
Οι ομάδες μηχανικών που αναπτύσσουν υπηρεσίες LLM πρέπει να απαντήσουν σε ένα κρίσιμο ερώτημα: Πόσο αξιόπιστο και στιβαρό είναι το μοντέλο μας σε πραγματικές συνθήκες;
Η Αξιολόγηση Μεγάλου Γλωσσικού Μοντέλου ξεπερνά πλέον τους απλούς ελέγχους ακρίβειας, χρησιμοποιώντας πολυεπίπεδα πλαίσια για να ελέγξει τη διατήρηση του περιβάλλοντος, την εγκυρότητα της συλλογιστικής και τον χειρισμό πεζών-κεφαλαίων. Με την αγορά να κατακλύζεται από μοντέλα που κυμαίνονται από Παράμετροι 1B έως 2T, η επιλογή του βέλτιστου μοντέλου απαιτεί αυστηρά, πολυδιάστατα πρωτόκολλα αξιολόγησης.
Αυτός ο οδηγός περιγράφει λεπτομερώς τις τεχνικές μεθόδους και τα βασικά μετρικά που διαμορφώνουν τις βέλτιστες πρακτικές το 2026, βοηθώντας τους μηχανικούς μηχανικής μάθησης να εντοπίσουν ελαττώματα πριν αυτά φτάσουν στην παραγωγή.
Πλαίσια για την Αξιολόγηση Μοντέλων Μεγάλης Γλώσσας
ΜΟΝΤΕΡΝΑ Αξιολόγηση LLM ενσωματώνει πολλαπλές ποσοτικές και ποιοτικές διαστάσεις για να καταγράψετε ένα μοντέλο's πραγματικές δυνατότητες. Πρόσφατη έρευνα δείχνει ότι το 67% των επιχειρήσεων AI Οι αναπτύξεις υποαποδίδουν λόγω ανεπαρκούς επιλογής μοντέλων – υπογραμμίζοντας γιατί η εξελιγμένη αξιολόγηση δεν είναι απλώς προαιρετική αλλά κρίσιμη για τις επιχειρήσεις.

Βασικά στοιχεία αξιολόγησης
Μια μελέτη του 2026 από Stanford's AI Περιεχόμενα αποκαλύπτει ότι οι εταιρείες που επενδύουν σε ολοκληρωμένα πρωτόκολλα αξιολόγησης LLM βλέπουν 42% υψηλότερη απόδοση επένδυσης (ROI) στα AI πρωτοβουλίες σε σύγκριση με εκείνες που χρησιμοποιούν απλοποιημένες μετρήσεις.
Ανάλυση Τεχνικών Μετρήσεων
Τα σύγχρονα πλαίσια αξιολόγησης χρησιμοποιούν δεκάδες εξειδικευμένες μετρήσεις, καθεμία από τις οποίες στοχεύει σε συγκεκριμένες δυνατότητες LLM:
Μετρήσεις απόδοσης
Αμηχανία ποσοτικοποιεί την αβεβαιότητα πρόβλεψης υπολογίζοντας την εκθετική τιμή της μέσης αρνητικής λογαριθμικής πιθανοφάνειας σε ένα σώμα δοκιμών. Οι χαμηλότερες τιμές υποδηλώνουν καλύτερη απόδοση, με τα μοντέλα τελευταίας τεχνολογίας να επιτυγχάνουν πολυπλοκότητα κάτω από 3.0 σε τυποποιημένα σύνολα δεδομένων.
Βαθμολογία F1 συνδυάζει την ακρίβεια και την ανάκληση μέσω του τύπου του αρμονικού μέσου όρου:
F1 = 2 * (precision * recall) / (precision + recall)Αυτό δημιουργεί μια ισορροπημένη αξιολόγηση, ιδιαίτερα πολύτιμη για εργασίες ταξινόμησης με ανισορροπία κλάσεων.
