
Los ajustes rápidos por sí solos ya no son suficientes para las empresas AI sistemas. A medida que las ventanas de contexto del modelo superan los 200 tokens, los ingenieros ahora envuelven el LLM con documentos, canales de recuperación, cuadernos de notas y llamadas a herramientas, un enfoque que se ha convertido en una marca registrada. ingeniería de contexto.
El cambio se produjo rápidamente.
La ingeniería de contexto cierra esta brecha al tratar el contexto completo. AI entorno empresarial como un sistema en lugar de centrarse en las aportaciones individuales.
Ingeniería de contexto:
El sistema que realmente funciona
La ingeniería de contexto trata todo el proceso de desarrollo antes de la convocatoria de LLM como una infraestructura ingenierable. Piense en un LLM's ventana de contexto como RAM: tiene una memoria de trabajo limitada que determina lo que el modelo puede procesar.
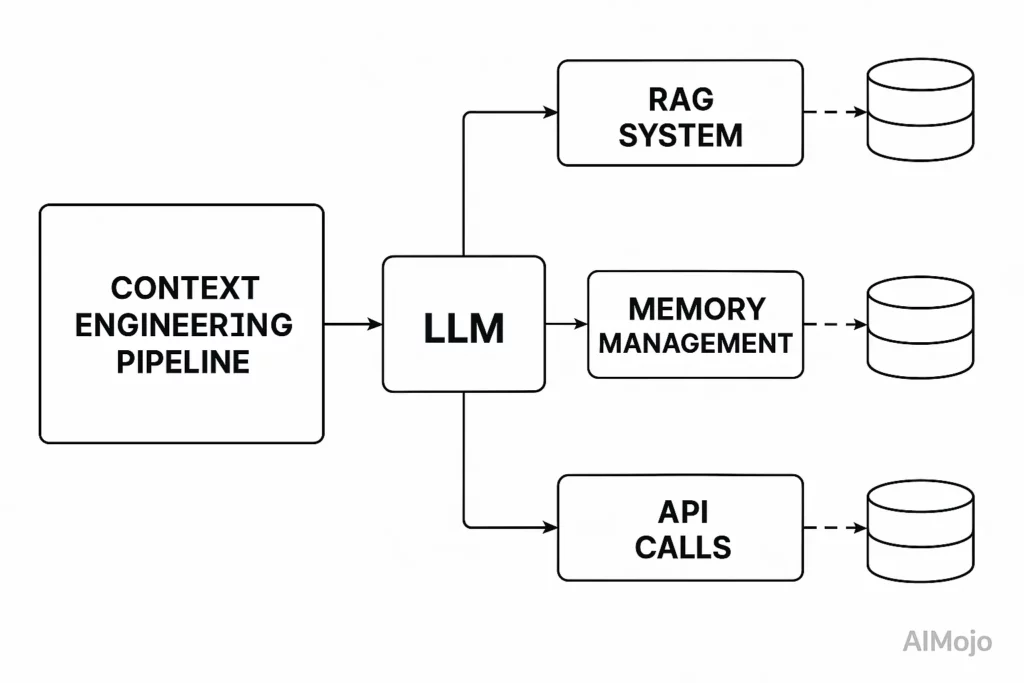
Así como un sistema operativo administra cuidadosamente lo que entra en la RAM, la ingeniería de contexto selecciona qué información llena la LLM.'s ventana de contexto.
Aquí's Qué incluye realmente la ingeniería de contexto:
Ingeniería de contexto vs. ingeniería de indicaciones:
Los números no mienten
| Aspecto | Ingeniería rápida | Ingeniería de contexto |
|---|---|---|
| Enfócate | Creación de una cadena de entrada | Orquestando cada señal alrededor del modelo |
| Tiempo promedio de desarrollo | 70% de ajustes rápidos | 60% canalizaciones de datos, 20% reglas de memoria, 20% indicaciones |
| Modo de falla típico | Caída repentina de la calidad de salida después de una desviación de los datos | Resistente a través de RAG, memoria y llamadas de herramientas |
Ejemplo rapido: Un bot de atención al cliente Un bot entrenado solo con indicaciones puede recordar la política de reembolso cuando se le pregunta directamente. Cuando el usuario menciona el "pedido 45791", falla. Añada la ingeniería de contexto (historial de conversaciones y una consulta RAG a la base de datos de pedidos) y el bot extrae al instante los detalles de la compra y recomienda el proceso de reembolso correcto.
Los cuatro pilares de la ingeniería de contexto que realmente importan
1. Contexto de escritura (su IA)'s Sistema de toma de notas)
Escribir contexto significa guardar información fuera del contexto. ventana de contexto. Para uso futuro. Esto preserva valioso espacio de tokens y mantiene el acceso a datos importantes.
Bloc de notas Funcionan como toma de notas para los agentes en una sola sesión. Antrópico's El investigador multiagente guarda su plan inicial para “Salud Cerebral"porque si el contexto supera los 200,000 tokens, se trunca y el plan se pierde.

