一緒に AI 主な洞察
Together AIとは何ですか?
一緒にAI フルスタックです AI オープンソースの大規模言語モデルに迅速かつ費用対効果の高いアクセスを必要とする開発者や機械学習エンジニア向けに構築されたクラウドプラットフォームです。2020年に設立されたこのプラットフォームは、サーバーレス推論、モデルのファインチューニング、専用GPUエンドポイント、オンデマンドGPUクラスタをすべて1つのプラットフォームで提供します。Llama 4、DeepSeek V3、Qwen 3.5、Mistral、画像生成用のFLUXなど、200種類以上のモデルをサポートしています。
一緒に AI GPUインフラストラクチャの管理という負担が軽減されるため、チームは構築に集中できます。 AI ネイティブアプリケーション。オープンです。AI 互換性のあるAPIとは、既存のコードベースを最小限の変更で移行できることを意味します。大量のデータを処理したい企業にとって AI 独自のAPIコストのほんの一部でワークロードを処理、 AI 実運用レベルの推論およびトレーニングプロバイダーとして、強力な地位を確立している。
一緒に AI 200人以上のホスト オープンソースモデル テキスト、画像、動画、音声、埋め込み、コード生成など、あらゆる要素に対応。開発者はサーバーをプロビジョニングすることなく、単一のAPIを通じてあらゆるモデルを呼び出すことができます。Llama 4 Maverickのようなモデルは、100万入力トークンあたり約0.27ドルで動作するため、大量の本番ワークロードを独自の代替ソリューションよりも大幅に安価に処理できます。また、このプラットフォームには、緊急性の低いジョブを低コストで処理できるバッチAPIも含まれています。
Together AI独自の推論エンジンは、FlashAttention 3とATLASスペキュレーターシステムを採用することで、標準的な実装よりも最大3.5倍高速な推論を実現します。NVIDIA H100ハードウェアでは、BF16精度で約840 TFLOPS/秒の性能を達成します。実際の運用環境では、毎秒約400トークンの処理速度となり、GPT 4 Turboの出力速度の約2.5~4倍の速さとなります。
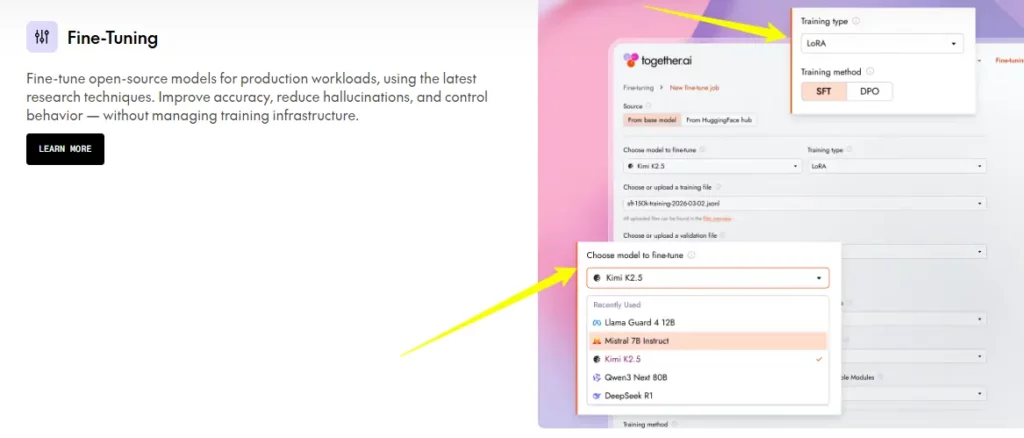
このプラットフォームは、最大 1000 億パラメータのモデルに対して、LoRA (低ランク適応) とフルウェイトファインチューニングの両方をサポートしています。価格は、最大 160 億パラメータのモデルに対する LoRA の場合、100 万トークンあたり 0.48 ドルからとなっています。チームは、独自のデータでモデルをトレーニングして、法律、医療、または 顧客サポートアプリケーション そして、それらをTogether AIの推論スタックに即座にデプロイします。
専用のコンピューティングが必要なチームのために、 AI NVIDIA H100、H200、B200、そして最新のGB200およびGB300 NVL72ラックへの即時アクセスを提供します。オンデマンド料金はH100ノードで1時間あたり3.49ドルから、長期契約の場合は予約料金が1時間あたり2.55ドルまで下がります。そのため、機械学習トレーニングワークロードにおいて、AWS、GCP、Azureの有力な代替手段となります。
