Crawl4AI Klíčové poznatky
Co je Crawl4AI?
Crawl4AI je bezplatná knihovna Pythonu s otevřeným zdrojovým kódem, která převádí webové stránky do čistého Markdownu, strukturovaného JSON nebo filtrovaného HTML, které mohou rozsáhlé jazykové modely přímo využívat. Je postavena na platformě Playwright pro automatizaci prohlížečů a slouží vývojářům při vytváření RAG pipeline, AI agenty a automatizované pracovní postupy pro data. Nástroj podporuje strategie extrakce založené na LLM i bez něj, což týmům poskytuje plnou kontrolu nad náklady a kvalitou výstupu.
S více než 60 000 hvězdičkami na GitHubu a více než 900 000 měsíčními staženími PyPI, Crawl4AI se stal jedním z nejoblíbenějších nástrojů pro webový scraping na světě. AI inženýrské komunity. Běží výhradně na vaší vlastní infrastruktuře, takže nejsou potřeba žádné API klíče ani poplatky za stránku. Pro týmy, které potřebují extrakci dat v produkčním měřítku pro obchodní automatizace, Crawl4AI nabízí flexibilitu připojení k libovolnému poskytovateli LLM a zároveň ponechává vrstvu procházení zcela zdarma.
Crawl4AI Vytváří dva typy výstupu Markdownu, jak je popsáno na oficiálních stránkách. Clean Markdown zachovává přesné formátování stránky s nadpisy, tabulkami, bloky kódu a citačními radami. Fit Markdown používá heuristické filtrování pomocí algoritmu prořezávání nebo skórování relevance BM25 k odstranění šumu z standardního textu, navigace a zápatí.
Tento duální výstup je speciálně navržen pro RAG pipeline a přímé ingestování LLM. Uživatelé si také mohou vytvářet vlastní Generování srážek strategie, které přesně odpovídají požadavkům jejich potrubí.
Nástroj nabízí dvě odlišné cesty extrakce. Pro stránky s předvídatelným rozvržením stahuje JsonCssExtractionStrategy založený na CSS a XPath strukturovaný JSON pomocí definic schématu a nevyžaduje žádná volání LLM.
Pro složité nebo nepředvídatelné stránky se LLMExtractionStrategy připojuje k libovolnému poskytovateli LLM (OpenAI, Ollama, DeepSeek a další) a používá schémata Pydantic k vrácení dokonale strukturovaných dat. Strategie dělení na bloky, včetně zpracování na základě témat, regulárních výrazů a na úrovni vět, efektivně zpracovávají velké stránky.
Adaptivní procházení, oznámené na crawl4ai.com jako vlajková loď, využívá algoritmy pro vyhledávání informací s třívrstvým systémem hodnocení, který měří pokrytí, konzistenci a saturaci. Místo procházení každé stránky na webu vyhodnocuje obsahová relevance v každém kroku a automaticky se zastaví, když jsou dosaženy prahové hodnoty spolehlivosti.
Podporuje jak statistickou strategii (rychlou, bezplatnou, založenou na termínech), tak strategii vkládání (sémantické porozumění s rozšířením dotazů). To zabraňuje nadměrnému procházení a šetří značné výpočetní prostředky.
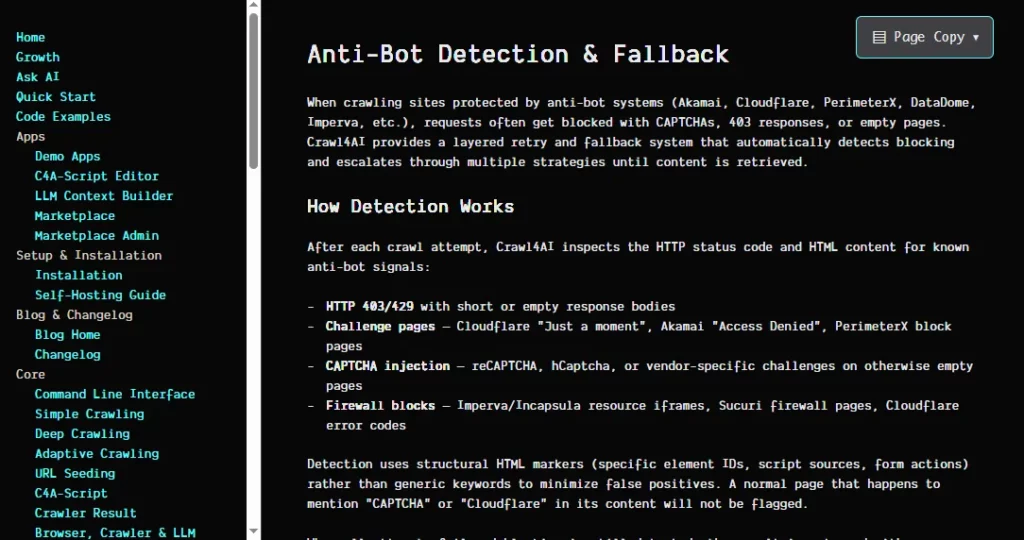
Třívrstvá verze, představená ve verzi 0.8.5 systém detekce botů Kontroluje známé podpisy dodavatelů, generické indikátory bloků a strukturální integritu vrácených stránek. Když je detekován blok, systém se automaticky pokusí o opakování prostřednictvím konfigurovatelného proxy řetězce s funkcemi záložního načítání. V kombinaci s nenápadným režimem, který napodobuje chování skutečného uživatele, a nedetekovaným režimem prohlížeče z verze 0.7.3 to dává Crawl4AI silná sada nástrojů pro přístup k chráněným webům.
