Fireworks AI Wichtige Erkenntnisse
Was ist Fireworks AI?
Feuerwerks-KI ist eine leistungsstarke Inferenzplattform, die speziell für Entwickler und Unternehmen entwickelt wurde, die Open-Source-Software ausführen, feinabstimmen und skalieren müssen. AI Modelle in Produktionsgeschwindigkeit. Die Plattform wurde von ehemaligen Mitgliedern des PyTorch-Teams bei Meta gegründet und bietet eine offeneAI Kompatible API, die Zugriff auf über 100 gängige große Sprachmodelle, Bildverarbeitungsmodelle und Bildgenerierungsmodelle ermöglicht.
Fireworks AI Fireworks beseitigt den operativen Aufwand für die Verwaltung der GPU-Infrastruktur durch serverlose und bedarfsorientierte Bereitstellungsoptionen. Unternehmen nutzen Fireworks. AI um Chatbots zu betreiben KodierassistentenSuchmaschinen und Agenten AI Workflows. Die eigens entwickelte Inferenz-Engine bietet einen bis zu 4-fach höheren Durchsatz und eine um 50 % geringere Latenz als herkömmliche Open-Source-Server-Stacks und ist damit einer der schnellsten AI Heute verfügbare API-Anbieter für generative AI Produktionsauslastung.
Die proprietäre Inferenz-Engine von Fireworks AI wurde von Grund auf auf Geschwindigkeit optimiert. Sie liefert konstant eine Latenzzeit des ersten Tokens von unter 100 Millisekunden über ein breites Spektrum an Modellgrößen hinweg. Für jede Anwendung, die Echtzeit-Reaktionsfähigkeit erfordert, wie z. B. kundenorientierte Chatbots oder agentenbasierte CodierungsassistentenDieser Leistungsvorteil ist messbar und signifikant. Unternehmen wie Sourcegraph und Notion haben nach der Migration auf die Plattform öffentlich von Durchsatzsteigerungen berichtet.
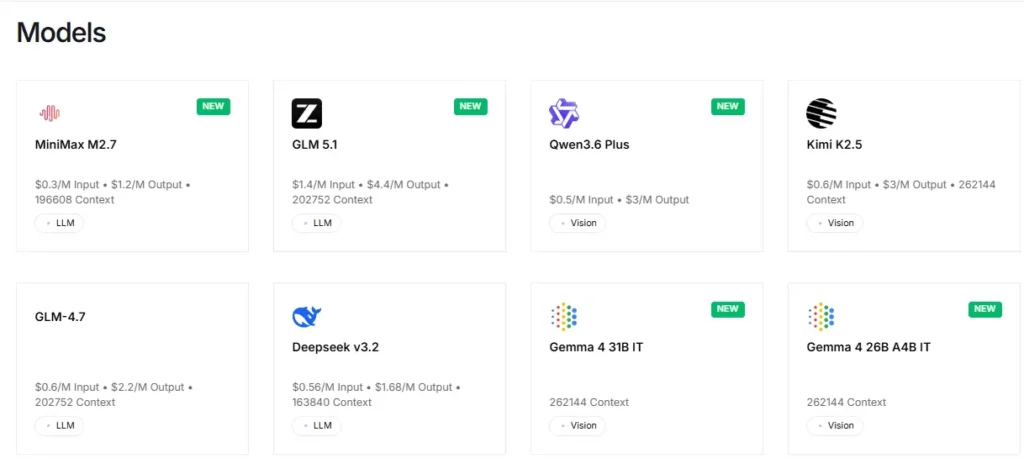
Die Plattform bietet sofortigen Zugriff auf mehr als 100 Open-Source-Modelle, darunter Llama, Qwen, DeepSeek, Kimi K2.5, GLM 5, Mixtral und FLUX. BildgeneratorenEntwickler können Modelle über einen einzigen API-Endpunkt testen und zwischen ihnen wechseln, ohne Konfigurationsänderungen vornehmen zu müssen. Dies ermöglicht ein äußerst effizientes Rapid Prototyping und A/B-Testing über verschiedene Modellfamilien hinweg.
Fireworks AI Unterstützt werden alle gängigen Feinabstimmungsmethoden, darunter LoRA, überwachtes Feinabstimmen mit vollständigen Parametern, DPO (Präferenzausrichtung) und Reinforcement Learning. Entscheidend ist, dass feinabgestimmte Modelle zum gleichen Preis wie Basismodelle angeboten werden, wodurch die hohen Kosten vieler Mitbewerber entfallen. Auch die Feinabstimmung von Bild- und Sprachmodellen wird unterstützt, sodass Teams multimodale Modelle mit ihren eigenen Bild- und Textdatensätzen anpassen können.
