불꽃 AI 핵심 통찰력
Fireworks AI란 무엇인가요?
불꽃놀이 AI 이 플랫폼은 오픈소스 코드를 실행, 미세 조정 및 확장해야 하는 개발자와 기업을 위해 특별히 설계된 고성능 추론 플랫폼입니다. AI 프로덕션 수준의 속도로 모델을 생성합니다. Meta의 PyTorch 팀 출신들이 설립한 이 플랫폼은 오픈 소스 소프트웨어를 제공합니다.AI 100개 이상의 인기 있는 대규모 언어 모델, 비전 모델 및 이미지 생성 모델에 접근할 수 있도록 해주는 호환 가능한 API입니다.
불꽃 AI Fireworks는 서버리스 및 온디맨드 배포 옵션을 모두 제공하여 GPU 인프라 관리의 운영 부담을 없애줍니다. 기업들은 Fireworks를 사용합니다. AI 챗봇에 동력을 공급하기 위해, 코딩 어시스턴트검색 엔진 및 에이전트 AI 워크플로우를 지원합니다. 자체 개발한 추론 엔진은 표준 오픈 소스 서버 스택보다 최대 4배 높은 처리량과 50% 낮은 지연 시간을 제공하여 가장 빠른 서버 중 하나입니다. AI 현재 생성형 애플리케이션을 위한 API 제공업체가 있습니다. AI 운영 워크로드.
Fireworks AI의 독자적인 추론 엔진은 속도를 최우선으로 고려하여 설계되었습니다. 다양한 모델 크기에 걸쳐 100밀리초 미만의 빠른 토큰 처리 시간을 일관되게 제공합니다. 고객 대면 챗봇과 같이 실시간 응답성이 요구되는 모든 애플리케이션에 적합합니다. 에이전트형 코딩 도우미이러한 성능상의 이점은 측정 가능하고 상당합니다. Sourcegraph와 Notion 같은 기업들은 플랫폼으로 이전한 후 처리량 증가를 공개적으로 언급했습니다.
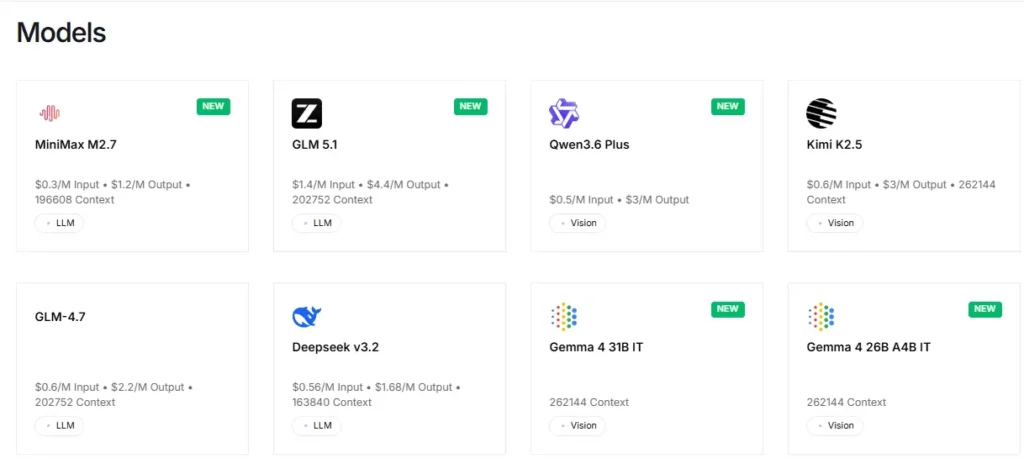
이 플랫폼은 Llama, Qwen, DeepSeek, Kimi K2.5, GLM 5, Mixtral, FLUX를 포함한 100개 이상의 오픈 소스 모델에 즉시 접근할 수 있도록 제공합니다. 이미지 생성기개발자는 구성 변경 없이 단일 API 엔드포인트를 통해 모델을 테스트하고 전환할 수 있습니다. 이를 통해 모델 제품군 전반에 걸쳐 신속한 프로토타이핑 및 A/B 테스트를 매우 효율적으로 수행할 수 있습니다.
