
A gyors módosítások önmagukban már nem elégek a vállalatok számára AI rendszerek. Ahogy a modell kontextus ablakai meghaladják a 200 ezer tokent, a mérnökök most dokumentumokkal, visszakeresési folyamatokkal, munkafüzetekkel és eszközhívásokkal látják el az LLM-et – ezt a megközelítést a cég kontextusmérnöki.
A váltás gyorsan történt.
A kontextusmérnökség áthidalja ezt a szakadékot azáltal, hogy a teljes AI környezet rendszerként, ahelyett, hogy az egyes bemenetekre összpontosítanánk.
Kontextusmérnökség:
A rendszer, ami tényleg működik
A kontextusmérnökség az LLM hívás előtti teljes folyamatot tervezhető infrastruktúraként kezeli. Gondoljon egy LLM-re.'s a kontextuális ablakot RAM-ként kezeli – korlátozott munkamemóriával rendelkezik, amely meghatározza, hogy mit képes feldolgozni a modell.
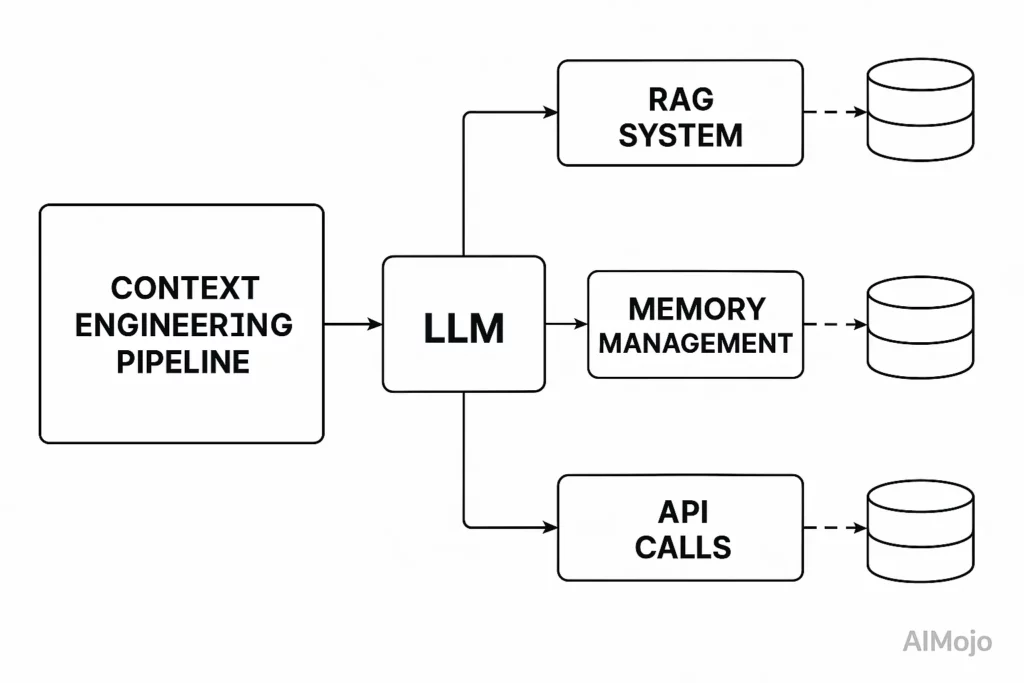
Ahogyan egy operációs rendszer gondosan kezeli, hogy mi kerül a RAM-ba, úgy a kontextusmérnökség is gondosan kezeli, hogy milyen információk töltik meg az LLM-et.'s kontextus ablak.
Itt's Mit foglal magában a kontextusmérnökség valójában:
Kontextusmérnökség vs. Promptmérnökség:
A számok nem hazudnak
| Aspect | Prompt Engineering | Kontextusmérnökség |
|---|---|---|
| Összpontosít | Egy bemeneti karakterlánc létrehozása | A modell körüli összes jel összehangolása |
| Átlagos fejlesztési idő | 70%-ban azonnali módosítások | 60% adatfolyamatok, 20% memóriaszabályok, 20% promptok |
| Tipikus hibamód | A kimeneti minőség hirtelen visszaesése adateltolódás után | Rugalmas RAG, memória és eszközhívások segítségével |
Gyors példa: Egy ügyfélszolgálati bot A kizárólag promptokkal betanított botok közvetlenül a kérdésre vissza tudják hívni a visszatérítési szabályzatot. Amikor a felhasználó a „45791-es rendelésre” hivatkozik, a folyamat sikertelen. Adjunk hozzá kontextus-mérnöki megoldást – beszélgetési előzményeket és egy RAG-lekérdezést a rendelési adatbázisba –, és a bot azonnal lekéri a vásárlás részleteit, és javasolja a megfelelő visszatérítési folyamatot.
A kontextusmérnökség négy pillére, amelyek valóban számítanak
1. Írási kontextus (a mesterséges intelligencia's Jegyzetkészítő rendszer)
A kontextus írása azt jelenti, hogy az információkat a kontextuson kívül is tároljuk. kontextus ablak későbbi felhasználásra. Ez értékes tokenterületet takarít meg, miközben fenntartja a hozzáférést a fontos adatokhoz.
Fióktömbök úgy működik, mint a jegyzetelés az ügynökök számára egyetlen munkameneten belül. Antropic's a többágensű kutató elmenti a kezdeti tervét a következőre: „Memory design„Mert ha a kontextus meghaladja a 200,000 XNUMX tokent, akkor csonkolódik, és a terv elveszik.”

