
De fleste mennesker lander på Knusende ansigt, stirre på en væg af modelnavne, og klikke væk inden for 30 sekunder. Stor fejltagelse.
Mens alle diskuterer hvilken AI Værktøjet er værd at betale for, titusindvis af bygherrer bruger stille og roligt Hugging Face til at køre, finjustere og skib AI-drevne apps — helt gratis. Det's ikke bare et modelbibliotek. Det's platformen hvor Google, Meta, Mistral og soloudviklere alle arbejder i det samme rum.
Over 1 million modeller, over 500 datasæt og gratis app-hosting — under én konto. Her's den fulde oversigt over, hvad det er, og hvordan man rent faktisk bruger det.
Hvad et krammeansigt egentlig er (de fleste mennesker tager fejl)
Den "GitHub for maskinlæring""-mærkatet bliver ofte brugt. Det holder én vej – offentlige repos, versionskontrol, bidrag fra fællesskabet. Men det falder hurtigt fra hinanden. Hugging Face kører også live-inferens, hoster AI-drevne apps og leverer fuld træningsinfrastruktur. GitHub gør intet af det.
Virksomheden startede som en NLP chatbot-startup, der blev omstillet til open source AI værktøj, og har aldrig set sig tilbage. Den offentlige platform is ffri og fællesskabsdrevet; Enterprise-produkterne er måden, de tjener penge på. For begyndere dækker gratisniveauet alt, hvad du behøver. Modellerne offentliggøres her. før de skaber overskrifter – hvis der dukker noget nyt op inden for AI, dukker det først op på Hugging Face.
De tre søjler – kend disse før noget andet
Alt på Hugging Face er placeret i tre kerneafsnit:
| Søjle | Hvad er det | Hvorfor det drejer sig om |
|---|---|---|
| Modeller | 1 mio.+ prætrænet AI modeller | Spring træningen helt over fra bunden |
| datasæt | Rådata til træning og testning | Standardiserede, klar-til-indlæsning data |
| Spaces | Gratis hosting AI apps | Testmodeller uden at røre implementeringskoden |
Bliv fortrolig med alle tre – de forbinder sig konstant, mens du bygger.
Model Hub — Hvor du vil bruge det meste af din tid
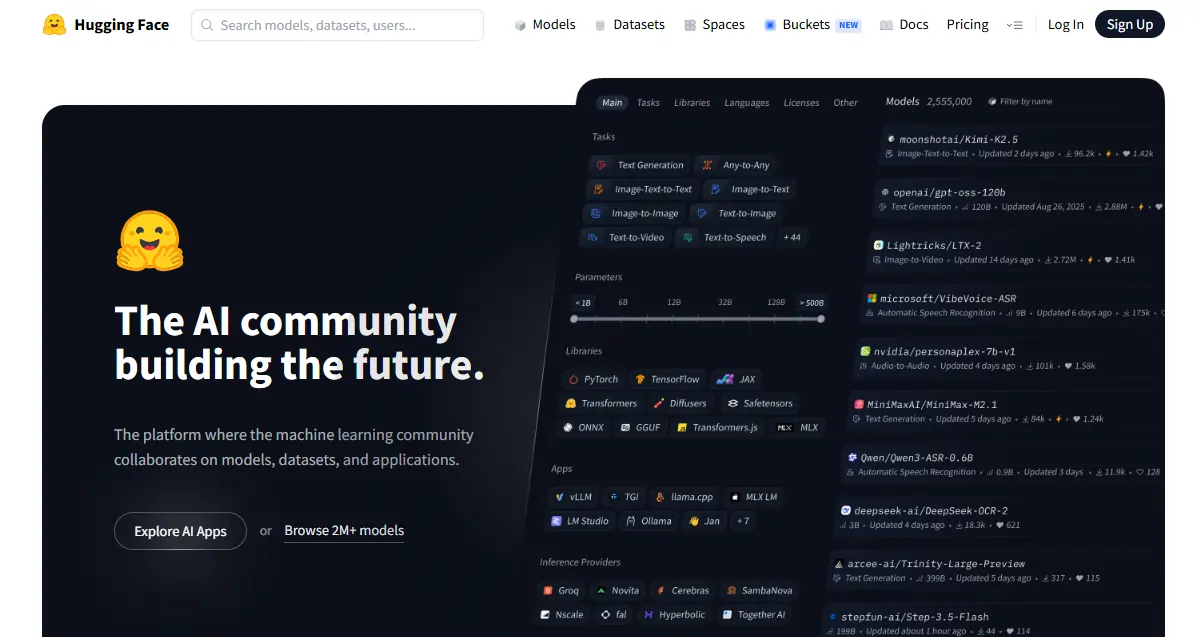
Filterpanelet er din bedste ven her: opgavetype, framework (PyTorch, TensorFlow, JAX), sprog, licens og modelstørrelse. Sortér efter mest downloadet for kamptestede valg; sorter efter For nylig opdateret når du har brug for friske muligheder.
