خزیدن4AI بینش کلیدی
Crawl4AI چیست؟
خزش برای هوش مصنوعی یک کتابخانه پایتون متنباز و رایگان است که صفحات وب را به Markdown تمیز، JSON ساختاریافته یا HTML فیلترشده تبدیل میکند که مدلهای زبانی بزرگ میتوانند مستقیماً از آن استفاده کنند. این کتابخانه که بر پایه Playwright برای اتوماسیون مرورگر ساخته شده است، به توسعهدهندگانی که خطوط لوله RAG میسازند، خدمت میکند. AI این ابزار از هر دو استراتژی استخراج مبتنی بر LLM و بدون LLM پشتیبانی میکند و به تیمها کنترل کامل بر هزینه و کیفیت خروجی را میدهد.
با بیش از ۶۰،۰۰۰ ستاره گیتهاب و بیش از ۹۰۰،۰۰۰ دانلود ماهانه PyPI، Crawl4AI به یکی از محبوبترین ابزارهای وب اسکرپینگ در ... تبدیل شده است. AI جامعه مهندسی. این کاملاً بر روی زیرساخت شخصی شما اجرا میشود، بنابراین هیچ کلید API مورد نیاز نیست و هیچ هزینهای برای هر صفحه وجود ندارد. برای تیمهایی که به استخراج دادهها در مقیاس تولید نیاز دارند اتوماسیون تجاری، خزیدن۴AI انعطافپذیری لازم برای اتصال به هر ارائهدهنده LLM را ارائه میدهد، در حالی که لایه خزنده را کاملاً آزاد نگه میدارد.
خزیدن4AI همانطور که در سایت رسمی آن توضیح داده شده است، دو نوع خروجی Markdown تولید میکند. Clean Markdown قالببندی دقیق صفحه را با عناوین، جداول، بلوکهای کد و نکات استناد حفظ میکند. Fit Markdown از طریق یک الگوریتم هرس یا امتیازدهی مرتبط BM25، فیلتر مبتنی بر اکتشاف را برای حذف نویزهای تکراری، ناوبری و پاورقی اعمال میکند.
این خروجی دوگانه به طور خاص برای خطوط لوله RAG و مصرف مستقیم LLM طراحی شده است. کاربران همچنین میتوانند سفارشیسازی کنند. تولید نشانهگذاری استراتژیهایی برای مطابقت با الزامات دقیق خط لوله آنها.
این ابزار دو مسیر استخراج مجزا ارائه میدهد. برای صفحاتی با طرحبندیهای قابل پیشبینی، JsonCssExtractionStrategy مبتنی بر CSS و XPath، JSON ساختاریافته را با استفاده از تعاریف طرحواره استخراج میکند و نیازی به فراخوانی LLM ندارد.
برای صفحات پیچیده یا غیرقابل پیشبینی، LLMExtractionStrategy به هر ارائهدهنده LLM (OpenAI، Ollama، DeepSeek و دیگران) متصل میشود و از طرحوارههای Pydantic برای بازگرداندن دادههای کاملاً ساختاریافته استفاده میکند. استراتژیهای قطعهبندی شامل پردازش مبتنی بر موضوع، regex و سطح جمله، صفحات بزرگ را به طور مؤثر مدیریت میکنند.
خزش تطبیقی که در crawl4ai.com به عنوان یک قابلیت شاخص معرفی شد، از الگوریتمهای جستجوی اطلاعات با یک سیستم امتیازدهی سه لایه استفاده میکند که پوشش، ثبات و اشباع را اندازهگیری میکند. به جای خزش در هر صفحه از سایت، ارزیابی میکند ارتباط محتوا در هر مرحله و به طور خودکار زمانی که آستانههای اطمینان برآورده شوند، متوقف میشود.
این برنامه از هر دو استراتژی آماری (سریع، رایگان، مبتنی بر اصطلاح) و استراتژی جاسازی (درک معنایی با گسترش پرس و جو) پشتیبانی میکند. این امر از خزش بیش از حد جلوگیری کرده و منابع محاسباتی قابل توجهی را ذخیره میکند.
سه لایه که در نسخه ۰.۸.۵ معرفی شد سیستم تشخیص ضد ربات امضاهای شناختهشدهی فروشنده، شاخصهای بلوک عمومی و یکپارچگی ساختاری صفحات برگشتی را بررسی میکند. هنگامی که یک بلوک شناسایی میشود، سیستم بهطور خودکار از طریق یک زنجیره پروکسی قابل تنظیم با توابع بازیابی مجدد، دوباره تلاش میکند. این امر در ترکیب با حالت مخفی که رفتار کاربر واقعی را تقلید میکند و حالت مرورگر شناسایی نشده از نسخه ۰.۷.۳، Crawl4 را ارائه میدهد.AI یک ابزار قوی برای دسترسی به سایتهای محافظتشده.
