
Schnelle Optimierungen allein reichen für Unternehmen nicht mehr aus AI Systeme. Da die Modellkontextfenster immer mehr als 200 Token umfassen, umhüllen Ingenieure das LLM nun mit Dokumenten, Abfragepipelines, Notizblöcken und Tool-Aufrufen – ein Ansatz, der als Kontext-Engineering.
Der Wandel erfolgte schnell.
Context Engineering schließt diese Lücke, indem es die gesamte AI Umwelt als System, anstatt sich auf einzelne Eingaben zu konzentrieren.
Kontext-Engineering:
Das System, das tatsächlich funktioniert
Kontext-Engineering behandelt die gesamte Pipeline vor dem LLM-Aufruf als entwicklungsfähige Infrastruktur. Stellen Sie sich ein LLM vor's Kontextfenster als RAM – es verfügt über einen begrenzten Arbeitsspeicher, der bestimmt, was das Modell verarbeiten kann.
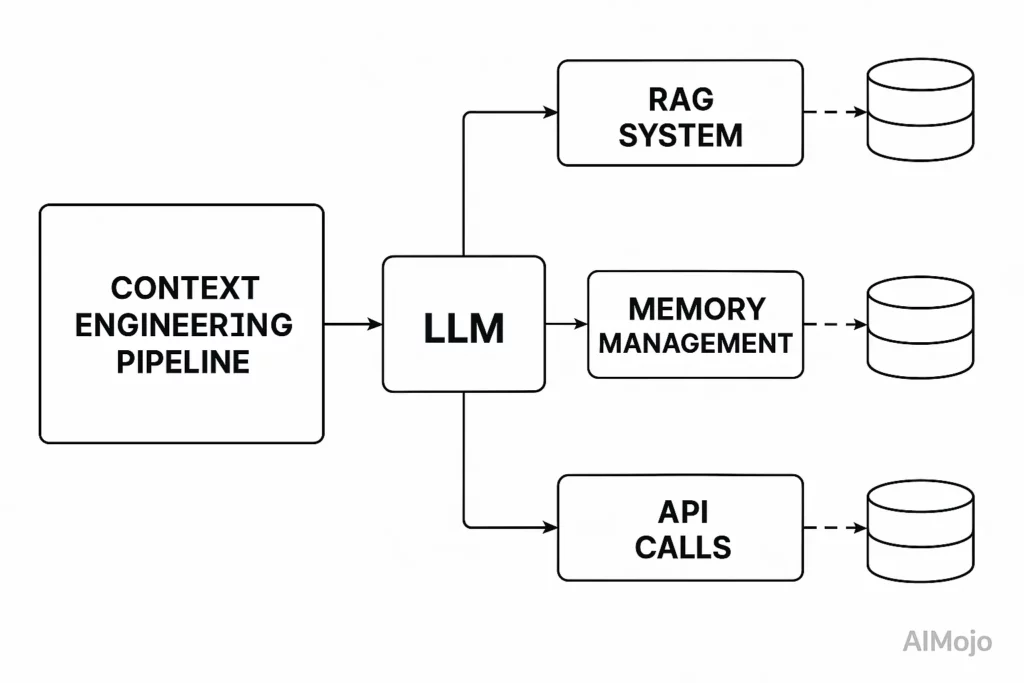
So wie ein Betriebssystem sorgfältig verwaltet, was in den RAM gelangt, kuratiert Context Engineering, welche Informationen das LLM füllen's Kontextfenster.
Hier's was Context Engineering eigentlich beinhaltet:
Kontext-Engineering vs. Prompt-Engineering:
Die Zahlen lügen nicht
| Aspekt | Schnelles Engineering | Kontext-Engineering |
|---|---|---|
| Optik | Erstellen einer Eingabezeichenfolge | Orchestrierung aller Signale rund um das Modell |
| Durchschnittliche Entwicklungszeit | 70 % schnelle Optimierungen | 60 % Datenpipelines, 20 % Speicherregeln, 20 % Eingabeaufforderungen |
| Typischer Fehlermodus | Plötzlicher Abfall der Ausgabequalität nach Datendrift | Resilient durch RAG, Speicher, Tool-Aufrufe |
Schnelles Beispiel: Ein Kundensupport-Bot Nur mit Eingabeaufforderungen trainierte Bots können die Rückerstattungsrichtlinien auf direkte Nachfrage abrufen. Bei der Eingabe von „Bestellung 45791“ schlägt die Rückgabe fehl. Durch Kontext-Engineering – Gesprächsverlauf plus RAG-Abfrage in der Bestelldatenbank – ruft der Bot sofort die Kaufdetails ab und empfiehlt den richtigen Rückerstattungsprozess.
Die vier Säulen des Kontext-Engineerings, die wirklich wichtig sind
1. Schreibkontext (Ihre KI's Notizsystem)
Kontext schreiben bedeutet, Informationen außerhalb des Kontextfenster für die zukünftige Verwendung. Dadurch bleibt wertvoller Token-Speicherplatz erhalten, während der Zugriff auf wichtige Daten erhalten bleibt.
Notizblöcke Arbeit wie Notizen für Agenten innerhalb einer einzigen Sitzung. Anthropische's Der Multi-Agenten-Forscher speichert seinen ursprünglichen Plan auf „Memory„Denn wenn der Kontext 200,000 Token überschreitet, wird er abgeschnitten und der Plan geht verloren.