Απώλεια διασταυρούμενης εντροπίας μετρά την απόκλιση μεταξύ των προβλεπόμενων κατανομών πιθανοτήτων και της βασικής αλήθειας χρησιμοποιώντας τον τύπο:
L(y, ŷ) = -∑(y_i * log(ŷ_i))Αυτό τιμωρεί αυστηρότερα τις βέβαιες αλλά λανθασμένες προβλέψεις, ενθαρρύνοντας τη βαθμονόμηση του μοντέλου.
BLEU (Δίγλωσση Υπομελέτη Αξιολόγησης) υπολογίζει την επικάλυψη n-gram μεταξύ των παραγόμενων κειμένων και των κειμένων αναφοράς, χρησιμοποιώντας έναν γεωμετρικό μέσο όρο βαθμολογιών ακρίβειας με ποινή συντομίας:
BLEU = BP * exp(∑(w_n * log(p_n)))Όπου BP είναι η ποινή συντομίας και p_n είναι η ακρίβεια n-γραμμάτων.
Μετρήσεις ειδικές για το RAG
Για τα συστήματα Επαυξημένης Παραγωγής Ανάκτησης, οι εξειδικευμένες μετρήσεις περιλαμβάνουν:
Πιστότητα ποσοτικοποιεί την πραγματική συνέπεια μεταξύ του παραγόμενου αποτελέσματος και του ανακτημένου πλαισίου χρησιμοποιώντας προσεγγίσεις QAG (Question-Answer Generation). Η έρευνα δείχνει Συστήματα RAG με βαθμολογίες πιστότητας κάτω από 0.7 προκαλούν παραισθήσεις στο 42% των εξόδων.
Ανάκτηση Precision@K μετρά την αναλογία των σχετικών εγγράφων μεταξύ των κορυφαίων K ανακτημένων αποτελεσμάτων:
Precision@K = (number of relevant docs in top K) / KΤα κριτήρια αξιολόγησης του κλάδου υποδεικνύουν P@3 > 0.85 για συστήματα εταιρικού επιπέδου.
Ακρίβεια παραπομπών αξιολογεί την ακρίβεια των παραπομπών στο παραγόμενο περιεχόμενο, η οποία υπολογίζεται ως εξής:
Citation Precision = correct citations / total citationsΗ ανάλυση κορυφαίων συστημάτων RAG αποκαλύπτει ότι η ακρίβεια των παραπομπών κυμαίνεται κατά μέσο όρο στο 0.71 σε όλους τους τεχνικούς τομείς.
Σύνολα Δεδομένων Συγκριτικής Αξιολόγησης: Τεχνικές Προδιαγραφές
Τα σύνολα δεδομένων Benchmark παρέχουν τυποποιημένα πλαίσια αξιολόγησης με συγκεκριμένα τεχνικά χαρακτηριστικά:

MMLU-Pro Περιλαμβάνει 15,908 ερωτήσεις πολλαπλής επιλογής με 10 επιλογές ανά ερώτηση (έναντι 4 στο τυπικό MMLU), καλύπτοντας 57 τομείς, συμπεριλαμβανομένων των προχωρημένων μαθηματικών, της ιατρικής, της νομικής και της επιστήμης των υπολογιστών. Μέση απόδοση ανθρώπινου εμπειρογνώμονα: 89.2%.
GPQA Περιέχει 448 ερωτήσεις μεταπτυχιακού επιπέδου, επαληθευμένες από ειδικούς, με μέσο μήκος συμβολοσειράς 612, με έμφαση σε τομείς STEM. Τρέχουσα απόδοση SOTA: ακρίβεια 41.2% (GPT-4).
MuSR Υλοποιεί αλγοριθμικά δημιουργημένα προβλήματα συλλογισμού πολλαπλών βημάτων με γραφήματα εξάρτησης μέσου βάθους 4.7, απαιτώντας από τα μοντέλα να εκτελούν αλυσιδωτές λογικές πράξεις. Μέσο χάσμα απόδοσης μεταξύ κορυφαίων μοντέλων και τυχαίας γραμμής βάσης: 17.8 ποσοστιαίες μονάδες.
