
Hurtige justeringer alene er ikke længere nok for virksomheder AI systemer. Efterhånden som modelkontekstvinduer vokser over 200 tokens, pakker ingeniører nu LLM'en ind i dokumenter, hentningspipelines, noter og værktøjskald – en tilgang, der er mærket kontekstteknik.
Skiftet skete hurtigt.
Kontekstudvikling bygger bro over dette hul ved at behandle hele AI miljø som et system i stedet for at fokusere på individuelle input.
Kontekstteknik:
Systemet der rent faktisk virker
Kontekstudvikling behandler hele pipelinen før LLM-kaldet som konstruerbar infrastruktur. Tænk på en LLM's kontekstvindue som RAM – det har begrænset arbejdshukommelse, der bestemmer, hvad modellen kan behandle.
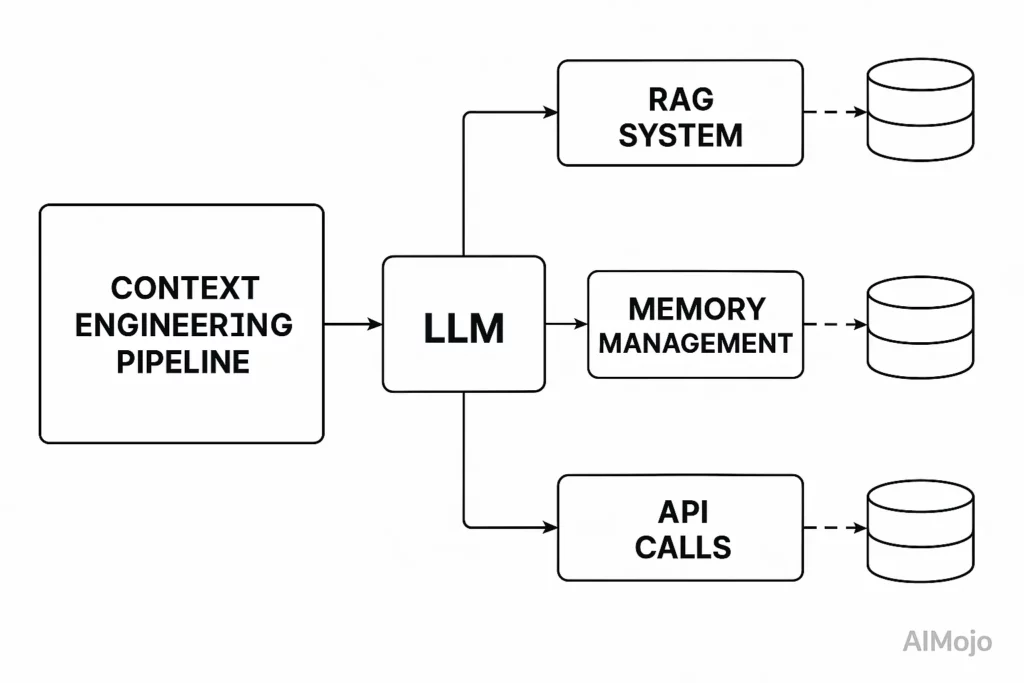
Ligesom et operativsystem omhyggeligt styrer, hvad der lægges i RAM, kuraterer kontekstteknik, hvilke oplysninger der fylder LLM'en.'s kontekstvindue.
Her's hvad kontekstudvikling egentlig omfatter:
Kontekstteknik vs. promptteknik:
Tallene lyver ikke
| Aspect | Hurtig teknik | Kontekstteknik |
|---|---|---|
| Fokus | Oprettelse af én inputstreng | Orkestrering af hvert signal omkring modellen |
| Gennemsnitlig udviklingstid | 70% hurtige justeringer | 60% datapipelines, 20% hukommelsesregler, 20% prompts |
| Typisk fejltilstand | Pludseligt fald i outputkvaliteten efter datadrift | Robust via RAG, hukommelse, værktøjskald |
Hurtigt eksempel: A kundesupport-bot Trænet med prompts alene kan huske refusionspolitikken, når de bliver spurgt direkte. Når brugeren refererer til "ordre 45791", fejler det. Tilføj kontekstteknik - samtalehistorik plus en RAG-forespørgsel i ordredatabasen - og botten trækker øjeblikkeligt købsoplysninger og anbefaler den korrekte refusionsproces.
De fire søjler inden for kontekstudvikling, der rent faktisk betyder noget
1. Skrivekontekst (Din AI's Notesystem)
At skrive kontekst betyder at gemme information uden for kontekstvindue til fremtidig brug. Dette bevarer værdifuld tokenplads, samtidig med at adgangen til vigtige data opretholdes.
Kladdeblokke arbejde som notetagning for agenter i en enkelt session. Antropisk's multiagentforsker gemmer sin oprindelige plan til "Hukommelse"fordi hvis konteksten overstiger 200,000 tokens, bliver den afkortet, og planen går tabt.