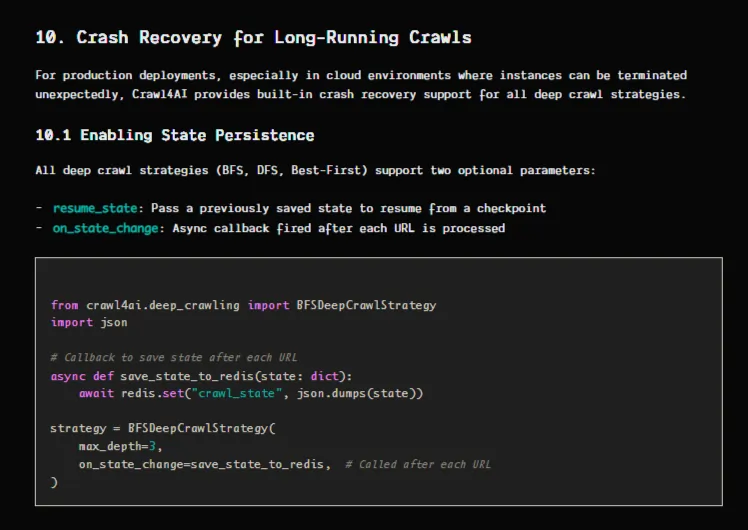
Pro rozsáhlé úlohy, které zahrnují tisíce stránek, zahrnují strategie hloubkového procházení (BFS, DFS, Best First) vestavěnou obnovu po havárii, jak je vydáno ve verzi 0.8.0. Zpětné volání on_state_change přetrvává stav po každé URL adrese a parametr resume_state umožňuje pokračovat od přesného kontrolního bodu po selhání.
Režim předběžného načítání zcela přeskakuje generování a extrakci Markdownu, což umožňuje vyhledávání URL 5 až 10krát rychlejší než obvykle pro dvoufázové pracovní postupy procházení.
Crawl4AI Dodává se s optimalizovaným obrazem Dockeru, který obsahuje server FastAPI, ověřování pomocí tokenů JWT, monitorovací panel v reálném čase s aktuálními systémovými metrikami a tříúrovňový pool prohlížečů (permanentní, aktivní, studený) s předběžným zahříváním stránek. Interaktivní hřiště umožňuje týmům testovat konfigurace procházení a generovat kód požadavků bez nutnosti psaní skriptů.
Integrace MCP se přímo připojuje k AI nástroje jako Claude Code. Podpora více architektur s automatickou detekcí AMD64 a ARM64 zajišťuje, že běží na jakémkoli cloudovém poskytovateli.
Crawl4AI Cenové plány
| Plán Název | Stát | Klíčové Podrobnosti |
|---|---|---|
| Open Source (vlastní hosting) | $0 | Neomezené procházení, plná sada funkcí, infrastrukturu poskytujete vy |
| Cloudové API (uzavřená beta verze) | Zvyk | Spravovaná služba, požádejte o předběžný přístup, omezený počet slotů |
| Sponzor věřícího | $ 5 / mo | Úroveň podpory komunity, podpora projektu |
| Sponzor stavitele | $ 50 / mo | Prioritní podpora a včasný přístup k novým funkcím |
| Sponzor rostoucího týmu | $ 500 / mo | Synchronizace každé dva týdny a pokyny k optimalizaci |
| Partner pro datovou infrastrukturu | $ 2,000 / mo | Vyhrazená podpora a plné partnerství |
Jak Crawl4AI Zvládá generování Markdownu?
Crawl4AI Vytváří dva typy výstupu Markdownu. Raw Markdown zachovává celou strukturu stránky včetně navigačních prvků a zápatí. Fit Markdown aplikuje heuristické filtrování pomocí algoritmu prořezávání nebo skórování relevance BM25 k odstranění šumu a zachování pouze základního obsahu. To je obzvláště cenné pro RAG pipelines, kde kvalita vkládání závisí na čistém vstupním textu.
Můžete také implementovat vlastní strategie generování Markdownu rozšířením základní třídy, což vám poskytne plnou kontrolu nad tím, jak se prvky HTML mapují na tokeny Markdownu. Citační systém převádí odkazy na stránky na číslované reference, což pomáhá LLM sledovat atribuci zdroje během úloh vyhledávání.
Výhody a nevýhody
- Aktivní komunita s více než 60 000 hvězdami.
- Permisivní licence Apache 2.0.
- Funguje s jakýmkoli poskytovatelem LLM.
- Asynchronní architektura pro rychlost.
- Vestavěné hloubkové procházení po havárii.
- Zatím žádná spravovaná cloudová služba.
- Žádné grafické uživatelské rozhraní ani vizuální rozhraní.
- Ovládání antibotů vyžaduje nastavení proxy.
Nejlepší procházení4AI Alternativy
| AI Webový crawler a scraper | Možnost vlastního hostování | LLM Volná extrakce |
|---|---|---|
| Ohnivé plazení | Omezeno (platí omezení AGPL 3.0) | Ne, pro strukturovaný JSON je vyžadováno LLM |
| Apify | Ne, platforma plně závislá na cloudu | Ne, spoléhá na AI modely pro parsování |
| ScrapeGraphAI | Ano, open source knihovna Pythonu (MIT) | Ne, každá extrakce vyžaduje volání LLM. |