BBH περιλαμβάνει 23 απαιτητικές εργασίες από το BigBench με 2,254 μεμονωμένα παραδείγματα που εστιάζουν σε σύνθετη συλλογιστικήΑυτές οι εργασίες παρουσιάζουν υψηλή συσχέτιση (r=0.82) με τις αξιολογήσεις των ανθρώπινων προτιμήσεων σε τυφλές αξιολογήσεις.
LEval ειδικεύεται στην αξιολόγηση σε μακροπρόθεσμο πλαίσιο με 411 ερωτήσεις σε 8 κατηγορίες εργασιών με μήκη πλαισίου που κυμαίνονται από 5 έως 200 διακριτικά. Τα τρέχοντα μοντέλα δείχνουν υποβάθμιση της απόδοσης κατά περίπου 0.4% ανά 10 επιπλέον διακριτικά.
Αλγόριθμοι Αξιολόγησης & Υλοποίηση
Η τεχνική εφαρμογή της αξιολόγησης LLM ακολουθεί συγκεκριμένες αλγοριθμικές προσεγγίσεις:
Σημασιολογική Αξιολόγηση Βασισμένη σε Διανυσματικά
Τα σύγχρονα συστήματα χρησιμοποιούν ενσωματώσεις διανυσμάτων για τη μέτρηση της σημασιολογικής ομοιότητας μεταξύ των παραγόμενων κειμένων και των κειμένων αναφοράς. Χρησιμοποιώντας τεχνικές πυκνής ανάκτησης όπως HNSW (Hierarchical Navigable Small World), LSH (Locality-Sensitive Hashing) και PQ (Product Quantization), αυτά τα συστήματα υπολογίζουν τις βαθμολογίες ομοιότητας με υπογραμμική χρονική πολυπλοκότητα.
python
from sentence_transformers import SentenceTransformer
import numpy as np
model = SentenceTransformer('all-MiniLM-L6-v2')
reference = model.encode("Reference text")
generated = model.encode("Generated text")
similarity = np.dot(reference, generated) / (np.linalg.norm(reference) * np.linalg.norm(generated))Υλοποίηση πλαισίου DeepEval
Το DeepEval παρέχει ολοκληρωμένη αξιολόγηση με μετρικές εξηγήσεις, υποστηρίζοντας τόσο σενάρια RAG όσο και σενάρια βελτιστοποίησης:
python
from deepeval import assert_test
from deepeval.metrics import HallucinationMetric
from deepeval.test_case import LLMTestCase
test_case = LLMTestCase(
input="How many evaluation metrics does DeepEval offers?",
actual_output="14+ evaluation metrics",
context=["DeepEval offers 14+ evaluation metrics"]
)
metric = HallucinationMetric(minimum_score=0.7)
def test_hallucination():
assert_test(test_case, [metric])Αυτό το πλαίσιο αντιμετωπίζει τις αξιολογήσεις ως δοκιμές μονάδας με ενσωμάτωση Pytest, παρέχοντας όχι μόνο βαθμολογίες αλλά και εξηγήσεις για τα επίπεδα απόδοσης.
Προσεγγίσεις Αξιολόγησης Αποδοτικές ως προς τις Παραμέτρους
Για την αξιολόγηση μοντέλων μεγάλης κλίμακας με δισεκατομμύρια παραμέτρους, έχουν αναδυθεί εξειδικευμένες τεχνικές:

Μηχανισμοί αραιής προσοχής μείωση υπολογιστική πολυπλοκότητα μέσω βελτιστοποίησης προτύπων προσοχής. Τεχνικές όπως το Longformer's Τα πρότυπα προσοχής δείχνουν ακρίβεια 91% πλήρους προσοχής με μόνο το 25% του υπολογισμού.