Langtidshukommelser gemme oplysninger på tværs af flere sessioner. Eksempler inkluderer ChatGPT, der automatisk genererer brugerpræferencer fra samtaler, og markør-/windsurf-læring kodningsmønstre og projektkontekst.

2. Kontekstvalg (Kunsten at vælge det, der betyder noget)
Kontekstvalg bringer kun de oplysninger, der er relevante for den aktuelle opgave, ind.
når en AI fitness træner genererer en træningsplan, skal den vælge kontekstdetaljer, der inkluderer brugeren's højde, vægt og aktivitetsniveau, mens irrelevante oplysninger ignoreres.
Den vigtigste indsigtMere information er ikke altid bedre. Effektiv kontekstudvikling betyder at vælge den rigtige kombination til hver specifik opgave.
3. Kontekstkomprimering (indpasning af mere i mindre)
Når samtaler bliver så lange, at de overstiger LLM's hukommelse vindue, bliver kontekstkomprimering kritisk. Agenter opnår typisk dette ved at opsummere tidligere dele af samtalen.

4. Kontekstisolering (Del og hersk)
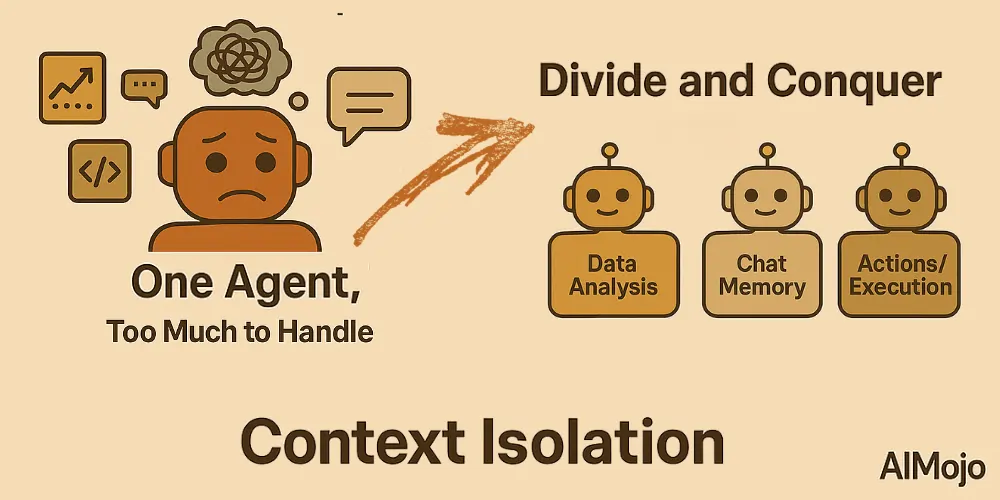
Kontekstisolering betyder at opdele information i separate dele, så agenter bedre kan håndtere komplekse opgaver. I stedet for at proppe al viden ind i én massiv prompt, opdeler udviklere kontekst på tværs af specialiserede underagenter eller miljøer med sandkasse.
Kontekstudvikling i den virkelige verden i aktion
Kundeservicerevolutionen
| Før kontekstudvikling | Efter kontekstudvikling |
|---|---|
| Generiske chatbots, der glemmer tidligere samtaler og giver irrelevante svar. | AI agenter, der husker din købshistorik, får adgang til lagerdata i realtid og koordinerer med menneskelige agenter, når det er nødvendigt. |
Kodningsassistenten, der aldrig glemmer
SystemetNår du spørger "Hvordan retter jeg denne godkendelsesfejl?", gør kontekstudviklingssystemet automatisk følgende:

I stedet for generisk kodningsrådgivning får du specifikke løsninger, der er skræddersyet til din faktiske kodebase.
Den tekniske arkitektur, der driver kontekstudvikling
Dynamisk kontekstsamling
Kontekst opbygges undervejs og udvikler sig i takt med at samtaler skrider frem. Dette omfatter:
- Hentning af relevante dokumenter
- Vedligeholdelse af hukommelsen
- Opdaterer brugerstatus
- API-kald og databaseforespørgsler
Kontekstvinduehåndtering
Med fast størrelse symbolske grænser (32K, 100K, 1M), skal ingeniører komprimere og prioritere information intelligent ved hjælp af:
- Scoringsfunktioner (TF-IDF, indlejringer, opmærksomhedsheuristikker)
- Opsummering og fremtrædende udtrækning
- Chunking-strategier og overlapningsjustering

Sikkerhed og konsistens
Anvend principper som hurtig injektionsdetektion, kontekstrensning, PII-redaktionog rollebaseret kontekstadgangskontrol.
Byg dit første konteksttekniske system
At opbygge en kontekstudviklingsworkflow er ikke bare teori – det's en gentagelig proces, der kan operationaliseres og endda automatiseres. Sådan kan du omsætte den til praksis:
Trin 1: Kortlæg dine kontekstkilder
Identificér, hvor din agent skal hente oplysninger fra (dokumenter, databaser, API'er, tidligere chats osv.).
python
# Example: Fetching relevant documents using embeddings
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer("all-MiniLM-L6-v2")
query = "project status update"
corpus = ["spec doc", "requirements", "last week's meeting notes"]
query_embedding = model.encode(query, convert_to_tensor=True)
corpus_embeddings = model.encode(corpus, convert_to_tensor=True)
hits = util.semantic_search(query_embedding, corpus_embeddings, top_k=2)[0]
relevant_docs = [corpus[hit['corpus_id']] for hit in hits]
Trin 2: Implementer hukommelse og skrivekontekst
Gem vigtige oplysninger, så de altid er der til fremtidige opgaver.
python
import json
def save_to_memory(memory_path, user_id, data):
with open(memory_path, "r+") as file:
memory = json.load(file)
memory[user_id] = data
file.seek(0)
json.dump(memory, file)
file.truncate()Trin 3: Byg kontekstvalg og komprimeringslogik
Udvikl regler eller modeller, der kun udvælger det, der er mest relevant for opgaven. Komprimer lange historikker til opsummerede former.
python
def summarize_conversation(history):
# Placeholder for use with an LLM summarizer or custom rules
return history[-5:] # Only the last 5 messagesTrin 4: Isoler kontekster for agentkoordinering
Opdel information, så hver agent eller komponent kun håndterer det, den skal.
python
user_profile_ctx = {"user_goals": "..."}
task_specific_ctx = {"current_task": "..."}
external_data_ctx = {"live_data": "..."}
full_context = {**user_profile_ctx, **task_specific_ctx, **external_data_ctx}Trin 5: Outputstrukturering og API-parathed
Formatér outputkonteksten ensartet, så den's forudsigelige for downstream LLM-kald eller API-slutpunkter.
python
schema = {
"user": {"age": 35, "goal": "muscle gain"},
"plan": "high protein, 3x/week weight training"
}Trin 6: Overvåg, iterér og sikr
Spor fejl, revider kontekstkvaliteten, og forbedr logikken for kontekstinkludering, hukommelse og hentning. Rengør altid input for at undgå hurtig indsprøjtning og datalækager.
Hvorfor kontekstudvikling betaler sig mere end promptudvikling
Virksomheder har brug for ingeniører, der kan bygge systemer, der giver den rette kontekst til AI, holder information nøjagtig og opdateret og beskytter brugerne ved at tilføje sikkerhedsretningslinjer.
Markedets virkelighedKontekstudvikling kræver tværfaglige færdigheder, der involverer forståelse af forretningsmæssige anvendelsesscenarier, definition af output og strukturering af information, så LLM'er kan udføre komplekse opgaver.
Bundlinie: Alle kan skrive prompts. Skal man bygge kontekstbevidste agenter, der husker, tilpasser og vælger kontekst i stor skala? Sådan fremtidssikrer udviklere deres færdigheder og leverer reel værdi med avancerede LLM-applikationer.



 BONUS: Få vores 200 dollarsAI "Mestringsværktøjskasse" GRATIS ved tilmelding!
BONUS: Få vores 200 dollarsAI "Mestringsværktøjskasse" GRATIS ved tilmelding!

![7 bedste gratis AI Menneskelige generatorer i 2026 [Anmeldt og rangeret]](https://aimojo.io/wp-content/uploads/2023/11/Best-Free-AI-Human-Generator-100x100.webp)