Langzeitgedächtnis Informationen über mehrere Sitzungen hinweg speichern. Beispiele hierfür sind ChatGPT, das automatisch Benutzereinstellungen aus Konversationen generiert, und Cursor/Windsurf-Lernen Codierungsmuster und Projektkontext.

2. Kontextauswahl (Die Kunst, das Wesentliche auszuwählen)
Durch die Kontextauswahl werden nur die für die jeweilige Aufgabe relevanten Informationen angezeigt.
wenn ein AI Fitnesstrainer einen Trainingsplan erstellt, muss es Kontextdetails auswählen, die den Benutzer einschließen's Größe, Gewicht und Aktivitätsniveau, während irrelevante Informationen ignoriert werden.
Die wichtigste Erkenntnis: Mehr Informationen sind nicht immer besser. Effektives Context Engineering bedeutet, für jede spezifische Aufgabe die richtige Kombination auszuwählen.
3. Kontextkomprimierung (Mehr in weniger hineinpacken)
Wenn Gespräche so lange dauern, dass sie die LLM's Erinnerung Im Kontextfenster ist die Kontextkomprimierung entscheidend. Agenten erreichen dies normalerweise, indem sie frühere Teile des Gesprächs zusammenfassen.

4. Kontextisolation (Teile und herrsche)
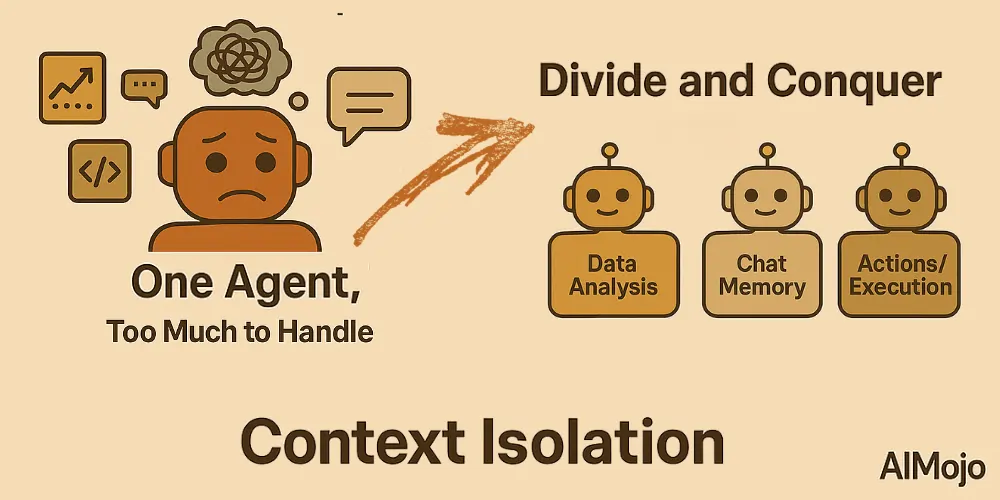
Kontextisolierung bedeutet, Informationen in einzelne Teile zu zerlegen, damit Agenten komplexe Aufgaben besser bewältigen können. Anstatt alles Wissen in eine einzige Eingabeaufforderung zu packen, teilen Entwickler den Kontext auf spezialisierte Subagenten auf oder Sandbox-Umgebungen.
Real-World Context Engineering in Aktion
Die Kundenservice-Revolution
| Vor dem Kontext-Engineering | Nach dem Kontext-Engineering |
|---|---|
| Generische Chatbots, die vorherige Gespräche vergessen und irrelevante Antworten liefern. | AI Agenten, die sich an Ihren Kaufverlauf erinnern, auf Lagerbestandsdaten in Echtzeit zugreifen und sich bei Bedarf mit menschlichen Agenten abstimmen. |
Der Codierassistent, der nie vergisst
Das System: Wenn Sie fragen „Wie behebe ich diesen Authentifizierungsfehler?“, führt das Kontext-Engineering-System automatisch Folgendes aus:

Anstelle allgemeiner Codierungsratschläge erhalten Sie spezifische Lösungen, die auf Ihre tatsächliche Codebasis zugeschnitten sind.
Die technische Architektur hinter Context Engineering
Dynamische Kontextassemblierung
Der Kontext wird spontan erstellt und entwickelt sich im Verlauf des Gesprächs weiter. Dazu gehören:
- Abrufen relevanter Dokumente
- Gedächtnis bewahren
- Aktualisieren des Benutzerstatus
- API-Aufrufe und Datenbankabfragen
Kontextfensterverwaltung
Mit fester Größe Token-Grenzwerte (32K, 100K, 1M) müssen Ingenieure Informationen intelligent komprimieren und priorisieren, indem sie Folgendes verwenden:
- Bewertungsfunktionen (TF-IDF, Einbettungen, Aufmerksamkeitsheuristiken)
- Zusammenfassung und Salienzextraktion
- Chunking-Strategien und Overlap-Tuning

Sicherheit und Konsistenz
Anwendung von Prinzipien wie der sofortigen Injektionserkennung, Kontextbereinigung, PII-Schwärzungund rollenbasierte Kontextzugriffskontrolle.
Erstellen Sie Ihr erstes Context Engineering-System
Der Aufbau eines Context Engineering Workflows ist nicht nur Theorie, sondern's Ein wiederholbarer Prozess, der operationalisiert und sogar automatisiert werden kann. So können Sie ihn in die Praxis umsetzen:
Schritt 1: Ordnen Sie Ihre Kontextquellen zu
Ermitteln Sie, woher Ihr Agent Informationen abrufen muss (Dokumente, Datenbanken, APIs, vorherige Chats usw.).
python
# Example: Fetching relevant documents using embeddings
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer("all-MiniLM-L6-v2")
query = "project status update"
corpus = ["spec doc", "requirements", "last week's meeting notes"]
query_embedding = model.encode(query, convert_to_tensor=True)
corpus_embeddings = model.encode(corpus, convert_to_tensor=True)
hits = util.semantic_search(query_embedding, corpus_embeddings, top_k=2)[0]
relevant_docs = [corpus[hit['corpus_id']] for hit in hits]
Schritt 2: Implementieren Sie Speicher- und Schreibkontext
Speichern Sie wichtige Informationen, damit sie für zukünftige Aufgaben immer zur Verfügung stehen.
python
import json
def save_to_memory(memory_path, user_id, data):
with open(memory_path, "r+") as file:
memory = json.load(file)
memory[user_id] = data
file.seek(0)
json.dump(memory, file)
file.truncate()Schritt 3: Erstellen Sie eine Kontextauswahl- und Komprimierungslogik
Entwickeln Sie Regeln oder Modelle, die nur das auswählen, was für die Aufgabe am relevantesten ist. Komprimieren Sie lange Historien in zusammengefasster Form.
python
def summarize_conversation(history):
# Placeholder for use with an LLM summarizer or custom rules
return history[-5:] # Only the last 5 messagesSchritt 4: Isolieren Sie Kontexte für die Agentenkoordination
Teilen Sie Informationen auf, sodass jeder Agent oder jede Komponente nur das verarbeitet, was er/sie verarbeiten soll.
python
user_profile_ctx = {"user_goals": "..."}
task_specific_ctx = {"current_task": "..."}
external_data_ctx = {"live_data": "..."}
full_context = {**user_profile_ctx, **task_specific_ctx, **external_data_ctx}Schritt 5: Ausgabestrukturierung und API-Bereitschaft
Formatieren Sie den Ausgabekontext konsistent, sodass er's vorhersehbar für nachgelagerte LLM-Aufrufe oder API-Endpunkte.
python
schema = {
"user": {"age": 35, "goal": "muscle gain"},
"plan": "high protein, 3x/week weight training"
}Schritt 6: Überwachen, iterieren und sichern
Verfolgen Sie Fehler, prüfen Sie die Kontextqualität und verbessern Sie die Logik für Kontexteinbindung, Speicher und Abruf. Bereinigen Sie Eingaben stets, um eine sofortige Injektion und Datenlecks zu vermeiden.
Warum Context Engineering mehr zahlt als Prompt Engineering
Unternehmen brauchen Ingenieure, die Systeme entwickeln können, die der KI den richtigen Kontext verleihen, die Informationen präzise und aktuell halten und die Benutzer durch zusätzliche Sicherheitsrichtlinien schützen.
Die Marktrealität: Kontext-Engineering erfordert funktionsübergreifende Fähigkeiten, die das Verständnis von Geschäftsanwendungsfällen, das Definieren von Ergebnissen und das Strukturieren von Informationen umfassen, damit LLMs komplexe Aufgaben bewältigen können.
Bottom line: Jeder kann Eingabeaufforderungen schreiben. Möchten Sie kontextsensitive Agenten erstellen, die Kontexte speichern, anpassen und in großem Umfang auswählen? So sichern Entwickler ihre Fähigkeiten zukunftssicher und schaffen mit fortschrittlichen LLM-Anwendungen echten Mehrwert.



 BONUS: Holen Sie sich unsere 200 $“AI „Mastery Toolkit“ KOSTENLOS bei der Anmeldung!
BONUS: Holen Sie sich unsere 200 $“AI „Mastery Toolkit“ KOSTENLOS bei der Anmeldung!