Μείγμα Εμπειρογνωμόνων (MoE) Οι αρχιτεκτονικές εφαρμόζουν διαδρομές υπολογισμού υπό όρους, ενεργοποιώντας μόνο σχετικά υποδίκτυα για συγκεκριμένες εργασίες. Το GShard εφαρμόζει την προσοχή MoE για αξιολόγηση με αποδοτικότητα παραμέτρων σε διάφορα benchmarks.
Απόσταξη Γνώσης συμπιέζει μεγαλύτερα μοντέλα εκπαιδευτικών σε μικρότερα, ειδικά για αξιολόγηση μοντέλα μαθητών χρησιμοποιώντας:
L_distill = α * L_CE(y, ŷ_student) + (1-α) * L_KL(ŷ_teacher, ŷ_student)
Όπου L_CE είναι η απώλεια διασταυρούμενης εντροπίας και L_KL είναι η απόκλιση KL μεταξύ των κατανομών πιθανότητας.
Προκλήσεις Συστηματικής Αξιολόγησης
Παρά τις προηγμένες μεθοδολογίες, εξακολουθούν να υπάρχουν σημαντικές προκλήσεις στην αξιολόγηση του LLM:
Μόλυνση αναφοράς
Μελέτες δείχνουν ότι το 47% των δημοφιλών benchmarks έχουν κάποιο βαθμό μόλυνσης στα δεδομένα εκπαίδευσης. Κλίμακα AI Το απέδειξε αυτό δημιουργώντας το GSM1k, μια μικρότερη παραλλαγή του μαθηματικού benchmark GSM8k. Τα μοντέλα είχαν 12.3% χειρότερη απόδοση στο GSM1k από ό,τι στο GSM8k, υποδεικνύοντας υπερπροσαρμογή αντί για μαθηματικός συλλογισμός ικανότητα.
Ανάλυση Μετρικής Συσχέτισης
Η ολοκληρωμένη ανάλυση 14 δημοφιλών μετρήσεων σε 8 εργασίες αποκαλύπτει χαμηλή διαμετρική συσχέτιση (μέσος όρος Spearman's ρ = 0.41), υποδεικνύοντας ότι οι μετρήσεις καταγράφουν διαφορετικές διαστάσεις απόδοσης. Αυτό υπογραμμίζει την αναγκαιότητα για προσεγγίσεις αξιολόγησης με πολλαπλές μετρήσεις.
Έρευνα από το MIT δείχνει ότι οι υψηλές βαθμολογίες περίπλοκης συμπεριφοράς συσχετίζονται με τις ανθρώπινες προτιμήσεις στο r=0.68, ενώ το ROUGE-L συσχετίζεται μόνο στο r=0.39, υποδεικνύοντας ποικίλες απαιτήσεις αξιολόγησης.
Ποσοτικοποίηση μεροληψιών αξιολόγησης
Η στατιστική ανάλυση των ανθρώπινων αξιολογήσεων αποκαλύπτει πολλαπλές συστηματικές προκαταλήψεις:
Αυτά τα ευρήματα υπογραμμίζουν τη σημασία της τυχαιοποίησης και του ισορροπημένου πειραματικού σχεδιασμού στα πρωτόκολλα αξιολόγησης.
