Fuegos artificiales AI Ideas clave
¿Qué es Fireworks AI?
IA de fuegos artificiales es una plataforma de inferencia de alto rendimiento diseñada específicamente para desarrolladores y empresas que necesitan ejecutar, optimizar y escalar software de código abierto. AI modelos a velocidad de producción. Fundada por antiguos miembros del equipo PyTorch en Meta, la plataforma proporciona un OpenAI API compatible que permite el acceso a más de 100 modelos de lenguaje, modelos de visión y modelos de generación de imágenes populares y de gran tamaño.
Fuegos artificiales AI elimina la carga operativa de administrar la infraestructura de GPU al ofrecer opciones de implementación tanto sin servidor como bajo demanda. Las empresas utilizan Fireworks AI para potenciar los chatbots, asistentes de codificación, motores de búsqueda y agentes AI flujos de trabajo. Su motor de inferencia personalizado ofrece un rendimiento hasta 4 veces mayor y una latencia un 50 % menor que las pilas de servicio de código abierto estándar, lo que lo convierte en uno de los más rápidos. AI Proveedores de API disponibles hoy para generación automática AI cargas de trabajo de producción.
El motor de inferencia patentado de Fireworks AI está diseñado desde cero para la velocidad. Ofrece consistentemente una latencia del primer token inferior a 100 milisegundos en una amplia gama de tamaños de modelos. Para cualquier aplicación que requiera capacidad de respuesta en tiempo real, como chatbots de cara al cliente o asistentes de codificación con agentesEsta ventaja en el rendimiento es cuantificable y significativa. Empresas como Sourcegraph y Notion han constatado públicamente mejoras en el rendimiento tras migrar a la plataforma.
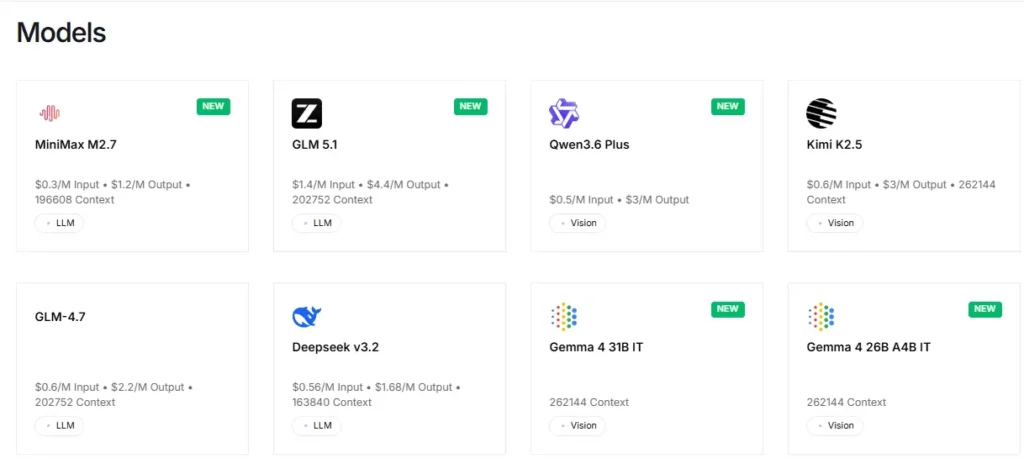
La plataforma proporciona acceso instantáneo a más de 100 modelos de código abierto, incluidos Llama, Qwen, DeepSeek, Kimi K2.5, GLM 5, Mixtral y FLUX. generadores de imagenLos desarrolladores pueden probar e intercambiar modelos a través de un único punto final de API sin necesidad de realizar cambios de configuración. Esto hace que la creación rápida de prototipos y las pruebas A/B entre familias de modelos sean extremadamente eficientes.
