
Инженерните екипи, внедряващи LLM услуги, трябва да отговорят на един критичен въпрос: Колко надежден и стабилен е нашият модел в реални сценарии?
Оценката на големи езикови модели вече надхвърля простите проверки за точност, използвайки многопластови рамки за тестване на запазването на контекста, валидността на разсъжденията и обработката на гранични случаи. С пазар, залят от модели, вариращи от Параметри от 1B до 2T, изборът на оптимален модел изисква строги, многоизмерни протоколи за оценка.
Това ръководство описва подробно техническите методи и основните показатели, които оформят най-добрите практики през 2026 г., помагайки на машинното обучение (ML) да открият недостатъци, преди те да достигнат до производствената среда.
Рамки за оценка на големи езикови модели
Модерен дизайн LLM оценка включва множество количествени и качествени измерения да заснемете модел's истински възможности. Последните проучвания показват, че 67% от предприятията AI внедряванията се представят по-слабо поради неадекватен избор на модел – което подчертава защо сложната оценка не е просто незадължителна, а критично важна за бизнеса.

Основни компоненти за оценка
Проучване от 2026 г Станфорд's AI индекс разкрива, че компаниите, инвестиращи в цялостни протоколи за оценка на LLM, отчитат 42% по-висока възвръщаемост на инвестициите си AI инициативи в сравнение с тези, използващи опростени показатели.
Разбивка на техническите показатели
Съвременните рамки за оценка използват десетки специализирани показатели, всяка от които е насочена към специфични възможности на LLM:
Показатели за ефективност
недоумение количествено определя несигурността на прогнозата, като изчислява експоненциалната стойност на средната отрицателна логаритмична вероятност в тестов корпус. По-ниските стойности показват по-добра производителност, като най-съвременните модели постигат степен на объркване под 3.0 върху стандартизирани набори от данни.
F1 резултат комбинира прецизност и пълнота на изчисление чрез формулата за хармонична средна стойност:
F1 = 2 * (precision * recall) / (precision + recall)Това създава балансирана оценка, особено ценна за задачи за класификация с дисбаланс в класовете.
Кръстосана загуба на ентропия измерва несъответствието между прогнозираните вероятностни разпределения и реалността, използвайки формулата:
L(y, ŷ) = -∑(y_i * log(ŷ_i))Това наказва по-сериозно уверените, но неправилни прогнози, насърчавайки калибрирането на модела.
BLEU (двуезична оценка на дублиране) изчислява n-грамово припокриване между генерирани и референтни текстове, използвайки средно геометрична стойност на резултатите от прецизността с наказание за краткост:
BLEU = BP * exp(∑(w_n * log(p_n)))Където BP е наказанието за краткост, а p_n е прецизността от n грама.
Специфични за RAG показатели
За системите за генериране на добавени данни, специализираните показатели включват:
вярност количествено определя фактическата съгласуваност между генерирания резултат и извлечения контекст, използвайки подходи QAG (генериране на въпроси и отговори). Изследванията показват RAG системи с резултати за достоверност под 0.7 предизвикват халюцинации в 42% от резултатите.
Прецизност на извличане@K измерва дела на съответните документи сред първите K извлечени резултати:
Precision@K = (number of relevant docs in top K) / KИндустриалните показатели показват P@3 > 0.85 за системи от корпоративен клас.
Точност на цитирането оценява точността на цитатите в генерираното съдържание, изчислена като:
Citation Precision = correct citations / total citationsАнализът на водещите RAG системи показва средна точност на цитиране от 0.71 в техническите области.
Набори от данни за бенчмарк: Технически спецификации
Наборите от данни за бенчмаркинг предоставят стандартизирани рамки за оценка със специфични технически характеристики:

MMLU-Pro Включва 15,908 10 въпроса с избираем отговор и 4 варианта на въпрос (в сравнение с 57 в стандартния MMLU), обхващащи 89.2 области, включително висша математика, медицина, право и компютърни науки. Средно експертно представяне на хора: XNUMX%.
GPQA Съдържа 448 експертно проверени въпроса на ниво завършили студенти със средна дължина на маркера 612, фокусирани върху STEM области. Текуща SOTA производителност: 41.2% точност (GPT-4).