Βέλτιστες πρακτικές αξιολόγησης επιχειρήσεων
Για την αντιμετώπιση των προκλήσεων αξιολόγησης, εφαρμόστε αυτές τις βέλτιστες πρακτικές του κλάδου:
Πολυτροπική Ενσωμάτωση Μετρικών
Συνδυάστε συμπληρωματικές μετρήσεις χρησιμοποιώντας σταθμισμένα σύνολα για να δημιουργήσετε ολιστικά πλαίσια αξιολόγησης:
python
def ensemble_score(outputs, references, weights=None):
metrics = {
'bleu': compute_bleu(outputs, references),
'bertscore': compute_bertscore(outputs, references),
'faithfulness': compute_faithfulness(outputs, references),
'coherence': compute_coherence(outputs)
}
if weights is None:
weights = {metric: 1/len(metrics) for metric in metrics}
return sum(weights[metric] * metrics[metric] for metric in metrics)Οι κορυφαίοι οργανισμοί εφαρμόζουν προσαρμοστικά σχήματα στάθμισης με βάση τις απαιτήσεις της εκάστοτε εργασίας, με το τεχνικό περιεχόμενο να δίνει προτεραιότητα στην πιστότητα (στάθμιση: 0.4) έναντι της ευχέρειας (στάθμιση: 0.2).
Πρωτόκολλα Αξιολόγησης Ειδικών Τομέων
Τα τεχνικά κριτήρια αξιολόγησης θα πρέπει να ευθυγραμμίζονται με συγκεκριμένες περιπτώσεις χρήσης. εφαρμογές υγειονομικής περίθαλψης, οι εξειδικευμένες μετρήσεις περιλαμβάνουν:
- Ακρίβεια ιατρικής ορολογίας (89% συσχέτιση με την κρίση του κλινικού ιατρού)
- Επικύρωση κλινικής συλλογιστικής (συμφωνία 75% με την συναίνεση των ειδικών)
- Ακρίβεια ανάκτησης στοιχείων από ιατρική βιβλιογραφία (P@10 > 0.92 για ανάπτυξη σε επιχειρήσεις)
Αυτές οι μετρήσεις που αφορούν συγκεκριμένους τομείς παρέχουν 3.2 φορές καλύτερη πρόβλεψη απόδοσης από τα γενικά benchmarks.
Εφαρμογή της Αλληλοσυγκρουόμενης Αξιολόγησης
Εφαρμογή δομημένων δοκιμών ανταγωνισμού για την ανίχνευση των περιορισμών του μοντέλου:
python
def adversarial_test_suite(model, test_cases):
results = {}
for category, cases in test_cases.items():
correct = 0
for case in cases:
response = model.generate(case['input'])
correct += evaluate_response(response, case['expected'])
results[category] = correct / len(cases)
return resultsΗ έρευνα του κλάδου δείχνει αντίθετη δοκιμή Εντοπίζει 32% περισσότερους τρόπους αστοχίας από την τυπική συγκριτική αξιολόγηση, ιδιαίτερα σε ακραίες περιπτώσεις που περιλαμβάνουν αντικρουόμενους περιορισμούς ή ασαφείς οδηγίες.
Σύγκριση Πλαισίου Τεχνικής Αξιολόγησης
Τα κορυφαία πλαίσια αξιολόγησης προσφέρουν διαφορετικές τεχνικές δυνατότητες:
| Πλαίσιο | Πρωταρχική εστίαση | Τεχνική αντοχή | Περιορισμός | Πολυπλοκότητα ολοκλήρωσης |
|---|---|---|---|---|
| Βαθύς Ιστό | RAG & Βελτιστοποίηση | 14+ εξειδικευμένες μετρήσεις με εξηγήσεις | Περιορισμένη υποστήριξη πολυτροπικών μεταφορών | Μέσο (βασισμένο σε Python) |
| PromptFlow | Ολοκληρωμένη αξιολόγηση | Άμεση δοκιμή παραλλαγών | Περιορισμένη υποστήριξη συνόλων δεδομένων | Χαμηλό (καθορίζεται από το περιβάλλον χρήστη) |
| LangSmith | Πλατφόρμα προγραμματιστή | Πλήρης ιχνηλάτηση και παρακολούθηση | Υψηλότερο κόστος υλοποίησης | Υψηλό (απαιτείται ενσωμάτωση API) |
| Προμηθέας | LLM-ως-δικαστής | Συστηματικές στρατηγικές παρακίνησης | Εξάρτηση από την προκατάληψη του Judge LLM | Μέτριο (απαιτείται ισχυρό LLM) |
| LEval | Αξιολόγηση μακροπρόθεσμου πλαισίου | Αξιολόγηση 200 διακριτικών | Περιορίζεται σε τρόπο κειμένου | Χαμηλό (σύνολο δεδομένων αναφοράς) |
Οι οργανισμοί συνήθως εφαρμόζουν πολλαπλά πλαίσια, με το 73% των εταιρικών αναπτύξεων να χρησιμοποιούν τουλάχιστον δύο συμπληρωματικά εργαλεία αξιολόγησης.