불꽃 AI LoRA, 전체 매개변수 지도 미세 조정, DPO(선호도 정렬), 강화 미세 조정 등 모든 미세 조정 방법을 지원합니다. 특히, 미세 조정된 모델은 기본 모델과 동일한 가격으로 제공되므로 많은 경쟁업체에서 부과하는 추가 비용 부담이 없습니다. 비전 언어 모델 미세 조정도 지원하여 팀에서 자체 이미지 및 텍스트 데이터셋을 사용하여 멀티모달 모델을 맞춤 설정할 수 있습니다.
전용 리소스가 필요한 워크로드의 경우 Fireworks를 사용하세요. AI 주문형 상품 제공 GPU 배포 초 단위로 요금이 부과됩니다. 현재 하드웨어 라인업에는 NVIDIA A100, H100, H200, B200 및 B300 GPU가 포함되어 있습니다. 이를 통해 엔지니어링 팀은 보장된 용량으로 주변 인스턴스 간섭 없이 독립적으로 모델 인스턴스를 실행할 수 있는 유연성을 확보할 수 있습니다.
최근 추가된 Fire Pass는 주당 7달러의 구독 서비스로, Kimi K2.5 Turbo 모델에 무제한 토큰 액세스를 제공하며 초당 약 200~250개의 토큰을 처리할 수 있습니다. Claude Code 및 OpenCode와 같은 에이전트 기반 코딩 도구를 사용하는 개발자를 위해 특별히 설계되었으며, 토큰 단위로 청구되는 예측 불가능한 요금제 대신 정액제를 제공합니다.
불꽃 AI 가격 책정 계획
| 계획 이름 | 비용 | 오시는 길 |
|---|---|---|
| 서버리스(소형 모델) | 0.10M 토큰당 $1 | 4B 매개변수를 사용하는 모델 |
| 서버리스(미드 티어) | 0.20M 토큰당 $1 | 모델 4B~16B 매개변수 |
| 서버리스(대규모 모델) | 0.90M 토큰당 $1 | 16억 개 이상의 매개변수를 가진 모델 |
| 서버리스(MoE 모델) | 토큰 1만 개당 0.50달러~1.20달러 | 전문가 모델의 혼합 클래스 |
| 파이어 패스 | 주당 $ 7 | 무제한 키미 K2.5 터보 토큰 |
| 온디맨드(H100) | GPU 사용 시간당 6.00달러 | 초당 요금 부과, 전용 인스턴스 |
| 온디맨드(B200) | GPU 사용 시간당 9.00달러 | 최신 세대 GPU, 초당 요금 부과 |
| Enterprise | 관습 | 연간 할인, 서비스 수준 계약(SLA) 및 비공개 구축 |
Fireworks AI 시작하기
- 1 단계 : 에서 계정 만들기 불꽃놀이.ai가입하시면 자동으로 1달러 상당의 무료 크레딧이 지급됩니다.
- 2 단계 : 대시보드의 API 키 섹션으로 이동하여 새 API 키를 생성하세요.
- 3 단계 : Fireworks Python 클라이언트를 설치하거나 오픈 소스 소프트웨어를 사용하세요.AI 호환되는 SDK를 사용하세요. 기본 URL을 Fireworks API 엔드포인트로 지정하세요.
- 4 단계 : 모델 라이브러리에서 모델을 선택하고 첫 번째 API 호출을 수행한 다음 콘솔에서 사용량 및 청구를 모니터링하세요.
장단점
- 업계 최고 수준의 추론 속도.
- 100개 이상의 오픈 소스 모델을 이용할 수 있습니다.
- 완벽한 미세 조정 파이프라인이 포함되어 있습니다.
- 파이어 패스는 무제한 토큰을 제공합니다.
- 최신 세대 GPU 하드웨어(B300).
- 개발자 전용, 코딩이 필요 없는 무료 대시보드입니다.
- 내장된 업무 워크플로우 도구가 없습니다.
- 고객 지원이 느려질 수 있습니다.