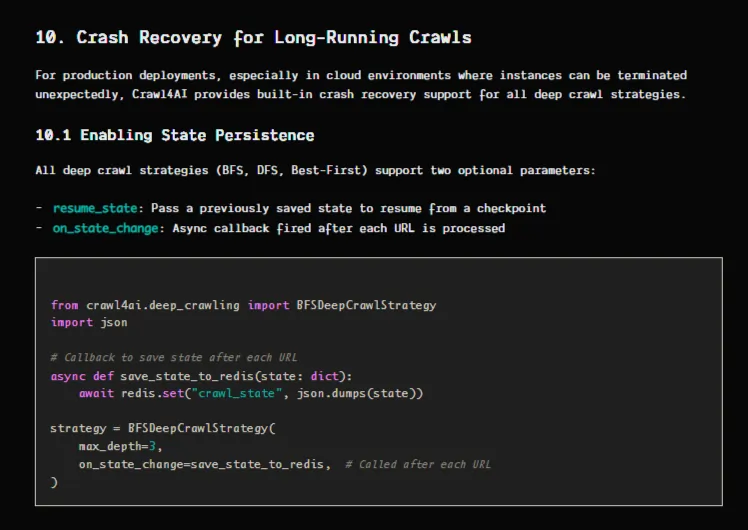
برای کارهای بزرگ که هزاران صفحه را در بر میگیرند، استراتژیهای خزش عمیق (BFS، DFS، Best First) شامل بازیابی خرابی داخلی هستند که در نسخه ۰.۸.۰ منتشر شده است. فراخوانی on_state_change وضعیت را پس از هر URL حفظ میکند و پارامتر resume_state به شما امکان میدهد پس از یک شکست، از نقطه بازرسی دقیق ادامه دهید.
حالت پیشواکشی، تولید و استخراج Markdown را به طور کامل حذف میکند و امکان کشف URL را با سرعت ۵ تا ۱۰ برابر حالت عادی برای گردشهای کاری خزش دو مرحلهای فراهم میکند.
خزیدن4AI یک تصویر Docker بهینهشده ارائه میدهد که شامل یک سرور FastAPI، احراز هویت توکن JWT، یک داشبورد مانیتورینگ بلادرنگ با معیارهای سیستم زنده و یک مخزن مرورگر سه لایه (دائمی، گرم، سرد) با پیشگرمایش صفحه است. این محیط تعاملی به تیمها اجازه میدهد پیکربندیهای خزش را آزمایش کرده و کد درخواست را بدون نوشتن اسکریپت تولید کنند.
ادغام MCP مستقیماً به آن متصل میشود AI ابزارهایی مانند Claude Code. پشتیبانی از معماری چندگانه با تشخیص خودکار AMD64 و ARM64، اجرای آن را بر روی هر ارائهدهنده ابری تضمین میکند.
خزیدن4AI برنامه های قیمت گذاری
| نام برنامه | هزینه | جزئیات کلیدی |
|---|---|---|
| متنباز (خود-میزبان) | $0 | خزشهای نامحدود، مجموعه کامل ویژگیها، شما زیرساخت را فراهم میکنید |
| رابط برنامهنویسی کاربردی ابری (نسخه بتا بسته) | سفارشی | خدمات مدیریتشده، درخواست دسترسی زودهنگام، ظرفیت محدود |
| حامی مؤمن | $ 5 / ماه | حمایت جامعه، از پروژه حمایت میکند |
| حامی سازنده | $ 50 / ماه | پشتیبانی ویژه و دسترسی زودهنگام به ویژگیهای جدید |
| حامی تیم در حال رشد | $ 500 / ماه | همگامسازیهای هفتگی بای و راهنماییهای بهینهسازی |
| شریک زیرساخت داده | $ 2,000 / ماه | پشتیبانی اختصاصی و مشارکت کامل |
چگونه خزیدن۴AI آیا تولید Markdown را مدیریت میکند؟
خزیدن4AI دو نوع خروجی Markdown تولید میکند. Raw Markdown ساختار کامل صفحه شامل عناصر ناوبری و پاورقیها را حفظ میکند. Fit Markdown با استفاده از یک الگوریتم هرس یا امتیازدهی مرتبط BM25، فیلتر اکتشافی را اعمال میکند تا نویز را حذف کرده و فقط محتوای اصلی را نگه دارد. این امر به ویژه برای خطوط لوله RAG که کیفیت جاسازی به متن ورودی تمیز بستگی دارد، ارزشمند است.
شما همچنین میتوانید با گسترش کلاس پایه، استراتژیهای تولید Markdown سفارشی را پیادهسازی کنید و کنترل کاملی بر نحوه نگاشت عناصر HTML به توکنهای Markdown داشته باشید. سیستم استناد، لینکهای صفحه را به ارجاعات شمارهگذاری شده تبدیل میکند که به LLMها کمک میکند تا در طول وظایف بازیابی، انتساب منبع را ردیابی کنند.
مزایا و معایب
- بیش از ۶۰،۰۰۰ ستاره، جامعه فعال.
- مجوز مجاز آپاچی ۲.۰.
- با هر ارائه دهنده LLM کار می کند.
- معماری ناهمگام برای افزایش سرعت
- بازیابی خرابی ناشی از خزش عمیق به صورت داخلی.
- هنوز هیچ سرویس ابری مدیریتشدهای وجود ندارد.
- بدون رابط کاربری گرافیکی یا رابط بصری.
- مدیریت ضد ربات نیاز به تنظیم پروکسی دارد.
بهترین خزیدن۴AI جایگزین
| AI خزنده و اسکریپر وب | گزینه میزبانی شخصی | استخراج رایگان LLM |
|---|---|---|
| خزش آتشین | محدود (محدودیتهای AGPL 3.0 اعمال میشود) | خیر، برای JSON ساختاریافته به LLM نیاز دارد |
| Apify | خیر، پلتفرم کاملاً وابسته به فضای ابری | نه، متکی است AI مدلهایی برای تجزیه |
| ScrapeGraphAI | بله، کتابخانه پایتون متنباز (MIT) | خیر، هر استخراجی نیاز به یک تماس LLM دارد |