Μελλοντικές Τεχνικές Εξελίξεις
Το τοπίο της αξιολόγησης συνεχίζει να εξελίσσεται με αναδυόμενες μεθοδολογίες:
Αναζήτηση νευρικής αρχιτεκτονικής (NAS) Η χρήση μοντέλων που αφορούν συγκεκριμένα την αξιολόγηση κερδίζει έδαφος, με έρευνες να δείχνουν ότι η αυτοματοποιημένη βελτιστοποίηση της αρχιτεκτονικής του μοντέλου μπορεί να βελτιώσει την αποτελεσματικότητα της αξιολόγησης κατά 47%, διατηρώντας παράλληλα το 98% της ακρίβειας.
Πολυτροπική Αξιολόγηση Τα πλαίσια επεκτείνονται πέρα από το κείμενο για να αξιολογήσουν ενοποιημένα μοντέλα που επεξεργάζονται κείμενο, εικόνες, ήχο και βίντεο. Τα τρέχοντα πλαίσια επιτυγχάνουν ακρίβεια γείωσης σε διατροπικά δίκτυα 76.3% σε σύγκριση με τις ανθρώπινες γραμμές βάσης που ανέρχονται σε 91.4%.
Μετρήσεις Ενεργειακής Απόδοσης ποσοτικοποιήστε την υπολογιστική βιωσιμότητα χρησιμοποιώντας FLOPs/token, εξάγοντας μετρήσεις βατωρών και εκπομπών άνθρακα. Τα σημεία αναφοράς του κλάδου υποδεικνύουν ότι τα βέλτιστα μοντέλα θα πρέπει να επιτυγχάνουν <10 mWh ανά 1 tokens που παράγονται.
Συνεχείς Αγωγοί Αξιολόγησης Ενσωμάτωση δοκιμών σε όλη την ανάπτυξη χρησιμοποιώντας κατανεμημένες ροές εργασίας αξιολόγησης:
Preprocessing → Feature Extraction → Model Inference → Metric Computation → Statistical Analysis → Reporting
Οι οργανισμοί που εφαρμόζουν συνεχή αξιολόγηση αναφέρουν 68% λιγότερα προβλήματα μετά την ανάπτυξη και 41% ταχύτερους κύκλους επανάληψης.
