Chroma Key-ის მიმოხილვა
რა არის ქრომა?
ხრომა არის ხელოვნური ინტელექტით შექმნილი, ღია კოდის ვექტორული მონაცემთა ბაზა, რომელიც სპეციალურად შექმნილია თანამედროვე ტექნოლოგიებში გამოყენებული მაღალი განზომილებიანი ჩანერგვების შესანახად, ინდექსირებისა და მოთხოვნისთვის. AI აპლიკაციები. ის უზრუნველყოფს RAG (Retrieval-Augmented Generation) სისტემებში აღდგენის ფენის, სემანტიკური საძიებო სისტემების, LLM მეხსიერების საცავების და ხელოვნური ინტელექტით მართულ რეკომენდაციის ინსტრუმენტებში მუშაობას.
დეველოპერებს შეუძლიათ მისი მეხსიერებაში გაშვება მყისიერი ლოკალური პროტოტიპების შესაქმნელად ან Chroma Cloud-თან დაკავშირება სრულად მართული, სერვერის გარეშე განლაგებისთვის AWS-ში, GCP-სა და Azure-ში. ტრადიციული SQL მონაცემთა ბაზებისგან განსხვავებით, Chroma სპეციალურად შექმნილია არასტრუქტურირებული მონაცემებისა და ვექტორული მსგავსების შესატყვისობისთვის, რაც მას სასურველ ჩასაშენებელ მონაცემთა ბაზად აქცევს. AI ინჟინრები ქმნიან წარმოების LLM აპლიკაციებს. მისი Python-ზე დაფუძნებული API ნიშნავს, რომ გუნდები იწყებენ მუშაობას კოდის სამ ხაზზე ნაკლებ დროში, სქემის მართვის ზედმეტი ხარჯების გარეშე.
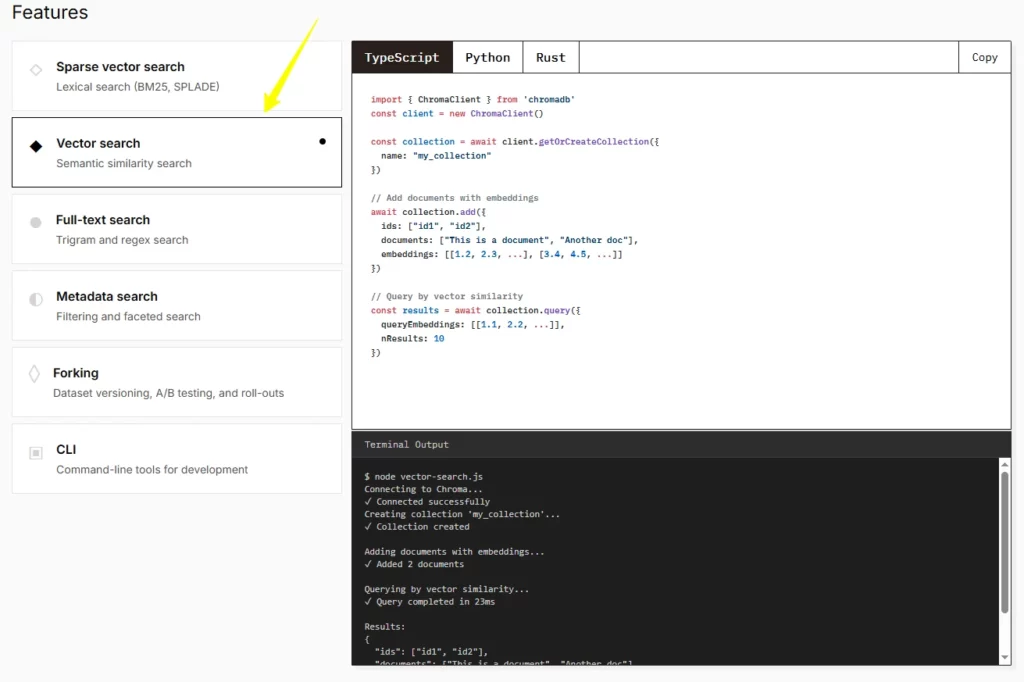
Chroma აერთიანებს ვექტორული მსგავსების ძიებას, სრულტექსტოვან ძიებას და მეტამონაცემების ფილტრაციას ერთ მოთხოვნის ინტერფეისში. ეს ნიშნავს, რომ თქვენს RAG აპლიკაციას შეუძლია შედეგების მოძიება სემანტიკური სიახლოვის საფუძველზე. საკვანძო სიტყვების შესაბამისობადა ერთდროულად მორგებული ატრიბუტების ფილტრები. კონკურენტი ინსტრუმენტები, როგორც წესი, გაიძულებთ, ცალკეული ძიების ფენები ჩართოთ, რაც ინჟინერიულ ხარჯებს და შეყოვნებას ზრდის.
Chroma Sync Chroma Cloud-ისთვის სერვერის გარეშე მონაცემთა მიღებას ახორციელებს. ის შექმნილია გუნდებისთვის, რომლებსაც სურთ მონაცემების მოპოვება ნაკლები ოპერაციული სამუშაოთი და ნაკლები ხელით შესრულებული ნაბიჯებით. ეს სასარგებლოა AI აპლიკაციები, რომლებსაც სჭირდებათ ახალი კონტენტის სწრაფი ინდექსირება საკუთარი გადამუშავების სამუშაოების შესრულების გარეშე.
