
Pouhé rychlé úpravy už pro podniky nestačí AI systémy. Vzhledem k tomu, že okna kontextu modelu narůstají přes 200 tisíc tokenů, inženýři nyní obalují LLM dokumenty, kanály pro vyhledávání, zápisníky a volání nástrojů – přístup označovaný jako kontextové inženýrství.
Změna proběhla rychle.
Kontextové inženýrství tuto mezeru překlenuje tím, že se zabývá celým AI životní prostředí jako systém, spíše než se zaměřovat na jednotlivé vstupy.
Kontextové inženýrství:
Systém, který skutečně funguje
Kontextové inženýrství zachází s celým procesem před voláním LLM jako s inženýrsky využitelnou infrastrukturou. Představte si LLM.'s kontextové okno jako RAM – má omezenou pracovní paměť, která určuje, co model dokáže zpracovat.
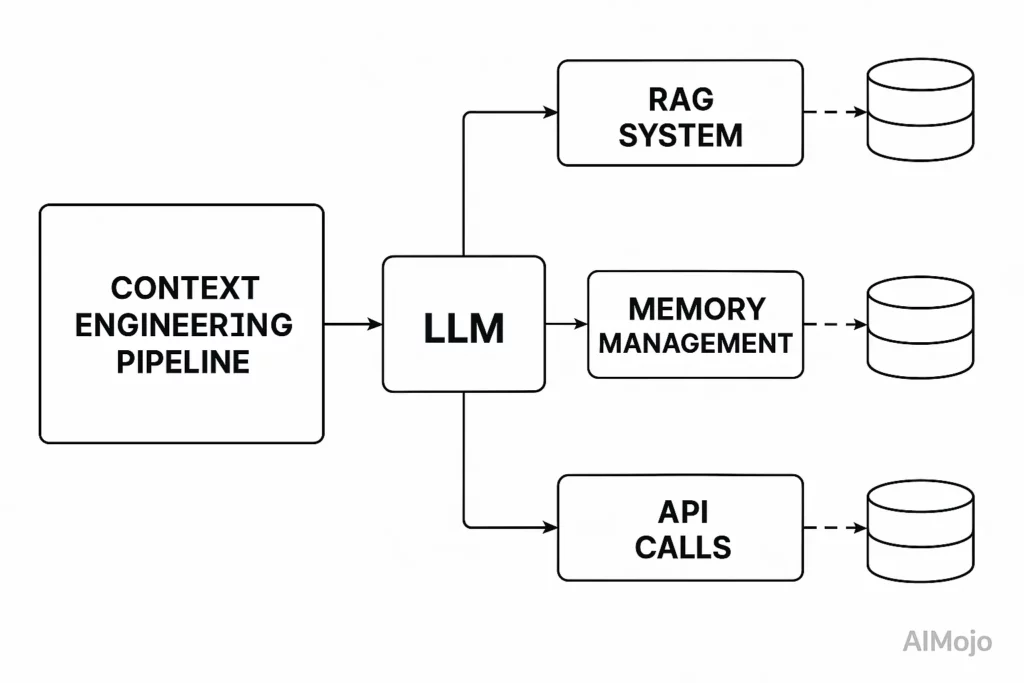
Stejně jako operační systém pečlivě spravuje, co se ukládá do paměti RAM, kontextové inženýrství kurátoruje, jaké informace zaplňují LLM.'s kontextové okno.
Zde's Co kontextové inženýrství vlastně zahrnuje:
Kontextové inženýrství vs. promptní inženýrství:
Čísla nelžou
| Vzhled | Prompt Engineering | Kontextové inženýrství |
|---|---|---|
| Soustředit | Vytvoření jednoho vstupního řetězce | Orchestrace každého signálu kolem modelu |
| Průměrná doba vývoje | 70% rychlé úpravy | 60 % datové kanály, 20 % pravidla paměti, 20 % výzvy |
| Typický režim selhání | Náhlý pokles kvality výstupu po posunu dat | Odolné díky RAG, paměti a volání nástrojů |
Rychlý příklad: bot zákaznické podpory Proškolení pouze s pomocí výzev si dokáže vybavit zásady vrácení peněz, když jsou o to uživateli přímo požádáni. Když uživatel odkáže na „objednávku 45791“, selže. Přidejte kontextové inženýrství – historii konverzací a RAG dotaz do databáze objednávek – a bot okamžitě načte podrobnosti o nákupu a doporučí správný proces vrácení peněz.
Čtyři pilíře kontextového inženýrství, na kterých skutečně záleží
1. Kontext psaní (Vaše umělá inteligence's Systém pro psaní poznámek)
Psaní kontextu znamená ukládání informací mimo kontextové okno pro budoucí použití. Tím se zachovává cenný prostor pro tokeny a zároveň se zachovává přístup k důležitým datům.
Zápisníky fungují jako zapisování poznámek pro agenty v rámci jedné relace. Antropický's multiagentní výzkumník si ukládá svůj původní plán do „Memory„protože pokud kontext překročí 200,000 XNUMX tokenů, bude zkrácen a plán bude ztracen.“