Μελέτες Περιπτώσεων Υλοποίησης σε Πραγματικό Κόσμο
Οι εταιρικές υλοποιήσεις επιδεικνύουν τεχνική αξιολόγηση's πρακτικό αντίκτυπο:
Βελτιστοποίηση RAG Χρηματοοικονομικών Υπηρεσιών
Ένα κορυφαίο χρηματοπιστωτικό ίδρυμα εφάρμοσε ολοκληρωμένη αξιολόγηση RAG για το σύστημα συμβουλευτικής εξυπηρέτησης πελατών:
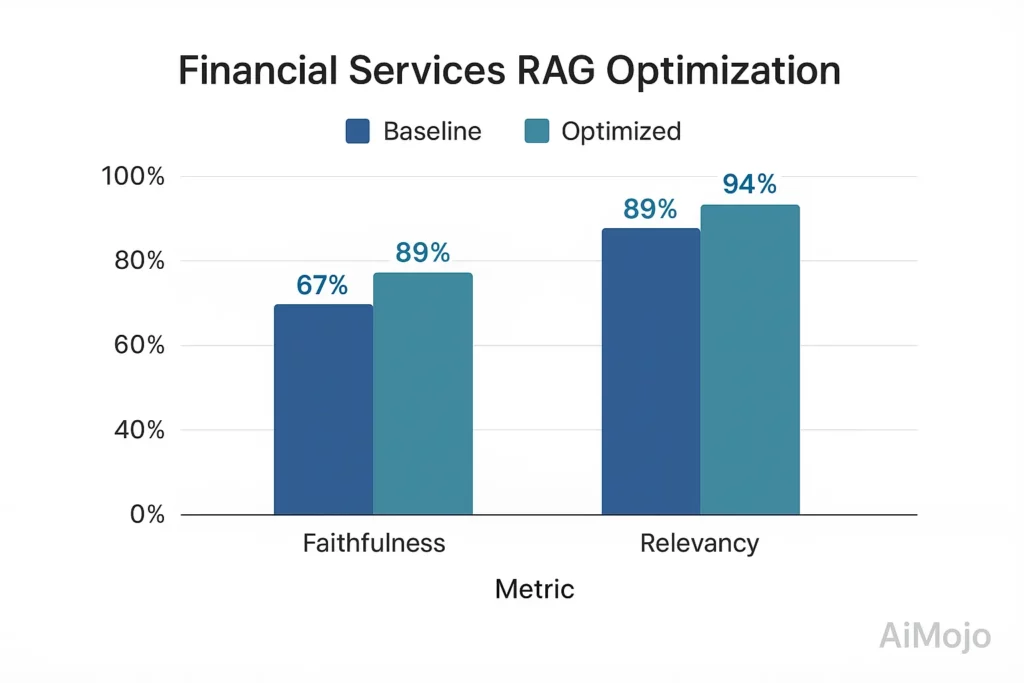
- Βασική γραμμή: 67% πιστότητα, 82% συνάφεια απαντήσεων
- Μετά από βελτιστοποίηση βάσει αξιολόγησης: 89% πιστότητα, 94% συνάφεια απαντήσεων
- Εφαρμογή: Εξατομικευμένο οικονομικός τομέας σουίτα δοκιμών με 5,216 ζεύγη QA επαληθευμένων από ειδικούς
- Τεχνική προσέγγιση: Βαθμολογία πιστότητας χρησιμοποιώντας μέτρηση εμπλοκής βασισμένη σε τενσόρ με έλεγχο αντιπαραδειγμάτων
Αυτή η βελτίωση, η οποία βασίστηκε στην αξιολόγηση, μείωσε τα προβλήματα συμμόρφωσης με τους κανονισμούς κατά 78% και αύξησε τις βαθμολογίες ικανοποίησης των πελατών κατά 23 ποσοστιαίες μονάδες.