Chroma მონაცემთა ბაზა არის ღია კოდის ძიება პროდუქტის უკან არსებული ინფრასტრუქტურის ფენა. ის გუნდებს კონტროლს, მოქნილობას და Apache 2.0 ლიცენზირებას აძლევს, რაც მნიშვნელოვანია დეველოპერებისთვის, რომლებსაც სურთ ღია კოდის ძიების ინფრასტრუქტურა მომწოდებლის შეზღუდვის გარეშე.
აგენტის ძიება არის Chroma-ს პარეტოს სასაზღვრო სტილის ძიების ფენა AI აგენტები. ის მიზნად ისახავს მოძიების სამუშაო პროცესები სადაც სისტემამ სწრაფად უნდა მოახდინოს რანჟირება და ყველაზე რელევანტური კონტექსტის მოძიება. ეს კარგად შეეფერება აგენტურ აპლიკაციებს, RAG სტეკებს და კონტექსტის ინჟინერიას.
Chroma Cloud საშუალებას გაძლევთ შექმნათ ცალკეული მონაცემთა ბაზები განვითარების, ეტაპობრივი და საწარმოო გარემოსთვის და ინდივიდუალური API გასაღებები კონკრეტულ მონაცემთა ბაზებზე გადაიტანოთ. გუნდებისთვის, რომლებიც მართავენ მრავალს AI პროდუქტებისა თუ კლიენტებისთვის, იზოლაციის ეს დონე ხელს უშლის მონაცემთა ძვირადღირებულ დაბინძურებას გარემოსდაცვითი სისტემებიდან და ამარტივებს წვდომის მართვას საწარმოს IAM დაყენების გარეშე.
შიდა ვერსიის მიხედვით, Chroma იყენებს Apache Arrow სვეტოვან მონაცემთა ფორმატს მოთხოვნის შესრულების დროს მონაცემებზე სწრაფი და დაბალი დანახარჯებით წვდომისთვის. ეს არ არის მარკეტინგული ხრიკი. Arrow იგივე ფორმატია, რომელსაც იყენებს მაღალი ხარისხის ანალიტიკა ისეთი ძრავები, როგორიცაა DuckDB და Apache Spark, რაც ნიშნავს Chroma-ს's მოძიების სიჩქარე დაფუძნებულია ბრძოლაში გამოცდილი ინფრასტრუქტურის დიზაინზე.
Chroma-ს ფასების გეგმები
| გეგმა | ღირებულება | ძირითადი შეზღუდვები და ფუნქციები |
|---|---|---|
| შემქმნელის | 0 აშშ დოლარი თვეში + გამოყენება | 5 დოლარიანი უფასო კრედიტი, 10 მონაცემთა ბაზა, 10 გუნდის წევრი, Community Slack |
| გუნდი | 250 აშშ დოლარი თვეში + გამოყენება | 100 დოლარის ღირებულების კრედიტები, 100 მონაცემთა ბაზა, 30 გუნდის წევრი, Slack-ის მხარდაჭერა, SOC II, მოცულობის ფასდაკლებები |
| Enterprise | საბაჟო ფასი | შეუზღუდავი მონაცემთა ბაზები და გუნდის წევრები, ერთი მოიჯარე კლასტერები, BYOC, სპეციალური მხარდაჭერა, SLA-ები |
Chroma Cloud vs თვითორგანიზებული Chroma
თვითჰოსტინგი Chroma გთავაზობთ მაქსიმალურ კონტროლს და ნულოვან პირდაპირ ხარჯებს, რაც მას შიდა ინსტრუმენტების, კონცეფციების დამტკიცებისა და მცირე მასშტაბის წარმოების აპლიკაციების გამოყენების სწორ გზად აქცევს. Chroma Cloud მთლიანად ხსნის ინფრასტრუქტურის მართვის ტვირთს.
თქვენ მიიღებთ სერვერის გარეშე, ავტომატურად მასშტაბირებად განლაგებას AWS-ზე, GCP-ზე ან Azure-ზე SOC II თავსებადობით Team გეგმაში, რაც მნიშვნელოვანია იმ მომენტიდან, როდესაც დაიწყებთ მომხმარებლის მონაცემების დამუშავებას SaaS პროდუქტში. პროტოტიპის ეტაპის მიღმა გუნდების უმეტესობისთვის, Chroma Cloud's გამოყენებაზე დაფუძნებული მოდელი გაცილებით უფრო ეკონომიურია, ვიდრე Pinecone's მინიმუმ 50 დოლარი/თვეში.
დადებითი და უარყოფითი მხარეები
- ნამდვილად უფასო ღია კოდის ბირთვი.
- სამხაზიანი დაყენება ნულიდან.
- ჰიბრიდული ძიება ყუთიდან ამოღებისთანავე.
- კოდი არ იცვლება დეველოპერიდან პროდუკამდე.
- მრავალჯერადი ჩასმის პროვაიდერის მხარდაჭერა.
- მილიარდობით მასშტაბის წარმოებისთვის არ არის შესაფერისი.
- GPU აჩქარების მხარდაჭერა არ არის.
- შეზღუდული მოწინავე უსაფრთხოება საწარმოს მონაცემთა ბაზებთან შედარებით.