Hosszú távú emlékek információk megőrzése több munkameneten keresztül. Ilyen például a ChatGPT automatikus felhasználói beállítások generálása a beszélgetésekből, valamint a kurzor/szörf tanulása kódolási minták és a projekt kontextusa.

2. Kontextusválasztás (A fontos dolgok kiválasztásának művészete)
A kontextus kiválasztása csak a feladathoz szükséges információkat tartalmazza.
Ha egy AI fitnesz edző edzéstervet generál, ki kell választania a felhasználót is tartalmazó kontextusadatokat's magasság, súly és aktivitási szint, miközben figyelmen kívül hagyja a lényegtelen információkat.
A legfontosabb betekintésA több információ nem mindig jobb. A hatékony kontextus-tervezés azt jelenti, hogy minden egyes feladathoz a megfelelő kombinációt kell kiválasztani.
3. Kontextustömörítés (Több beleillesztése kevesebbbe)
Amikor a beszélgetések annyira elnyúlnak, hogy meghaladják a LLM's emlékezet ablakban a kontextus tömörítése kritikus fontosságúvá válik. Az ügynökök ezt jellemzően a beszélgetés korábbi részeinek összefoglalásával érik el.

4. Kontextusbeli izoláció (Oszd meg és uralkodj)
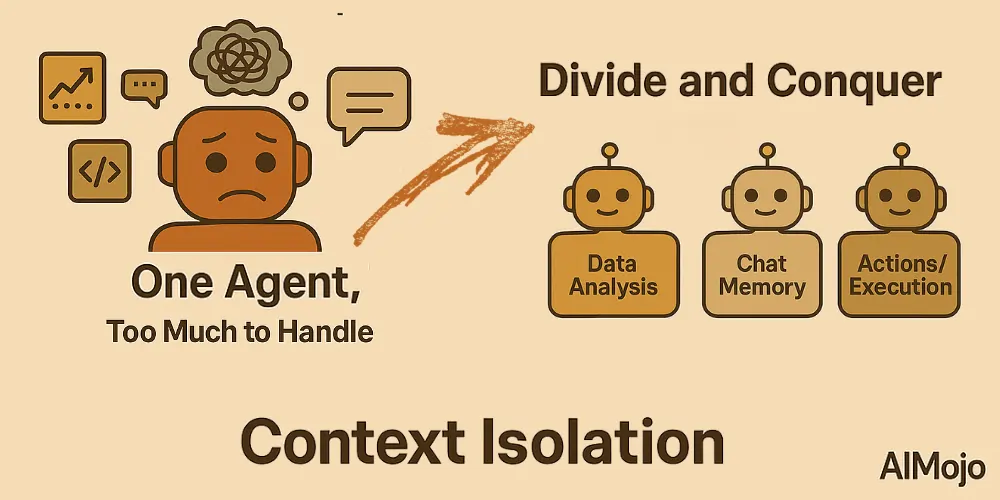
A kontextus elkülönítése az információk különálló részekre bontását jelenti, hogy az ágensek jobban tudják kezelni az összetett feladatokat. Ahelyett, hogy az összes tudást egyetlen hatalmas promptba zsúfolnák, a fejlesztők a kontextust specializált alágensek vagy... homokozós környezetek.
Valós kontextusú mérnöki munka a gyakorlatban
Az ügyfélszolgálat forradalma
| A kontextusmérnökség előtt | Kontextusmérnökség után |
|---|---|
| Általános chatbotok, amik elfelejtik a korábbi beszélgetéseket és irreleváns válaszokat adnak. | AI ügynökök, akik megjegyzik a vásárlási előzményeidet, hozzáférnek a valós idejű készletadatokhoz, és szükség esetén együttműködnek az emberi ügynökökkel. |
A kódoló asszisztens, amely soha nem felejt
A rendszerAmikor a „Hogyan javíthatom ki ezt a hitelesítési hibát?” kérdésre válaszolsz, a kontextusmérnöki rendszer automatikusan:

Általános kódolási tanácsok helyett konkrét megoldásokat kapsz, amelyek a tényleges kódbázisodra vannak szabva.
A kontextusmérnöki tevékenységet működtető műszaki architektúra
Dinamikus kontextus összeállítás
A kontextus menet közben épül fel, és a beszélgetések előrehaladtával fejlődik. Ez magában foglalja:
- Releváns dokumentumok lekérése
- A memória megőrzése
- Felhasználói állapot frissítése
- API-hívások és adatbázis-lekérdezések
Kontextuális ablakkezelés
Fix mérettel token limitek (32K, 100K, 1M) esetén a mérnököknek intelligensen kell tömöríteniük és rangsorolniuk az információkat a következők használatával:
- Pontozási függvények (TF-IDF, beágyazások, figyelemheurisztikák)
- Összefoglalás és jelentőségkivonás
- Darabolási stratégiák és átfedéses hangolás

Biztonság és következetesség
Alkalmazzon olyan elveket, mint az injekció azonnali felismerése, kontextusfertőtlenítés, Személyazonosításra alkalmas adatok szerkesztéseés szerepköralapú kontextusalapú hozzáférés-vezérlés.
Első kontextusú mérnöki rendszer felépítése
A kontextusmérnöki munkafolyamat felépítése nem csak elmélet – az's egy megismételhető folyamat, amely operacionalizálható és akár automatizálható is. Így ültetheti át a gyakorlatba:
Lépés 1: Térképezd fel a kontextusforrásaidat
Határozza meg, hogy az ügynökének honnan kell információkat gyűjtenie (dokumentumok, adatbázisok, API-k, korábbi csevegések stb.).
piton
# Example: Fetching relevant documents using embeddings
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer("all-MiniLM-L6-v2")
query = "project status update"
corpus = ["spec doc", "requirements", "last week's meeting notes"]
query_embedding = model.encode(query, convert_to_tensor=True)
corpus_embeddings = model.encode(corpus, convert_to_tensor=True)
hits = util.semantic_search(query_embedding, corpus_embeddings, top_k=2)[0]
relevant_docs = [corpus[hit['corpus_id']] for hit in hits]
Lépés 2: Memória és írási kontextus megvalósítása
Tárolja a fontos információkat, hogy azok mindig kéznél legyenek a jövőbeni feladatokhoz.
piton
import json
def save_to_memory(memory_path, user_id, data):
with open(memory_path, "r+") as file:
memory = json.load(file)
memory[user_id] = data
file.seek(0)
json.dump(memory, file)
file.truncate()Lépés 3: Kontextuskiválasztás és tömörítési logika felépítése
Szabályokat vagy modelleket dolgozzon ki, amelyek csak a feladat szempontjából legrelevánsabbakat választják ki. Hosszú előzményeket tömörítsen összefoglaló formákba.
piton
def summarize_conversation(history):
# Placeholder for use with an LLM summarizer or custom rules
return history[-5:] # Only the last 5 messagesLépés 4: Kontextusok elkülönítése az ágenskoordinációhoz
Ossza szét az információkat, hogy minden ügynök vagy komponens csak azt kezelje, amit kell.
piton
user_profile_ctx = {"user_goals": "..."}
task_specific_ctx = {"current_task": "..."}
external_data_ctx = {"live_data": "..."}
full_context = {**user_profile_ctx, **task_specific_ctx, **external_data_ctx}Lépés 5: Kimeneti strukturálás és API-készség
A kimeneti kontextust egységesen formázd, hogy az's kiszámítható a downstream LLM hívásokhoz vagy API végpontokhoz.
piton
schema = {
"user": {"age": 35, "goal": "muscle gain"},
"plan": "high protein, 3x/week weight training"
}Lépés 6: Monitorozás, iteráció és biztonság
Kövesse nyomon a hibákat, auditálja a kontextus minőségét, és fejlessze a kontextusbeillesztés, a memória és a visszakeresés logikáját. Mindig fertőtlenítse a bemeneteket a gyors injektálás és az adatszivárgás elkerülése érdekében.
Miért fizet jobban a kontextusalapú mérnöki munka, mint a gyorsmérnöki munka
A vállalatoknak olyan mérnökökre van szükségük, akik olyan rendszereket tudnak építeni, amelyek a megfelelő kontextust biztosítják a mesterséges intelligenciának, pontosak és naprakészek maradnak, és biztonsági irányelvek hozzáadásával védik a felhasználókat.
A piaci valóságA kontextusmérnökség olyan funkciókon átívelő készségeket igényel, mint az üzleti felhasználási esetek megértése, a kimenetek meghatározása és az információk strukturálása, hogy az LLM-ek összetett feladatokat tudjanak elvégezni.
Alsó sor: Bárki írhat promptokat. Kontextus-érzékeny ágenseket kell létrehozni, amelyek nagy léptékben megjegyzik, alkalmazkodnak és kiválasztják a kontextust? Így tehetik a fejlesztők jövőbiztossá képességeiket, és így tudnak valódi értéket teremteni fejlett LLM alkalmazásokkal.



 BÓNUSZ: Szerezd meg a 200 dolláros "AI „Mastery Toolkit” INGYENES regisztrációval!
BÓNUSZ: Szerezd meg a 200 dolláros "AI „Mastery Toolkit” INGYENES regisztrációval!