МюСР Реализира алгоритмично генерирани многостъпкови задачи за разсъждение с графики на зависимости със средна дълбочина 4.7, изискващи моделите да изпълняват верижни логически операции. Средна разлика в производителността между най-добрите модели и произволната базова линия: 17.8 процентни пункта.
bbh включва 23 предизвикателни задачи от BigBench с 2,254 отделни примера, фокусирани върху сложни разсъжденияТези задачи показват висока корелация (r=0.82) с оценките на човешките предпочитания при сляпо оценяване.
LEвал специализира в оценка на дълъг контекст с 411 въпроса в 8 категории задачи с дължина на контекста, варираща от 5 200 до 0.4 10 токена. Настоящите модели показват влошаване на производителността от приблизително XNUMX% на всеки XNUMX XNUMX допълнителни токена.
Алгоритми за оценка и внедряване
Техническото внедряване на LLM оценката следва специфични алгоритмични подходи:
Векторно-базирана семантична оценка
Съвременните системи използват векторни вграждания, за да измерват семантичното сходство между генерирани и референтни текстове. Използвайки техники за плътно извличане като HNSW (Йерархичен навигационен малък свят), LSH (Локално-чувствително хеширане) и PQ (Квантоване на продукта), тези системи изчисляват оценките за сходство със сублинейна времева сложност.
python
from sentence_transformers import SentenceTransformer
import numpy as np
model = SentenceTransformer('all-MiniLM-L6-v2')
reference = model.encode("Reference text")
generated = model.encode("Generated text")
similarity = np.dot(reference, generated) / (np.linalg.norm(reference) * np.linalg.norm(generated))Внедряване на DeepEval Framework
DeepEval предоставя цялостна оценка с обяснения на показателите, поддържайки както RAG, така и сценарии за фина настройка:
python
from deepeval import assert_test
from deepeval.metrics import HallucinationMetric
from deepeval.test_case import LLMTestCase
test_case = LLMTestCase(
input="How many evaluation metrics does DeepEval offers?",
actual_output="14+ evaluation metrics",
context=["DeepEval offers 14+ evaluation metrics"]
)
metric = HallucinationMetric(minimum_score=0.7)
def test_hallucination():
assert_test(test_case, [metric])Тази рамка третира оценките като единични тестове с интеграция с Pytest, предоставяйки не само резултати, но и обяснения за нивата на производителност.
Параметрично ефективни подходи за оценка
За мащабна оценка на модели с милиарди параметри са се появили специализирани техники:

Механизми за оскъдно внимание намаляване на изчислителна сложност чрез оптимизация на моделите на внимание. Техники като Longformer's Моделите на внимание показват 91% точност на пълно внимание, като само 25% от изчисленията са необходими.
Смес от експерти (MoE) Архитектурите имплементират условни изчислителни пътища, активирайки само съответните подмрежи за специфични задачи. GShard внедрява MoE внимание за параметрично ефективна оценка в различни бенчмаркове.
Дестилация на знания компресира по-големи модели на учители в по-малки, специфични за оценяването модели на ученици, използвайки:
L_distill = α * L_CE(y, ŷ_student) + (1-α) * L_KL(ŷ_teacher, ŷ_student)
Където L_CE е загубата на кръстосана ентропия, а L_KL е KL-дивергенцията между вероятностните разпределения.
Предизвикателства пред систематичната оценка
Въпреки напредналите методологии, продължават да съществуват значителни предизвикателства при оценката на LLM:
Замърсяване с бенчмарк
Проучванията показват, че 47% от популярните бенчмаркове имат известна степен на замърсяване в данните за обучение. AI демонстрираха това, като създадоха GSM1k, по-малък вариант на математическия бенчмарк GSM8k. Моделите се представиха с 12.3% по-зле на GSM1k отколкото на GSM8k, което показва по-скоро свръхобучение, отколкото математически разсъждения способност.