Fuegos artificiales AI Admite una amplia gama de métodos de ajuste fino, incluyendo LoRA, ajuste fino supervisado de parámetros completos, DPO (alineación de preferencias) y ajuste fino por refuerzo. Es fundamental destacar que los modelos ajustados se ofrecen al mismo precio que los modelos base, eliminando el sobreprecio que imponen muchos competidores. También admite el ajuste fino de modelos de lenguaje visual, lo que permite a los equipos personalizar modelos multimodales con sus propios conjuntos de datos de imágenes y texto.
Para cargas de trabajo que necesitan recursos dedicados, Fireworks AI ofertas a pedido Implementaciones de GPU Facturación por segundo. La gama de hardware ahora incluye las GPU NVIDIA A100, H100, H200, B200 y B300. Esto brinda a los equipos de ingeniería la flexibilidad de ejecutar instancias de modelos privadas y aisladas con capacidad garantizada y sin problemas de interferencia.
Fire Pass, una novedad reciente, es una suscripción de 7 dólares semanales que proporciona acceso ilimitado a tokens para el modelo Kimi K2.5 Turbo a velocidades de entre 200 y 250 tokens por segundo. Está diseñada específicamente para desarrolladores que utilizan herramientas de codificación ágínica como Claude Code y OpenCode, ofreciendo una alternativa de tarifa plana a la facturación impredecible por token.
Fuegos artificiales AI Planes de Precios
| Nombre del Plan | Costo | Detalles Clave |
|---|---|---|
| Sin servidor (modelos pequeños) | 0.10$ por 1 millón de tokens | Modelos con parámetros 4B |
| Sin servidor (Nivel intermedio) | 0.20$ por 1 millón de tokens | Parámetros de los modelos 4B a 16B |
| Sin servidor (modelos grandes) | 0.90$ por 1 millón de tokens | Modelos con más de 16 mil millones de parámetros |
| Sin servidor (modelos MoE) | De 0.50 a 1.20 dólares por millón de tokens. | Modelos de mezcla de expertos de clase Mixtral |
| Pase de bomberos | $ 7 por semana | Fichas ilimitadas para Kimi K2.5 Turbo |
| Bajo demanda (H100) | $6.00 por hora de GPU | Facturación por segundo, instancia dedicada |
| Bajo demanda (B200) | $9.00 por hora de GPU | GPU de última generación, facturada por segundo. |
| Empresa | Personalizado | Descuentos anuales, acuerdos de nivel de servicio (SLA) e implementaciones privadas. |
Primeros pasos con Fireworks AI
- Paso 1: Crear una cuenta en fuegos artificiales.aiRecibirás automáticamente 1 dólar en créditos gratuitos al registrarte.
- Paso 2: Dirígete a la sección Claves API de tu panel de control y genera una nueva clave API.
- Paso 3: Instale el cliente Python de Fireworks o utilice cualquier OpenAI SDK compatible. Dirige tu URL base al punto final de la API de Fireworks.
- Paso 4: Seleccione un modelo de la biblioteca de modelos, realice su primera llamada a la API y supervise el uso y la facturación desde la consola.
Pros y contras
- Velocidad de inferencia líder en la industria.
- Más de 100 modelos de código abierto disponibles.
- Incluye un completo proceso de ajuste fino.
- Fire Pass ofrece fichas ilimitadas.
- Hardware de GPU de última generación (B300).
- Panel de control exclusivo para desarrolladores, sin código.
- No cuenta con herramientas integradas para la gestión del flujo de trabajo empresarial.
- La atención al cliente puede ser lenta.
Los mejores fuegos artificiales AI Alternativas
| AI Plataforma de inferencia y servicio de modelos | Rendimiento de inferencia | Reducción de costes |
|---|---|---|
| Juntos IA | 917 TPS, latencia más alta (0.78 s) | Tasas por token similares, menor variedad de GPU. |
| Groq | 456 TPS mediante LPU personalizadas, latencia de 0.19 s. | Precios de entrada más bajos, selección de modelos limitada. |
| Reproducir exactamente | Velocidad moderada, basado en contenedores. | Facturación sencilla por predicción, menos ajustes finos. |
| Basetén | Infraestructura personalizable, velocidad moderada | Flexible, pero requiere más configuración. |

