
Většina lidí přistane na Objímání obličeje, zírat na zeď plnou názvů modelů a do 30 sekund kliknout pryč. Velká chyba.
Zatímco se všichni hádají o tom, který AI Za nástroj se vyplatí zaplatit, desítky tisíc stavitelů tiše používají Hugging Face k jeho spouštění, doladění a loď AAplikace s technologií I — zcela zdarma. To's Není to jen knihovna modelů. Je to's platforma, kde Google, Meta, Mistral a sóloví vývojáři pracují ve stejném prostoru.
Přes 1 milion modelů, více než 500 tisíc datových sad a bezplatný hosting aplikací — pod jedním účtem. Zde's kompletní rozbor toho, co to je a jak to vlastně používat.
Co je to vlastně objímající obličej (většina lidí se v tom mýlí)
"GitHub strojového učeníOznačení „“ se často používá. Drží se jednoho směru – veřejná repozitáře, správa verzí, příspěvky komunity. Ale rychle se rozpadá. Hugging Face také provozuje živou inferenci, hostuje aplikace poháněné umělou inteligencí a poskytuje kompletní školicí infrastrukturu. GitHub nic z toho nedělá.
Samotná společnost začínala jako startup zabývající se NLP chatboty, který se později přeorientoval na open-source. AI nástroje a nikdy se neohlédl zpět. Veřejná platforma is fsvobodný a komunitně řízený; podnikové produkty jsou způsob, jakým vydělávají peníze. Pro začátečníky je k dispozici bezplatná úroveň, která pokrývá vše, co potřebujete. Modely se zveřejňují zde. před Dostávají se na titulní stránky novin – pokud se v oblasti umělé inteligence objeví něco nového, objeví se to jako první na Hugging Face.
Tři pilíře – znát je musíte nejdříve
Všechno na Hugging Face je zasazeno do tří hlavních sekcí:
| Pilíř | Co to je | Proč to záleží |
|---|---|---|
| modely | 1 milion+ předem proškolených AI modely | Úplně vynechejte trénink od nuly |
| Datasety | Nezpracovaná data pro školení a testování | Standardizovaná data připravená k načtení |
| Prostory | Hostováno zdarma AI aplikace | Testovací modely bez zásahu do kódu nasazení |
Zkuste si zvyknout na všechny tři – při stavbě se neustále propojují.
Centrum modelů – místo, kde strávíte většinu času
Panel filtrů je zde vaším nejlepším přítelem: typ úlohy, framework (PyTorch, TensorFlow, JAX), jazyk, licence a velikost modelu. Řadit podle nejstahovanější pro tipy ověřené v boji; seřadit podle nedávno aktualizován když potřebujete čerstvé možnosti.
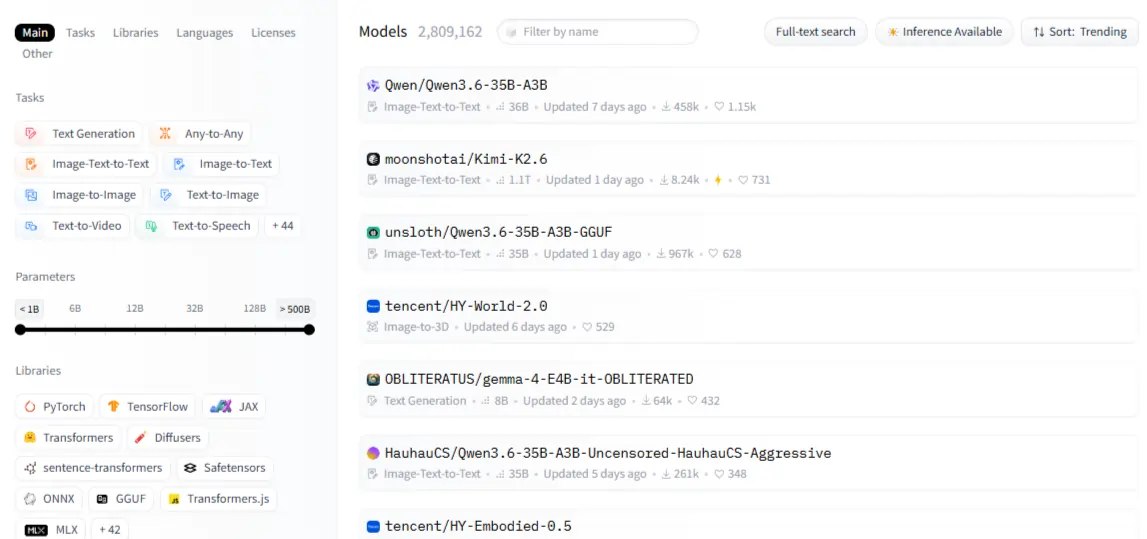
Každý model má kartu – přečtěte si ji. Sekce o zamýšleném použití vám říká, k čemu byl model vyroben; sekce omezení říká vám, kde se něco pokazí. Tato druhá část je cennější než jakékoli benchmarkové skóre. Kategorie modelů zahrnují NLP (klasifikace textu, sumarizace, překlad, odpovídání na otázky), zrak (klasifikace obrázků, detekce objektů, generování), zvuk (ASR, TTS) a multimodální úkoly jako vizuální odpovídání na otázky.
