containerbasert | Enkel fakturering per prediksjon, mindre finjustering |
| Baseten | Tilpassbar infrastruktur, moderat hastighet | Fleksibel, men krever mer konfigurasjon |