OpenAIのAPIからTogetherへの移行 AI 必要なのはベース URL の変更だけです。プラットフォームには、コードを実行するコードインタープリタも用意されています。 LLMが生成したコード サンドボックス環境ではセッションあたり0.03ドル、より大規模な開発環境向けのフルコードサンドボックスはvCPU時間単位で課金されます。
一緒に AI 料金プラン
| 計画 | 費用 | 特徴 |
|---|---|---|
| サーバーレス推論 | 1万トークンあたり0.02ドル~7.00ドル | モデルによって異なります。出力トークンのコストは入力トークンのコストよりも高くなります。 |
| 専用エンドポイント | 時給3.99ドルから | シングルテナントGPU、パフォーマンス保証付き |
| GPUクラスター(オンデマンド) | $ 3.49 /時 | 時間制課金、契約期間の縛りなし |
| GPUクラスター(予約済み) | 時給2.55ドル~7.15ドル | 1週間から6ヶ月以上の契約期間、ボリュームディスカウントあり |
| 微調整(LoRA) | 1万トークンあたり0.48ドル~2.90ドル | モデルサイズに基づく(最大100B) |
| 微調整(フル) | 1万トークンあたり0.54ドル~3.20ドル | すべての重量が更新されました |
| コードインタープリタ | セッションあたり$ 0.03 | サンドボックス化されたコード実行 |
| 共有ファイルシステム | 1ギガバイトあたり月額0.16ドル | 高帯域幅並列ストレージ |
一緒に AI 研究およびオープンソースへの貢献
一緒に AI は単なるインフラプロバイダーではありません。同社は積極的に AI 研究の推進。同チームは、現在業界全体で標準となっているアテンションメカニズムであるFlashAttentionを開発しました。その他の貢献としては、Mixture of Agents、Red Pajamaオープンデータセット、DeepCoder、Open Data Scientist Agentなどがあります。
この研究優先のアプローチは最新の 最適化手法 モデルアーキテクチャはプラットフォーム上で初日から利用可能です。モデル性能の最先端を維持することを重視するエンジニアリングチームにとって、この継続的な研究パイプラインは、 AI 純粋なクラウドコンピューティングの再販業者には到底真似できない、技術的な優位性。
長所と短所
- 200種類以上のオープンソースモデルが利用可能です。
- 業界トップクラスの推論速度。
- 店は開いていますAI 互換性のあるAPI移行。
- 柔軟なGPUクラスタオプション。
- 高度な微調整機能をサポート。
- 有効 AI 研究への貢献
- 永久無料枠はありません。
- 開発者向けであり、初心者には不向きです。
- コスト予測は難しい場合がある。
ベスト・トゥギャザー AI 他の選択:
| AI インフラストラクチャ/MLOpsプラットフォーム | コスト効率 | モデルの幅広さ |
|---|---|---|
| 複製する | 秒単位の課金方式で、負荷の高い作業に適しています。 | 100種類以上のモデル、特に普及モデルとカスタムモデルに強みを持つ |
| オープンルーター | トークンあたりのコストが最も低いプロバイダーを集約します | 複数のバックエンドにわたる200以上のモデル |
| 花火AI | 競争力のあるサーバーレス価格、高速な推論 | 主要なオープンソースLLMに焦点を当てる |
| ハグ顔推論エンドポイント | 無料プランあり、柔軟な導入が可能 | 最大のオープンソースモデルハブ |