Memorias a largo plazo Retienen información a lo largo de varias sesiones. Algunos ejemplos incluyen la generación automática de preferencias de usuario a partir de conversaciones por parte de ChatGPT y el aprendizaje de Cursor/Windsurf. patrones de codificación y el contexto del proyecto.

2. Selección de contexto (El arte de elegir lo que importa)
La selección de contexto aporta únicamente la información relevante para la tarea en cuestión.
Cuando un AI Entrenador físico genera un plan de entrenamiento, debe seleccionar detalles de contexto que incluyan al usuario's altura, peso y nivel de actividad, ignorando información irrelevante.
La idea claveMás información no siempre es mejor. Una ingeniería de contexto eficaz implica seleccionar la combinación adecuada para cada tarea específica.
3. Compresión del contexto (hacer que encaje más en menos)
Cuando las conversaciones se hacen tan largas que exceden el tiempo LLM's memoria En la ventana, la compresión del contexto se vuelve crucial. Los agentes suelen lograr esto resumiendo las primeras partes de la conversación.

4. Aislamiento del contexto (divide y vencerás)
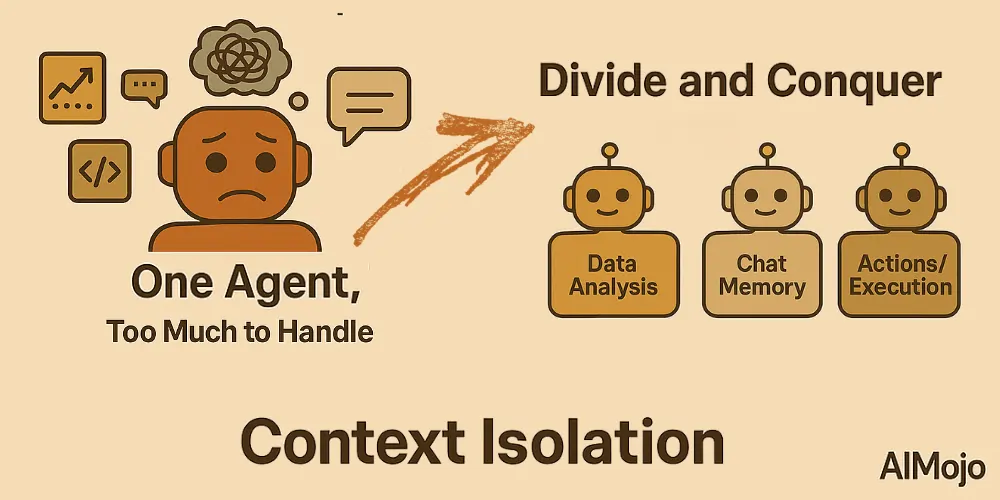
El aislamiento del contexto implica descomponer la información en partes separadas para que los agentes puedan gestionar mejor las tareas complejas. En lugar de concentrar todo el conocimiento en una sola instrucción masiva, los desarrolladores dividen el contexto entre subagentes especializados o entornos sandbox.
Ingeniería de contexto del mundo real en acción
La revolución del servicio al cliente
| Antes de la ingeniería de contexto | Después de la ingeniería de contexto |
|---|---|
| Chatbots genéricos que olvidan conversaciones anteriores y proporcionan respuestas irrelevantes. | AI Agentes que recuerdan su historial de compras, acceden a datos de inventario en tiempo real y se coordinan con agentes humanos cuando sea necesario. |
El asistente de codificación que nunca olvida
El sistema de:Cuando preguntas "¿Cómo soluciono este error de autenticación?", el sistema de ingeniería de contexto automáticamente:

En lugar de consejos de codificación genéricos, obtendrá soluciones específicas adaptadas a su base de código real.
La arquitectura técnica que impulsa la ingeniería de contexto
Ensamblaje de contexto dinámico
El contexto se construye sobre la marcha y evoluciona a medida que avanzan las conversaciones. Esto incluye:
- Recuperación de documentos relevantes
- Mantener la memoria
- Actualización del estado del usuario
- Llamadas API y consultas a bases de datos
Gestión de ventanas de contexto
Con tamaño fijo límites de tokens (32K, 100K, 1M), los ingenieros deben comprimir y priorizar la información de forma inteligente utilizando:
- Funciones de puntuación (TF-IDF, incrustaciones, heurísticas de atención)
- Resumen y extracción de prominencia
- Estrategias de fragmentación y ajuste de superposición

Seguridad y consistencia
Aplicar principios como la detección rápida de inyecciones, saneamiento del contexto, Redacción de PIIy control de acceso al contexto basado en roles.
Construyendo su primer sistema de ingeniería de contexto
Crear un flujo de trabajo de ingeniería de contexto no es solo teoría; es's Un proceso repetible que puede implementarse e incluso automatizarse. Así es como puedes ponerlo en práctica:
Paso 1: Mapee sus fuentes de contexto
Identifique de dónde su agente necesita extraer información (documentos, bases de datos, API, chats anteriores, etc.).
pitón
# Example: Fetching relevant documents using embeddings
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer("all-MiniLM-L6-v2")
query = "project status update"
corpus = ["spec doc", "requirements", "last week's meeting notes"]
query_embedding = model.encode(query, convert_to_tensor=True)
corpus_embeddings = model.encode(corpus, convert_to_tensor=True)
hits = util.semantic_search(query_embedding, corpus_embeddings, top_k=2)[0]
relevant_docs = [corpus[hit['corpus_id']] for hit in hits]
Paso 2: Implementar la memoria y el contexto de escritura
Almacene información importante para que siempre esté disponible para futuras tareas.
pitón
import json
def save_to_memory(memory_path, user_id, data):
with open(memory_path, "r+") as file:
memory = json.load(file)
memory[user_id] = data
file.seek(0)
json.dump(memory, file)
file.truncate()Paso 3: Crear lógica de selección y compresión de contexto
Desarrollar reglas o modelos que seleccionen solo lo más relevante para la tarea. Resumir los historiales extensos.
pitón
def summarize_conversation(history):
# Placeholder for use with an LLM summarizer or custom rules
return history[-5:] # Only the last 5 messagesPaso 4: Aislar contextos para la coordinación de agentes
Divida la información para que cada agente o componente maneje únicamente lo que debe.
pitón
user_profile_ctx = {"user_goals": "..."}
task_specific_ctx = {"current_task": "..."}
external_data_ctx = {"live_data": "..."}
full_context = {**user_profile_ctx, **task_specific_ctx, **external_data_ctx}Paso 5: Estructuración de salida y preparación de API
Formatee el contexto de salida de manera consistente para que's predecible para llamadas LLM posteriores o puntos finales de API.
pitón
schema = {
"user": {"age": 35, "goal": "muscle gain"},
"plan": "high protein, 3x/week weight training"
}Paso 6: Monitorear, iterar y proteger
Monitoree los fallos, audite la calidad del contexto y mejore la lógica de inclusión, memoria y recuperación del contexto. Siempre depure las entradas para evitar la inyección de información y las fugas de datos.
Por qué la ingeniería de contexto paga más que la ingeniería rápida
Las empresas necesitan ingenieros que puedan construir sistemas que proporcionen el contexto adecuado a la IA, mantengan la información precisa y actualizada, y protejan a los usuarios agregando pautas de seguridad.
La realidad del mercado:La ingeniería de contexto requiere habilidades multifuncionales que involucran comprender casos de uso comercial, definir resultados y estructurar información para que los LLM puedan realizar tareas complejas.
En pocas palabras: Cualquiera puede escribir indicaciones. ¿Desarrollar agentes contextuales que recuerden, adapten y seleccionen el contexto a gran escala? Así es como los desarrolladores optimizan sus habilidades para el futuro y aportan valor real con aplicaciones LLM avanzadas.



 BONUS: Obtenga nuestros $200 “AI “Mastery Toolkit” ¡GRATIS cuando te registras!
BONUS: Obtenga nuestros $200 “AI “Mastery Toolkit” ¡GRATIS cuando te registras!






