Fireworks AI Dettagli Principali
What is Fireworks AI?
IA dei fuochi d'artificio is a high performance inference platform purpose built for developers and enterprises who need to run, fine tune, and scale open source AI models at production grade speed. Founded by former members of the PyTorch team at Meta, the platform provides an OpenAI compatible API that grants access to over 100 popular large language models, vision models, and image generation models.
Fireworks AI eliminates the operational burden of managing GPU infrastructure by offering both serverless and on demand deployment options. Businesses use Fireworks AI to power chatbots, assistenti di codifica, search engines, and agentic AI workflows. Its custom built inference engine delivers up to 4x higher throughput and 50% lower latency than standard open source serving stacks, making it one of the fastest AI API providers available today for generative AI production workloads.
Fireworks AI’s proprietary inference engine is built from the ground up for speed. It consistently delivers first token latency under 100 milliseconds across a wide range of model sizes. For any application that demands real time responsiveness, such as customer facing chatbots or assistenti di codifica agentici, this performance advantage is measurable and significant. Companies like Sourcegraph and Notion have publicly noted throughput gains after migrating to the platform.
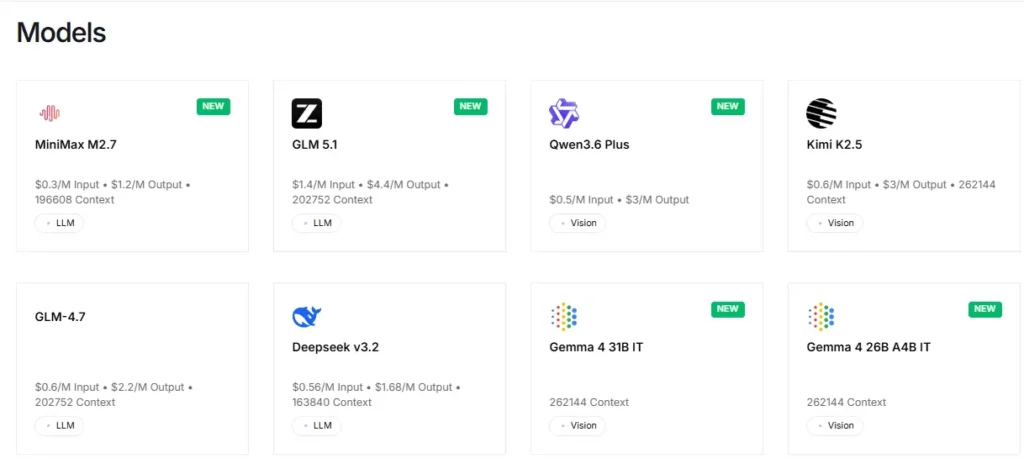
The platform provides instant access to more than 100 open source models, including Llama, Qwen, DeepSeek, Kimi K2.5, GLM 5, Mixtral, and FLUX generatori di immagini. Developers can test and swap between models through a single API endpoint with no configuration changes. This makes rapid prototyping and A/B testing across model families extremely efficient.
Fireworks AI supports the full range of fine tuning methods including LoRA, full parameter supervised fine tuning, DPO (preference alignment), and reinforcement fine tuning. Critically, fine tuned models are served at the same price as base models, removing the cost penalty that many competitors impose. Vision language model fine tuning is also supported, allowing teams to customise multimodal models with their own image and text datasets.
For workloads that need dedicated resources, Fireworks AI offerte su richiesta GPU deployments billed per second. The hardware lineup now includes NVIDIA A100, H100, H200, B200, and B300 GPUs. This gives engineering teams the flexibility to run private, isolated model instances with guaranteed capacity and no noisy neighbour issues.
A recent addition, Fire Pass is a $7 per week subscription that provides unlimited token access to the Kimi K2.5 Turbo model at speeds around 200 to 250 tokens per second. It is designed specifically for developers using agentic coding tools like Claude Code and OpenCode, offering a flat rate alternative to unpredictable per token billing.
Fireworks AI Piani di prezzi
| Piano Nome | Costo | Dettagli chiave |
|---|---|---|
| Serverless (Small Models) | $ 0.10 per 1 milione di token | Models under 4B parameters |
| Serverless (Mid Tier) | $ 0.20 per 1 milione di token | Models 4B to 16B parameters |
| Serverless (Large Models) | $ 0.90 per 1 milione di token | Models over 16B parameters |
| Serverless (MoE Models) | Da 0.50 a 1.20 dollari per 1 milione di token | Mixtral class mixture of experts models |
| Fire Pass | 7 $ a settimana | Unlimited Kimi K2.5 Turbo tokens |
| On Demand (H100) | $6.00 per GPU hour | Billed per second, dedicated instance |
| On Demand (B200) | $9.00 per GPU hour | Latest gen GPU, billed per second |
| Impresa | Custom | Annual discounts, SLAs, and private deployments |
Getting Started with Fireworks AI
- Passo 1: Crea un account fireworks.ai. You will receive $1 in free credits automatically upon sign up.
- Passo 2: Navigate to the API Keys section in your dashboard and generate a new API key.
- Passo 3: Install the Fireworks Python client or use any OpenAI compatible SDK. Point your base URL to the Fireworks API endpoint.
- Passo 4: Choose a model from the model library, make your first API call, and monitor usage and billing from the console.
Pro e contro
- Velocità di inferenza leader del settore.
- Sono disponibili oltre 100 modelli open source.
- Full fine tuning pipeline included.
- Fire Pass offers unlimited tokens.
- Latest gen GPU hardware (B300).
- Developer only, no code free dashboard.
- No built in business workflow tools.
- L'assistenza clienti può essere lenta.
Best Fireworks AI Alternative
| AI Inference & Model Serving Platform | Inference Throughput | Razionalizzazione dei costi |
|---|---|---|
| Insieme AI | 917 TPS, higher latency (0.78s) | Similar per token rates, less GPU variety |
| Groq | 456 TPS via custom LPUs, 0.19s latency | Lower entry pricing, limited model selection |
| Replicare | Moderate speed, container based | Simple per prediction billing, less fine tuning |
| Baseten | Customisable infra, moderate speed | Flexible but requires more configuration |