Анализ на корелацията на показателите
Цялостният анализ на 14 популярни показателя в 8 задачи разкрива ниска междуметрична корелация (средна стойност по скалата на Спирман)'s ρ = 0.41), което показва, че показателите обхващат различни измерения на производителността. Това подчертава необходимостта от многомерни подходи за оценка.
Изследвания от MIT показват, че високите резултати за объркване корелират с човешките предпочитания при r=0.68, докато ROUGE-L корелира само при r=0.39, което показва разнообразни изисквания за оценяване.
Количествено определяне на отклоненията при оценката
Статистическият анализ на човешките оценки разкрива множество систематични отклонения:
Тези открития подчертават значението на рандомизацията и балансирания експериментален дизайн в протоколите за оценка.
Най-добри практики за оценка на предприятията
За да се справите с предизвикателствата при оценяването, внедрете тези най-добри практики в индустрията:
Многомодална метрична интеграция
Комбинирайте допълващи се показатели, използвайки претеглени ансамбли, за да създадете цялостни рамки за оценка:
python
def ensemble_score(outputs, references, weights=None):
metrics = {
'bleu': compute_bleu(outputs, references),
'bertscore': compute_bertscore(outputs, references),
'faithfulness': compute_faithfulness(outputs, references),
'coherence': compute_coherence(outputs)
}
if weights is None:
weights = {metric: 1/len(metrics) for metric in metrics}
return sum(weights[metric] * metrics[metric] for metric in metrics)Водещите организации прилагат адаптивни схеми за тегловно претегляне, базирани на специфични за задачата изисквания, като техническото съдържание дава приоритет на достоверността (тегло: 0.4) пред плавността (тегло: 0.2).
Протоколи за оценка, специфични за дадена област
Техническите показатели трябва да са съобразени със специфичните случаи на употреба. За приложения за здравеопазване, специализираните показатели включват:
- Точност на медицинската терминология (89% корелация с преценката на лекаря)
- Валидиране на пътя на клиничното разсъждение (75% съгласие с експертния консенсус)
- Прецизност на извличане на доказателства от медицинска литература (P@10 > 0.92 за внедряване в предприятия)
Тези специфични за домейна показатели осигуряват 3.2× по-добра прогноза за производителността от общите бенчмаркове.
Внедряване на състезателна оценка
Приложете структурирано състезателно тестване, за да проучите ограниченията на модела:
python
def adversarial_test_suite(model, test_cases):
results = {}
for category, cases in test_cases.items():
correct = 0
for case in cases:
response = model.generate(case['input'])
correct += evaluate_response(response, case['expected'])
results[category] = correct / len(cases)
return resultsПроучвания в индустрията показват състезателно тестване идентифицира 32% повече режими на отказ от стандартния бенчмаркинг, особено в гранични случаи, включващи конфликтни ограничения или двусмислени инструкции.
Сравнение на рамката за техническа оценка
Водещите рамки за оценка предлагат различни технически възможности:
| Рамка | Основен фокус | Техническа здравина | ограничаване | Сложност на интеграцията |
|---|---|---|---|---|
| DeepEval | RAG и фина настройка | 14+ специализирани показатели с обяснения | Ограничена мултимодална поддръжка | Medium (базиран на Python) |
| PromptFlow | Оценка от край до край | Бързо тестване на вариации | Ограничена поддръжка на набори от данни | Ниско (ориентирано към потребителския интерфейс) |
| ЛангСмит | Платформа за разработчици | Пълно проследяване и наблюдение | По-високи разходи за внедряване | Високо (изисква API интеграция) |
| Прометей | Магистър по право (LLM) като съдия | Стратегии за систематично подтикване | Зависимост от пристрастия при съдията по магистърска степен по право | Средно (изисква се солидна магистърска степен по право) |
| LEвал | Оценка в дългосрочен контекст | Оценка на 200 XNUMX токена | Ограничено до текстова модалност | Ниско (бенчмарк набор от данни) |
Организациите обикновено внедряват множество рамки, като 73% от корпоративните внедрявания използват поне два допълващи се инструмента за оценка.