Für Arbeitslasten, die dedizierte Ressourcen benötigen, bietet sich Fireworks an. AI Angebote auf Anfrage GPU-Bereitstellungen Die Abrechnung erfolgt sekundengenau. Die Hardware-Produktpalette umfasst nun NVIDIA A100-, H100-, H200-, B200- und B300-GPUs. Dies ermöglicht es Entwicklungsteams, private, isolierte Modellinstanzen mit garantierter Kapazität und ohne Störungen durch benachbarte Systeme auszuführen.
Fire Pass ist ein neues Angebot: Ein Abonnement für 7 US-Dollar pro Woche, das unbegrenzten Token-Zugriff auf das Kimi K2.5 Turbo-Modell mit Geschwindigkeiten von etwa 200 bis 250 Token pro Sekunde bietet. Es wurde speziell für Entwickler entwickelt, die agentenbasierte Codierungswerkzeuge wie Claude Code und OpenCode verwenden, und bietet eine pauschale Alternative zu unvorhersehbaren Token-Abrechnungen.
Fireworks AI Tarifpläne
| Plan Name | Kosten | Produktdetails |
|---|---|---|
| Serverlos (Kleine Modelle) | 0.10 $ pro 1 Mio. Token | Modelle unter 4B-Parametern |
| Serverlos (mittlere Preisklasse) | 0.20 $ pro 1 Mio. Token | Parameter der Modelle 4B bis 16B |
| Serverlos (Große Modelle) | 0.90 $ pro 1 Mio. Token | Modelle mit über 16 Milliarden Parametern |
| Serverlos (MoE-Modelle) | 0.50 bis 1.20 US-Dollar pro 1 Million Token | Mixtral-Klassenmischung von Expertenmodellen |
| Feuerpass | $ 7 pro Woche | Unbegrenzte Kimi K2.5 Turbo-Token |
| Auf Anfrage (H100) | 6.00 $ pro GPU-Stunde | Abrechnung pro Sekunde, dedizierte Instanz |
| Auf Anfrage (B200) | 9.00 $ pro GPU-Stunde | Neueste GPU-Generation, Abrechnung pro Sekunde |
| Unternehmen | Maßgeschneidert | Jährliche Rabatte, SLAs und private Implementierungen |
Erste Schritte mit Fireworks AI
- Schritt 1: Erstelle ein Konto bei Feuerwerk.aiSie erhalten bei der Anmeldung automatisch 1 $ Startguthaben.
- Schritt 2: Navigieren Sie in Ihrem Dashboard zum Abschnitt „API-Schlüssel“ und generieren Sie einen neuen API-Schlüssel.
- Schritt 3: Installieren Sie den Fireworks Python-Client oder verwenden Sie einen beliebigen Open-Source-Client.AI Kompatibles SDK. Verweisen Sie Ihre Basis-URL auf den Fireworks-API-Endpunkt.
- Schritt 4: Wählen Sie ein Modell aus der Modellbibliothek, führen Sie Ihren ersten API-Aufruf durch und überwachen Sie Nutzung und Abrechnung über die Konsole.
Vor-und Nachteile
- Branchenführende Inferenzgeschwindigkeit.
- Mehr als 100 Open-Source-Modelle verfügbar.
- Vollständige Feinabstimmungspipeline enthalten.
- Fire Pass bietet unbegrenzte Token.
- Neueste GPU-Generation (B300).
- Nur für Entwickler, kein Code erforderlich, kostenloses Dashboard.
- Keine integrierten Tools für Geschäftsprozesse.
- Der Kundensupport kann langsam sein.
Bestes Feuerwerk AI Alternativen
| AI Inferenz- und Modellbereitstellungsplattform | Inferenzdurchsatz | Kosteneffizienz |
|---|---|---|
| Gemeinsam KI | 917 Transaktionen pro Sekunde, höhere Latenz (0.78 s) | Ähnliche Preise pro Token, geringere GPU-Vielfalt |
| Groq | 456 Transaktionen pro Sekunde über kundenspezifische LPUs, 0.19 Sekunden Latenz | Niedrigere Einstiegspreise, begrenzte Modellauswahl |
| Replizieren | Mittlere Geschwindigkeit, containerbasiert | Einfache Abrechnung pro Vorhersage, weniger Feinabstimmung |
| Baseten | Anpassbare Infrastruktur, moderate Geschwindigkeit | Flexibel, erfordert aber mehr Konfiguration |