Jedna věc, kterou začátečníci přehlížejí: ne všechny modely jsou volně ke stažení. Modely s ochranou, jako například meta's Lama vyžadují schválení před přístupem. Po schválení se ověříte pomocí přístupového tokenu. Před sestavením si vždy zkontrolujte licenci – některé modely komerční použití zcela zakazují.
Knihovna Transformersů — Kód běžící polovinou AI Celým Světem
Jedno transformers knihovna je sjednocené PYTHON balíček který standardizuje způsob načítání a spouštění jakéhokoli modelu na hubu v PyTorch, TensorFlow a JAX se stejným API.

Jedno pipeline() Funkce je místem, kde by měla většina začátečníků začít – zabaluje tokenizaci, načítání modelu a následné zpracování do jednoho volání. Analýza sentimentu, generování textu, klasifikace obrázků – to vše se řídí přesně stejným vzorem. V okamžiku, kdy potřebujete detailní kontrolu nad výstupy, přejděte k psaní vlastního inferenčního kódu. Do té doby se o vše postarají pipeliney.
Nevynechávejte tokenizaci. Nezpracovaný text nelze vložit přímo do modelu. AutoTokenizer zpracovává konverzi a vždy automaticky přiřazuje správný tokenizátor ke správnému kontrolnímu bodu. Neshodující se tokenizátory způsobují ty nejmatoucí chyby, na které se začátečníci mohou setkat – a těmto chybám se lze na 100 % vyhnout.
| Úkol | Název potrubí | Příklad modelu |
|---|---|---|
| Analýza sentimentu | text-classification | Distilbert-base-uncased |
| Generování textu | text-generation | Mistral-7B |
| Shrnutí | summarization | facebook/bart-large-cnn |
| Rozpoznávání řeči | automatic-speech-recognition | openai/whisper-base |
| Klasifikace obrazu | image-classification | google/vit-base-patch16 |
Datové sady a prostory – dvě funkce, které nikdo dostatečně nepoužívá
Jedno datasets Knihovna načítá data ve formátu Apache Arrow – rychlé, paměťově efektivní a navržené pro práci s datovými sadami, které se nevejdou do RAM. load_dataset("name", split="train") je vše, co potřebujete k zahájení. Než se zavážete k jakékoli datové sadě pro trénovací běh, použijte Data Studio v prohlížeči pro zobrazení náhledu a filtrování bez nutnosti napsat jediný řádek kódu.
Prostory jsou místem, kde AI Dema jsou spuštěna zdarma. Vaše aplikace získá sdílenou URL adresu během několika minut bez nutnosti DevOps. Bezplatná úroveň CPU zvládá lehká dema; placené Spaces s grafickou kartou zvládají náročnější modely.
Použijte Gradio pro rychlé ukázky modelů s minimálním kódem; použijte Streamlit když vaše aplikace potřebuje rozvržení dashboardu s větším objemem dat. Klonování trendového prostoru je nejrychlejší způsob, jak začít – vyberte si jeden ve své kategorii, rozdělte ho na fork a upravte.