Dlouhodobé vzpomínky uchovávat informace napříč více relacemi. Mezi příklady patří automatické generování uživatelských preferencí z konverzací pomocí ChatGPT a učení kurzoru/Windsurfingu kódovací vzory a kontext projektu.

2. Výběr kontextu (Umění vybrat si, na čem záleží)
Výběr kontextu přináší pouze relevantní informace pro daný úkol.
Když je AI kondiční trenér generuje tréninkový plán, musí vybrat kontextové detaily, které zahrnují uživatele's výška, váha a úroveň aktivity, přičemž ignoruje irelevantní informace.
Klíčový poznatekVíce informací neznamená vždy lépe. Efektivní kontextové inženýrství znamená výběr správné kombinace pro každý konkrétní úkol.
3. Komprese kontextu (vložení více do méně)
Když se konverzace tak protáhnou, že překročí LLM's paměť V tomto okně se stává komprese kontextu kritickou. Agenti toho obvykle dosahují shrnutím dřívějších částí konverzace.

4. Izolace kontextu (rozděl a panuj)
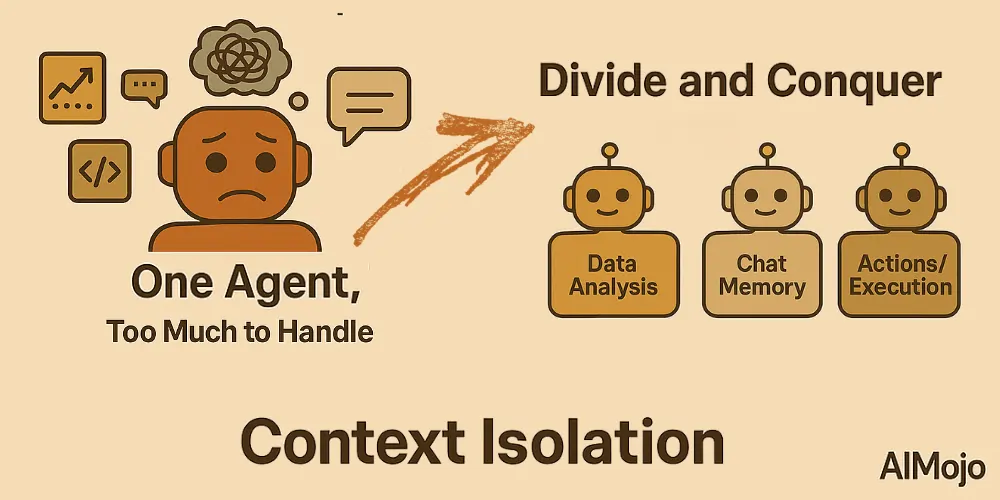
Izolace kontextu znamená rozdělení informací na samostatné části, aby agenti mohli lépe zvládat složité úkoly. Namísto nacpávání všech znalostí do jednoho obrovského výzvy vývojáři rozdělují kontext mezi specializované subagenty nebo sandboxová prostředí.
Kontextové inženýrství v reálném světě v praxi
Revoluce v zákaznickém servisu
| Před kontextovým inženýrstvím | Po kontextovém inženýrství |
|---|---|
| Generičtí chatboti, kteří zapomínají předchozí konverzace a poskytují irelevantní odpovědi. | AI agenti, kteří si pamatují historii vašich nákupů, mají přístup k údajům o zásobách v reálném čase a v případě potřeby koordinují činnost s lidskými agenty. |
Asistent kódování, který nikdy nezapomene
SystémKdyž se zeptáte „Jak opravím tuto chybu ověřování?“, systém kontextového inženýrství automaticky:

Místo obecných rad ohledně kódování získáte specifická řešení přizpůsobená vaší skutečné kódové základně.
Technická architektura, která pohání kontextové inženýrství
Dynamické kontextové sestavení
Kontext se vytváří za pochodu a vyvíjí se s postupem konverzace. Patří sem:
- Získávání relevantních dokumentů
- Udržování paměti
- Aktualizace stavu uživatele
- Volání API a dotazy do databáze
Správa kontextových oken
S pevnou velikostí limity tokenů (32K, 100K, 1M), inženýři musí inteligentně komprimovat a prioritizovat informace pomocí:
- Skórovací funkce (TF-IDF, vnoření, heuristika pozornosti)
- Shrnutí a extrakce významnosti
- Strategie dělení na bloky a ladění překrývání

Bezpečnost a důslednost
Používejte principy, jako je rychlá detekce injekčního podání, sanitizace kontextu, Redakční úprava osobních údajůa řízení přístupu na základě kontextu na základě rolí.
Vytvoření vašeho prvního systému kontextového inženýrství
Vytvoření pracovního postupu kontextového inženýrství není jen teorie – je to's opakovatelný proces, který lze operacionalizovat a dokonce automatizovat. Zde je návod, jak ho můžete uvést do praxe:
Krok 1: Zmapujte své kontextové zdroje
Určete, odkud váš agent potřebuje čerpat informace (dokumentace, databáze, API, předchozí chaty atd.).
krajta
# Example: Fetching relevant documents using embeddings
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer("all-MiniLM-L6-v2")
query = "project status update"
corpus = ["spec doc", "requirements", "last week's meeting notes"]
query_embedding = model.encode(query, convert_to_tensor=True)
corpus_embeddings = model.encode(corpus, convert_to_tensor=True)
hits = util.semantic_search(query_embedding, corpus_embeddings, top_k=2)[0]
relevant_docs = [corpus[hit['corpus_id']] for hit in hits]
Krok 2: Implementace kontextu paměti a zápisu
Uložte si důležité informace, abyste je měli vždy po ruce pro budoucí úkoly.
krajta
import json
def save_to_memory(memory_path, user_id, data):
with open(memory_path, "r+") as file:
memory = json.load(file)
memory[user_id] = data
file.seek(0)
json.dump(memory, file)
file.truncate()Krok 3: Vytvoření logiky výběru a komprese kontextu
Vyvíjejte pravidla nebo modely, které vybírají pouze to, co je pro daný úkol nejrelevantnější. Zkomprimujte dlouhé historie do souhrnných forem.
krajta
def summarize_conversation(history):
# Placeholder for use with an LLM summarizer or custom rules
return history[-5:] # Only the last 5 messagesKrok 4: Izolace kontextů pro koordinaci agentů
Rozdělte informace tak, aby každý agent nebo komponenta zpracovával pouze to, co by měl.
krajta
user_profile_ctx = {"user_goals": "..."}
task_specific_ctx = {"current_task": "..."}
external_data_ctx = {"live_data": "..."}
full_context = {**user_profile_ctx, **task_specific_ctx, **external_data_ctx}Krok 5: Strukturování výstupu a připravenost API
Konzistentně formátujte výstupní kontext, aby's předvídatelné pro následná volání LLM nebo koncové body API.
krajta
schema = {
"user": {"age": 35, "goal": "muscle gain"},
"plan": "high protein, 3x/week weight training"
}Krok 6: Monitorování, iterace a zabezpečení
Sledujte selhání, auditujte kvalitu kontextu a vylepšujte logiku pro zahrnutí kontextu, paměť a načítání. Vždy dezinfikujte vstupy, abyste zabránili okamžitému vkládání dat a únikům dat.
Proč se kontextové inženýrství vyplácí více než rychlé inženýrství
Firmy potřebují inženýry, kteří dokáží vytvářet systémy, jež poskytují správný kontext pro umělou inteligenci, udržují informace přesné a aktuální a chrání uživatele přidáním bezpečnostních pokynů.
Realita trhuKontextové inženýrství vyžaduje mezioborové dovednosti, které zahrnují pochopení obchodních případů užití, definování výstupů a strukturování informací, aby LLM specialisté mohli plnit složité úkoly.
Sečteno a podtrženo: Psát výzvy umí kdokoli. Vytvářet kontextově uvědomělé agenty, kteří si pamatují, přizpůsobují a vybírají kontext ve velkém měřítku? Takto si vývojáři zajišťují budoucnost svých dovedností a přinášejí skutečnou hodnotu s pokročilými aplikacemi LLM.



 BONUS: Získejte našich 200 dolarůAI „Sada nástrojů pro mistrovství“ ZDARMA při registraci!
BONUS: Získejte našich 200 dolarůAI „Sada nástrojů pro mistrovství“ ZDARMA při registraci!