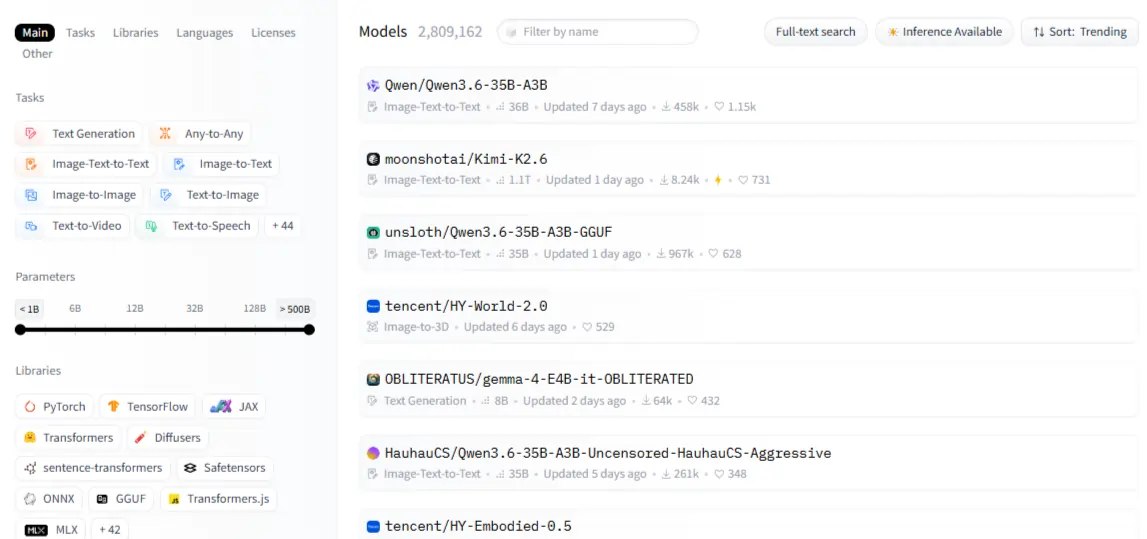
Hver model har et kort – læs det. Afsnittet om tilsigtet brug fortæller dig, hvad modellen blev bygget til; afsnittet om begrænsninger fortæller dig, hvor den går i stykker. Den anden del er mere værdifuld end nogen benchmark-score. Modelkategorier spænder over NLP (tekstklassificering, opsummering, oversættelse, besvarelse af spørgsmål), vision (billedklassificering, objektdetektion, generering), lyd (ASR, TTS) og multimodale opgaver som visuel besvarelse af spørgsmål.
Én ting begyndere overser: ikke alle modeller kan downloades gratis. Gated-modeller som f.eks. Meta's Llama kræver godkendelse før adgang. Når det er godkendt, autentificerer du dig med en adgangstoken. Tjek altid licensen, før du bygger – nogle modeller forbyder kommerciel brug helt.