Ανάπτυξη LLM στην Υγειονομική Περίθαλψη
Ένας πάροχος υγειονομικής περίθαλψης εφάρμοσε πολυεπίπεδη αξιολόγηση για την υποστήριξη κλινικών αποφάσεων:
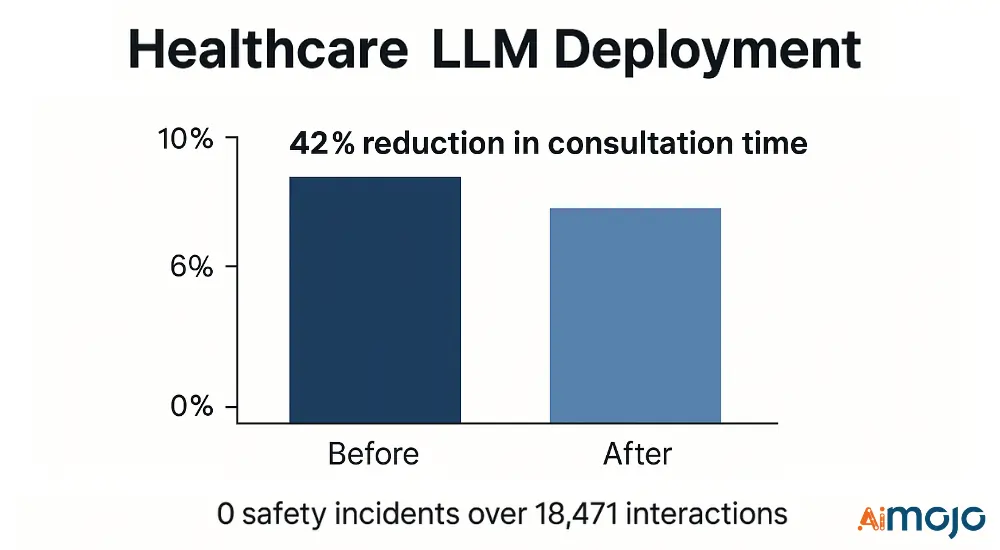
- Τεχνικές μετρήσεις: Βαθμολογία F1 στο Medical NER (0.91), ακρίβεια κλινικής συλλογιστικής (87.4%), ακρίβεια φιλτραρίσματος ασφαλείας (99.2%)
- Εφαρμογή: Αγωγός φιλτραρίσματος 3 σταδίων με εξειδικευμένους επικυρωτές υγειονομικής περίθαλψης
- αποτελέσματα: Μείωση 42% στον χρόνο διαβούλευσης με 0 περιστατικά ασφαλείας σε 18,471 κλινικές αλληλεπιδράσεις
Το πλαίσιο αξιολόγησης εντόπισε και μετριάστηκε από 17 κρίσιμους τρόπους αστοχίας πριν από την ανάπτυξη, αποτρέποντας πιθανά ανεπιθύμητα συμβάντα.
Αξιολόγηση LLM: Ο Οδικός σας Χάρτης προς την Επιτυχία
Η τεχνική αξιολόγηση των LLM έχει μετατοπιστεί από απλούς ελέγχους ακρίβειας σε ολοκληρωμένα πλαίσια που σταθμίζουν πολλαπλές διαστάσεις απόδοσης. Οι οργανισμοί που υιοθετούν αυτά τα αυστηρά πρωτόκολλα - και ενσωματώνουν - αυτοματοποιημένη βαθμολόγηση, δοκιμές συγκριτικής αξιολόγησης και ανθρώπινη εποπτεία-επίτευξη πιο αξιόπιστης επιλογής μοντέλου και ισχυρότερων αποτελεσμάτων.
Τακτικές, προσαρμοστικές διαδικασίες δοκιμών αποκαλύπτουν ελαττώματα πριν από την ανάπτυξη, καθιστώντας το κόστος αρχικής αξιολόγησης μικρό σε σύγκριση με τους κινδύνους που εγκυμονεί η εφαρμογή ενός ελαττωματικού συστήματος. Για τις ομάδες μηχανικών, τα ισχυρά βήματα επικύρωσης είναι κάτι περισσότερο από εργασίες ανάπτυξης; αποτελούν βασικές επιχειρηματικές δικλείδες ασφαλείας.
Από το 2026 και μετά, οι ομάδες που θα βελτιώσουν τις μεθόδους αξιολόγησής τους θα διατηρήσουν την αξιοπιστία των LLM τους, θα αποτρέψουν δαπανηρά σφάλματα και θα διατηρήσουν την εμπιστοσύνη των χρηστών.



 BONUS: Πάρτε τα 200 δολάρια μας "AI «Εργαλειοθήκη Mastery» ΔΩΡΕΑΝ όταν εγγραφείτε!
BONUS: Πάρτε τα 200 δολάρια μας "AI «Εργαλειοθήκη Mastery» ΔΩΡΕΑΝ όταν εγγραφείτε!