Správné nastavení účtu
Bezplatná verze zahrnuje prohlížení modelů, prostory CPU, volání API s omezenou rychlostí a plný přístup komunity. Verze Pro přidává prioritní prostory GPU, rozšířenou inferenci a soukromé repozitáře. Pro většinu začátečníků stačí i bezplatná verze.
Vygenerujte přístupový token v rámci nastavení → Přístupové tokenyTokeny pro čtení fungují pro stahování; tokeny pro zápis jsou potřeba pro odesílání modelů nebo datových sad. Autentifikace v Pythonu pomocí huggingface_hub.login()Pro vaši instalaci:

praštit
pip install transformers datasets huggingface_hubpřidat accelerate, peft, a trl pokud je v plánu doladění. Google Colab je nejrychlejší prostředí pro úplné začátečníky – zdarma GPU, není třeba nic lokálně konfigurovat.
Spuštění prvního modelu a jeho následné přizpůsobení
Pro analýzu sentimentu: volání pipeline("text-classification"), předat řetězec, přečíst label a score zpět. Pro generování textu: použijte max_new_tokens, temperature, a do_sample pro kontrolu kreativity a konzistence výstupu. Stejné pipeline() Vzor funguje pro překlad, rozpoznávání řeči a klasifikaci obrázků – API se nemění, mění se pouze název úlohy.
Když se věci rozbijí:
Jakmile si základy ujasníte, dalším krokem je doladění. Předtrénované modely jsou obecné, doladěné modely jsou přesné. Doladění překonává výzvy, když pracujete s daty specifickými pro danou doménu, potřebujete konzistentní chování nebo chcete snížit náklady na inferenci spuštěním menšího specializovaného modelu.
PEFT zmrazí většinu modelu a trénuje pouze lehké adaptéry – není potřeba žádná grafická karta za 10 000 dolarů. QLoRA jde ještě dál s kvantizací, která umožňuje jemné doladění modelu 7B parametrů na jediné spotřebitelské GPU.
Jedno Trainer API spravuje celou smyčku – dávkování, vyhodnocování, kontrolní body – a odeslání zpět do centra zabere po dokončení jeden řádek.
Inference bez vlastního serveru
Hostované Inference API vám okamžitě poskytne REST endpoint pro jakýkoli veřejný model. Bezplatná verze je omezená rychlostí – je vhodná pro testování, nikoli pro produkční prostředí. Pro reálné aplikace... Koncové body odvození poskytují specializované, soukromé API, které se při nečinnosti automaticky škáluje na nulu, čímž udržují náklady na zvládnutí proměnlivé návštěvnosti.
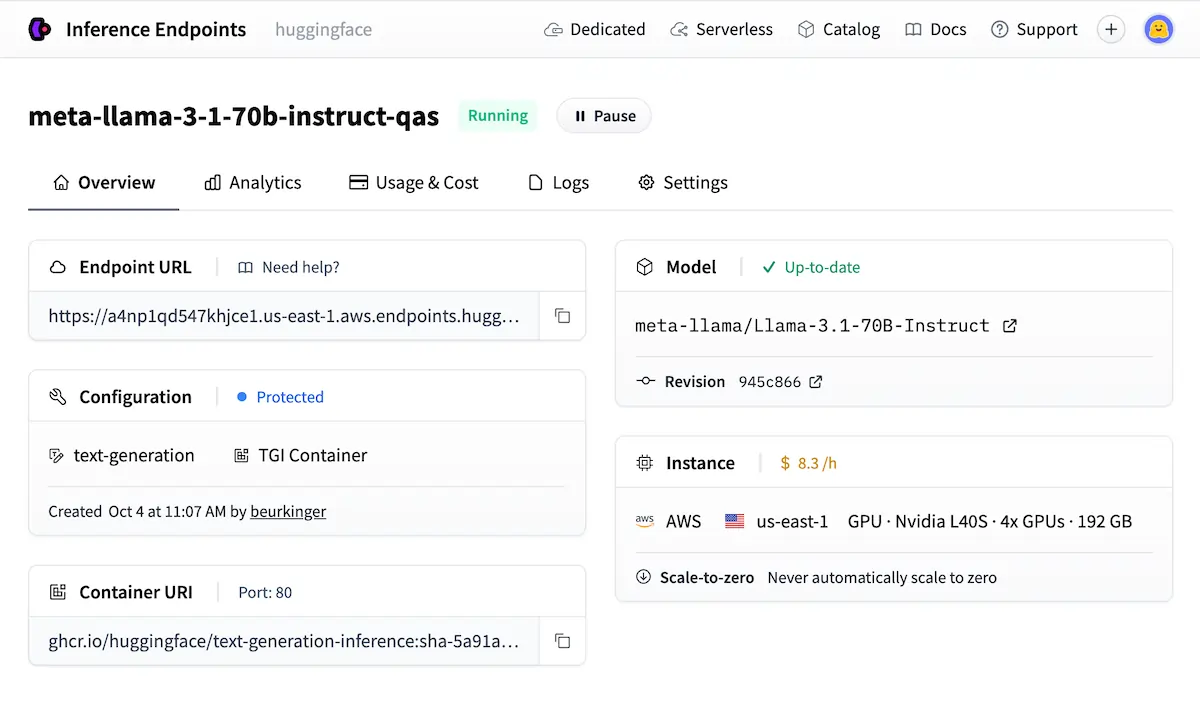
