Feu d'artifice AI Insights
Qu'est-ce que Fireworks AI ?
IA de feux d'artifice est une plateforme d'inférence haute performance conçue spécifiquement pour les développeurs et les entreprises qui ont besoin d'exécuter, d'optimiser et de faire évoluer des applications open source. AI Des modèles à une vitesse de production industrielle. Fondée par d'anciens membres de l'équipe PyTorch de Meta, la plateforme offre un environnement ouvert.AI API compatible donnant accès à plus de 100 modèles de langage, modèles de vision et modèles de génération d'images populaires.
Feu d'artifice AI Fireworks élimine la charge opérationnelle liée à la gestion de l'infrastructure GPU en proposant des options de déploiement sans serveur et à la demande. Les entreprises utilisent Fireworks. AI pour alimenter les chatbots, assistants de codage, moteurs de recherche et agents AI Ses flux de travail. Son moteur d'inférence personnalisé offre un débit jusqu'à 4 fois supérieur et une latence 50 % inférieure aux piles de serveurs open source standard, ce qui en fait l'un des plus rapides. AI Fournisseurs d'API disponibles aujourd'hui pour la génération AI charges de travail de production.
Le moteur d'inférence propriétaire de Fireworks AI est conçu dès le départ pour la rapidité. Il garantit une latence du premier jeton inférieure à 100 millisecondes pour une large gamme de modèles. Il est idéal pour toute application exigeant une réactivité en temps réel, comme les chatbots destinés aux clients. assistants de codage agentiquesCet avantage en termes de performances est mesurable et significatif. Des entreprises comme Sourcegraph et Notion ont publiquement constaté des gains de débit après leur migration vers cette plateforme.
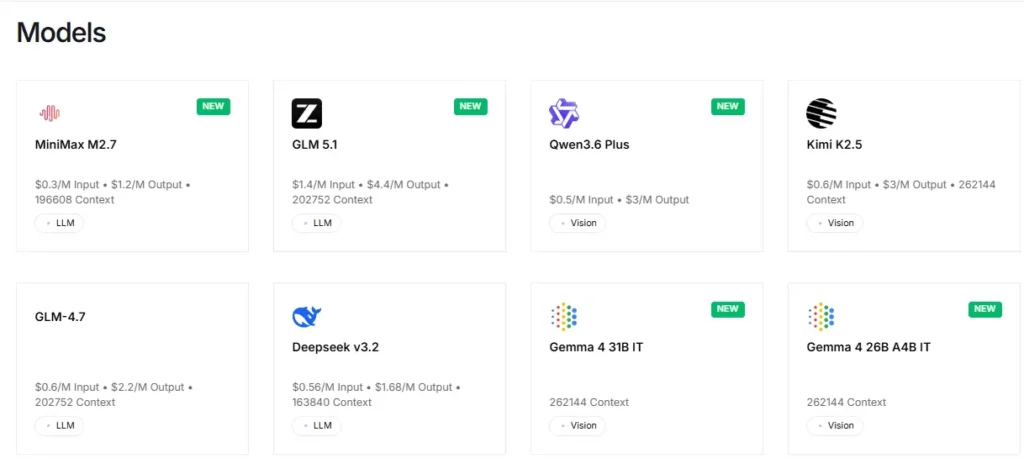
La plateforme offre un accès instantané à plus de 100 modèles open source, dont Llama, Qwen, DeepSeek, Kimi K2.5, GLM 5, Mixtral et FLUX. générateurs d'imagesLes développeurs peuvent tester et passer d'un modèle à l'autre via un point de terminaison API unique, sans aucune modification de configuration. Cela rend le prototypage rapide et les tests A/B sur différentes familles de modèles extrêmement efficaces.
Feu d'artifice AI Il prend en charge l'ensemble des méthodes d'ajustement fin, notamment LoRA, l'ajustement fin supervisé complet des paramètres, DPO (alignement des préférences) et l'ajustement fin par renforcement. Point essentiel, les modèles ajustés sont proposés au même prix que les modèles de base, éliminant ainsi le surcoût imposé par de nombreux concurrents. L'ajustement fin des modèles de vision et de langage est également pris en charge, permettant aux équipes de personnaliser les modèles multimodaux avec leurs propres jeux de données d'images et de textes.