Transformers-biblioteket — Koden kører halvdelen af AI Over
transformers biblioteket er et forenet Python pakke der standardiserer, hvordan du indlæser og kører enhver model på hubben på tværs af PyTorch, TensorFlow og JAX med den samme API.

pipeline() function er der, hvor de fleste begyndere bør starte — den pakker tokenisering, modelindlæsning og efterbehandling ind i et enkelt kald. Følelsesanalyse, tekstgenerering, billedklassificering – alt følger præcis det samme mønster. I det øjeblik du har brug for finjusteret kontrol over output, kan du gå videre til at skrive brugerdefineret inferenskode. Indtil da håndterer pipelines alt.
Spring ikke tokenisering over. Rå tekst kan ikke føres direkte ind i en model. AutoTokenizer håndterer konverteringen og matcher altid automatisk den rigtige tokenizer med det rigtige checkpoint. Uoverensstemmende tokenizere forårsager de mest forvirrende fejl, som begyndere støder på – og de kan 100% undgås.
| Opgaver | Pipelinenavn | Eksempel model |
|---|---|---|
| Følelsesanalyse | text-classification | distilbert-base-uindkapslet |
| Tekstgenerering | text-generation | Mistral-7B |
| Resumé | summarization | facebook/bart-large-cnn |
| Talegenkendelse | automatic-speech-recognition | openai/hvisken-base |
| Billedklassificering | image-classification | google/vit-base-patch16 |
Datasæt og rum — de to funktioner, som ingen bruger nok
datasets Biblioteket indlæser data i Apache Arrow-format – hurtigt, hukommelsesbesparende og bygget til at håndtere datasæt, der ikke passer i RAM. load_dataset("name", split="train") er alt, hvad der skal til for at komme i gang. Før du forpligter dig til et datasæt til en træningskørsel, skal du bruge Data Studio i browseren for at forhåndsvise og filtrere det uden at skrive en eneste linje kode.
Spaces er hvor AI Demoer går gratis live. Din app får en delbar URL på få minutter uden DevOps-arbejde. Det gratis CPU-niveau håndterer lette demoer; betalte GPU-baserede Spaces håndterer tungere modeller.
Brug Gradio til hurtige modeldemoer med minimal kode; brug Strømbelyst når din app har brug for et mere data-tungt dashboardlayout. Kloning af et trending Space er den hurtigste måde at starte på – vælg et i din kategori, forgren det, og tilpas.
Opsætning af din konto på den rigtige måde
Gratisniveauet dækker modelbrowsing, CPU-pladser, hastighedsbegrænsede API-kald og fuld adgang til fællesskabet. Pro tilføjer prioriterede GPU-pladser, udvidet inferens og private repos. For de fleste begyndere er gratis nok.
Generer et adgangstoken under indstillinger → AdgangstokensLæsetokens fungerer til download; skrivetokens er nødvendige til at pushe modeller eller datasæt. Godkend i Python med huggingface_hub.login()Til din installation:

bash
pip install transformers datasets huggingface_hubTilføj accelerate, peftog trl hvis finjustering er på vej. Google Colab er det hurtigste miljø for absolutte begyndere – gratis GPU, intet at konfigurere lokalt.
Kør din første model, og gør den derefter til din egen
Til sentimentanalyse: ringe pipeline("text-classification"), send en streng, læs label og score tilbage. Til tekstgenerering: brug max_new_tokens, temperatureog do_sample at kontrollere, hvor kreativt kontra ensartet outputtet er. Det samme pipeline() Mønsteret fungerer til oversættelse, talegenkendelse og billedklassificering – API'en ændres ikke, kun opgavenavnet gør.