Бъдещи технически разработки
Оценъчният пейзаж продължава да се развива с нововъзникващите методологии:
Търсене на невронна архитектура (NAS) За модели, специфични за оценката, набира скорост, като изследванията показват, че автоматизираната оптимизация на архитектурата на модела може да подобри ефективността на оценката с 47%, като същевременно поддържа 98% точност.
Мултимодална оценка рамките се разширяват отвъд текста, за да оценят унифицираните модели за обработка на текст, изображения, аудио и видео. Настоящите рамки постигат междумодална точност на заземяване от 76.3% в сравнение с човешки базови стойности от 91.4%.
Показатели за енергийна ефективност количествено определяне на изчислителната устойчивост, използвайки FLOPs/токен, извеждайки ватчасове и показатели за емисии на въглерод. Сравнителните показатели в индустрията показват, че оптималните модели трябва да постигат <10 mWh на 1 генерирани токена.
Тръбопроводи за непрекъсната оценка интегрирайте тестването по време на разработката, използвайки разпределени работни потоци за оценка:
Preprocessing → Feature Extraction → Model Inference → Metric Computation → Statistical Analysis → Reporting
Организациите, внедряващи непрекъсната оценка, отчитат 68% по-малко проблеми след внедряването и 41% по-бързи итерационни цикли.
Казуси от внедряване в реалния свят
Корпоративните внедрявания демонстрират техническа оценка's практическо въздействие:
Оптимизация на RAG за финансови услуги
Водеща финансова институция внедри цялостна оценка на RAG за своята консултантска система, насочена към клиентите:
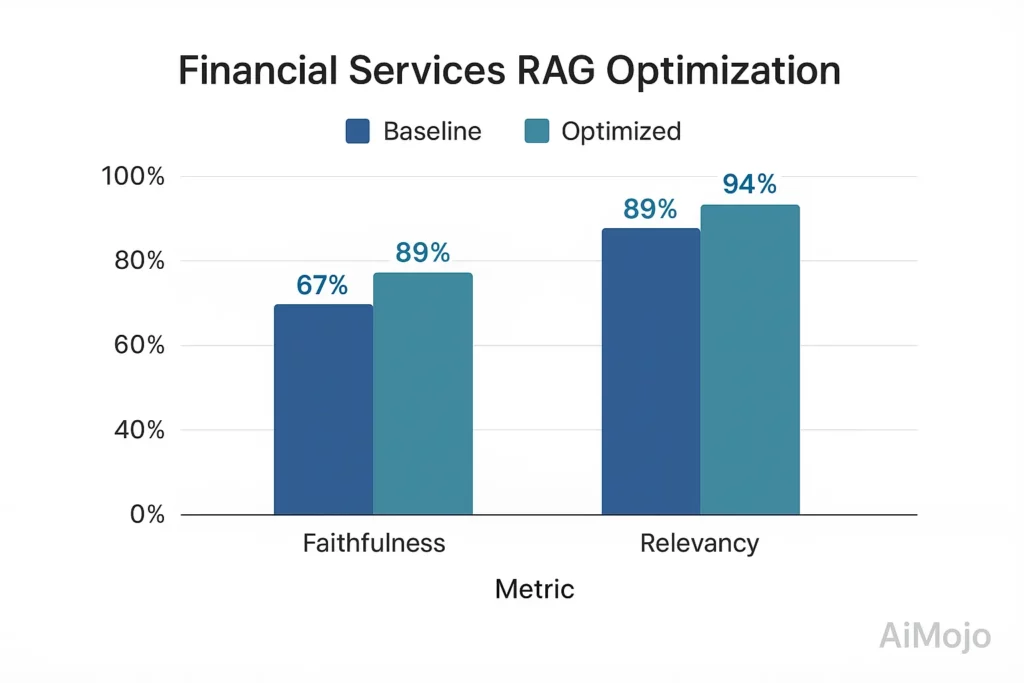
- Изходно ниво: 67% достоверност, 82% релевантност на отговора
- След оптимизация, базирана на оценка: 89% достоверност, 94% релевантност на отговора
- Изпълнение: Custom финансова област тестов набор с 5,216 експертно проверени QA двойки
- Технически подход: Оценяване на достоверността чрез измерване на тензорно-базирано привличане с контрафактуално тестване
Това подобрение, основано на оценка, намали проблемите със съответствието с регулаторните изисквания със 78% и увеличи оценките за удовлетвореност на клиентите с 23 процентни пункта.