Pour les charges de travail nécessitant des ressources dédiées, Fireworks AI offres à la demande Déploiements de GPU Facturation à la seconde. La gamme matérielle comprend désormais les GPU NVIDIA A100, H100, H200, B200 et B300. Les équipes d'ingénierie bénéficient ainsi de la flexibilité nécessaire pour exécuter des instances privées et isolées, avec une capacité garantie et sans risque de surcharge.
Fire Pass, un abonnement récent à 7 $ par semaine, offre un accès illimité aux jetons du modèle Kimi K2.5 Turbo à une vitesse d'environ 200 à 250 jetons par seconde. Conçu spécifiquement pour les développeurs utilisant des outils de programmation automatisée comme Claude Code et OpenCode, il propose une alternative à tarif fixe à la facturation au jeton, souvent imprévisible.
Feu d'artifice AI Plans de tarification
| Nom du régime | Prix | Eléments Clés |
|---|---|---|
| Sans serveur (petits modèles) | 0.10 $ pour 1 M de jetons | Modèles sous les paramètres 4B |
| Sans serveur (niveau intermédiaire) | 0.20 $ pour 1 M de jetons | Paramètres des modèles 4B à 16B |
| Sans serveur (modèles volumineux) | 0.90 $ pour 1 M de jetons | Modèles de plus de 16 milliards de paramètres |
| Sans serveur (Modèles MoE) | De 0.50 $ à 1.20 $ par million de jetons | Classe mixte de modèles d'experts |
| Passage de feu | 7 $ par semaine | Jetons Kimi K2.5 Turbo illimités |
| À la demande (H100) | 6.00 $ par heure de GPU | Facturé à la seconde, instance dédiée |
| À la demande (B200) | 9.00 $ par heure de GPU | GPU de dernière génération, facturé à la seconde |
| Entreprise | Encadrement Sur Mesure | Remises annuelles, SLA et déploiements privés |
Premiers pas avec Fireworks AI
- Étape 1 : Créez un compte sur feux d'artifice.aiVous recevrez automatiquement 1 $ de crédits gratuits lors de votre inscription.
- Étape 2 : Accédez à la section Clés API de votre tableau de bord et générez une nouvelle clé API.
- Étape 3 : Installez le client Python Fireworks ou utilisez n'importe quel client OpenCase.AI Kit de développement logiciel (SDK) compatible. Indiquez le point de terminaison de l'API Fireworks dans votre URL de base.
- Étape 4 : Choisissez un modèle dans la bibliothèque de modèles, effectuez votre premier appel API et suivez l'utilisation et la facturation depuis la console.
Avantages et inconvénients
- Vitesse d'inférence inégalée dans le secteur.
- Plus de 100 modèles open source disponibles.
- Pipeline de réglage fin complet inclus.
- Fire Pass offre des jetons illimités.
- Matériel GPU de dernière génération (B300).
- Tableau de bord gratuit, sans code, réservé aux développeurs.
- Aucun outil intégré de gestion des flux de travail.
- Le support client peut être lent.
Les meilleurs feux d'artifice AI Alternatives
| AI Plateforme d'inférence et de diffusion de modèles | Débit d'inférence | Efficacité des coûts |
|---|---|---|
| Ensemble IA | 917 TPS, latence plus élevée (0.78 s) | Tarifs par jeton similaires, mais moins de choix de GPU |
| Groq | 456 TPS via des LPU personnalisées, latence de 0.19 s | Prix d'entrée plus bas, choix de modèles limité |
| Reproduire | Vitesse modérée, basé sur les conteneurs | Facturation simple par prédiction, moins de réglages fins |
| baseten | Infrastructure personnalisable, vitesse modérée | Flexible mais nécessite une configuration plus poussée |