Når tingene går i stykker:
Når det grundlæggende er på plads, er finjustering det næste skridt. Forudtrænede modeller er generelle; finjusterede modeller er præcise. Finjustering giver anledning til bekymring, når du arbejder med domænespecifikke data, har brug for ensartet adfærd eller ønsker at reducere inferensomkostninger ved at køre en mindre specialiseret model.
PEFT fryser det meste af modellen og træner kun letvægtsadaptere — ingen GPU til $10 kræves. QLoRA tager det videre med kvantisering, hvilket gør finjustering af 7B-parametermodellen mulig på en enkelt forbruger-GPU.
Trainer API'en administrerer hele løkken – batching, evaluering, checkpointing – og pushing back til hubben tager én linje, når du er færdig.
Inferens uden din egen server
Den hostede Inference API giver dig et REST-slutpunkt til enhver offentlig model med det samme. Det gratis niveau er hastighedsbegrænset – fint til test, ikke til produktion. Til rigtige applikationer, Inferensendepunkter levere en dedikeret, privat API, der automatisk skalerer til nul, når den er inaktiv, hvilket holder omkostningerne håndterbare for variabel trafik.
Når databeskyttelse eller latenstid ikke er til forhandling, selvhosting med TGI (Tekstgenereringsinferens) or vLLM er den produktionsklare vej.
Fællesskabet, ranglisterne og hvorfor det slår alt andet
Åbn LLM Leaderboard rangerer modeller efter benchmark — nyttigt til shortlisting, men valider altid på din faktiske use case, før du stoler på scorer. Organisationskonti giver teams mulighed for at administrere delte modelsamlinger med kontrolleret adgang; Meta AI, Google og EleutherAI alle kører organisationskonti direkte på hubben.
Ved at følge forskere og organisationer får du et realtidsfeed af nye modeludgivelser uden at skulle overvåge sociale medier.
| perron | Open Source | Model Variety | Gratis niveau | Finjusteringsværktøjer |
|---|---|---|---|---|
| Knusende ansigt | ✅ Fuld | ✅ 1 mio.+ | ✅ Generøs | ✅ Fuld stak |
| TensorFlow Hub | ✅ Ja | 🔶 Begrænset | ✅ Ja | ❌ Grundlæggende |
| Google Modelhave | ❌ Delvis | 🔶 Kurateret | 🔶 Kun GCP | 🔶 Kun GCP |
| ÅbneAI API | ❌ Nej | ❌ Lukket | ❌ Kun betalt | 🔶 Begrænset |
Fejl der vil koste dig timer
- At tage den største model, når en mindre, opgavespecifik model kører hurtigere og billigere
- Springer modelkortet over's afsnittet om begrænsninger, før du bygger noget ovenpå det
- Fastlåser ikke modelrevisioner — modeller opdateres lydløst, og output ændres uden varsel
- Brug af den gratis Inference API til alt, der kræver ensartet produktionsoppetid
- Overførsel af rå tekst direkte til en model uden først at køre den gennem en tokenizer
AiMojo anbefaler:
Hvor skal man hen herfra
Knusende ansigt's gratis kurser at hf.co/learn Dæk NLP, lyd og dybdegående forstærkningslæring i strukturerede stier, der er bygget specifikt til denne platform. Det bedste første projekt: finjuster en tekstklassifikator på et brugerdefineret datasæt, pak det ind i Gradio og implementer det som et Space.
Den enkelte build berører modeller, datasæt, finjustering og Spaces i én omgang. Når den først er's live, upload modellen og skriv et korrekt modelkort — der dækker den tilsigtede anvendelse, træningsdata og begrænsninger.
Det's hvordan nyttige offentlige bidrag ydes, og det's hvordan du begynder at opbygge en reel tilstedeværelse i open source AI plads.



 BONUS: Få vores 200 dollarsAI "Mestringsværktøjskasse" GRATIS ved tilmelding!
BONUS: Få vores 200 dollarsAI "Mestringsværktøjskasse" GRATIS ved tilmelding!