Внедряване на LLM в здравеопазването
Доставчик на здравни услуги внедри многопластова оценка за подкрепа на клиничните решения:
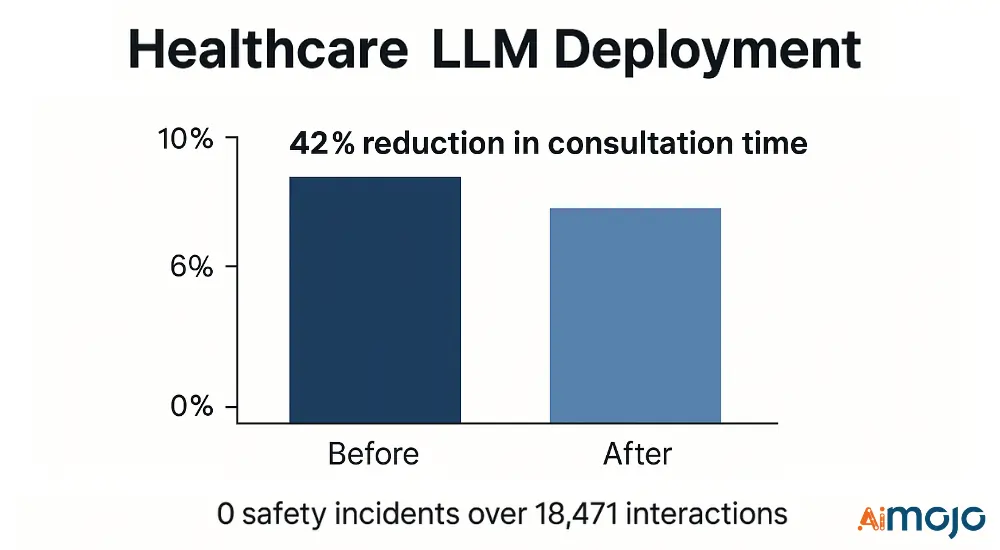
- Технически показатели: Медицински NER F1 резултат (0.91), точност на клиничното разсъждение (87.4%), прецизност на филтриране за безопасност (99.2%)
- Изпълнение: 3-степенен филтриращ конвейер със специализирани валидатори за здравеопазване
- резултати: 42% намаление на времето за консултации с 0 инцидента, свързани с безопасността, при 18,471 XNUMX клинични взаимодействия
Рамката за оценка идентифицира и смекчи 17 критични режима на отказ преди внедряването, предотвратявайки потенциални нежелани събития.
Оценка на LLM: Вашият път към успеха
Техническата оценка на LLM се е преместила от прости проверки за точност до всеобхватни рамки, които отчитат множество измерения на производителността. Организациите, които приемат тези строги протоколи и интегрират... автоматизирано оценяване, бенчмарк тестване и човешки надзор-постигане на по-надежден избор на модел и по-силни резултати.
Редовните, адаптивни тестови процеси разкриват недостатъци преди внедряването, което прави разходите за предварителна оценка малки в сравнение с рисковете от внедряването на дефектна система. За инженерните екипи, надеждните стъпки за валидиране са повече от... задачи за разработка; те са основни предпазни мерки за бизнеса.
През 2026 г. и след това екипите, които усъвършенстват методите си за оценка, ще запазят надеждността на своите LLM, ще предотвратят скъпоструващи грешки и ще запазят доверието на потребителите.



 БОНУС: Вземете нашите 200 долараAI „Набор от инструменти за майсторство“ БЕЗПЛАТНО при регистрация!
БОНУС: Вземете нашите 200 долараAI „Набор от инструменти за майсторство“ БЕЗПЛАТНО при регистрация!


![10-те най-добри портиера AI Алтернативи с NSFW Chat [май 2026 г.]](https://aimojo.io/wp-content/uploads/2024/01/Best-Janitor-AI-Alternatives-100x100.webp)