Pokud je ochrana soukromí dat nebo latence nepodstatná, je vhodné využít vlastní hosting s TGI (Inference generování textu) or vLLM je cesta připravená k produkčnímu prostředí.
Komunita, žebříčky a proč poráží všechno ostatní
Jedno Otevřete žebříček LLM řadí modely podle benchmarku – užitečné pro výběr, ale vždy ověřte skutečný případ použití, než se spolehnete na skóre. Účty organizací umožňují týmům spravovat sdílené kolekce modelů s kontrolovaným přístupem; Meta AI, Google a EleutherAI všechny provozují organizační účty přímo v centru.
Sledování výzkumníků a organizací vám poskytne aktuální informace o nových modelech, aniž byste museli sledovat sociální média.
| Plošina | Open Source | Odrůda modelu | Úroveň zdarma | Nástroje pro jemné doladění |
|---|---|---|---|---|
| Objímání obličeje | ✅ Plná | ✅ 1 milion+ | ✅ Velkorysý | ✅ Plný zásobník |
| Rozbočovač TensorFlow | ✅ Ano | 🔶 Omezené | ✅ Ano | ❌ Základní |
| Modelová zahrada Google | ❌ Částečné | 🔶 Vybrané | 🔶 Pouze GCP | 🔶 Pouze GCP |
| OtevřenáAI API | ❌ Ne | ❌ Zavřeno | ❌ Pouze placené | 🔶 Omezené |
Chyby, které vás budou stát hodiny
- Pořízení největšího modelu, když menší, pro specifické účely běží rychleji a levněji
- Přeskočení karty modelu's sekce s omezeními, než na ni cokoli navážete
- Nepřipínání revizí modelu – modely se aktualizují tiše a výstupy se mění bez varování
- Použití bezplatného rozhraní Inference API pro cokoli, co vyžaduje konzistentní provozní dobu
- Předávání nezpracovaného textu přímo do modelu bez jeho předchozího spuštění tokenizátorem
AiMojo doporučuje:
Kam jít odtud
Objímání obličeje's kurzy zdarma at hf.co/learn Probírejte NLP, audio a hluboké posilovací učení ve strukturovaných cestách vytvořených speciálně pro tuto platformu. Nejlepší první projekt: doladit textový klasifikátor na vlastní datové sadě, zabalit ho do Gradia a nasadit jako prostor.
Toto jediné sestavení se dotkne modelů, datových sad, jemného doladění a prostorů najednou. Jakmile to bude's spustit živě, nahrát model a napsat správnou kartu modelu – zahrnující zamýšlené použití, trénovací data a omezení.
Že's jak vznikají užitečné veřejné příspěvky a jak's jak začít budovat skutečnou přítomnost v open-source AI prostor.



 BONUS: Získejte našich 200 dolarůAI „Sada nástrojů pro mistrovství“ ZDARMA při registraci!
BONUS: Získejte našich 200 dolarůAI „Sada nástrojů pro mistrovství“ ZDARMA při registraci!







