
يجب على فرق الهندسة التي تنشر خدمات LLM الإجابة على سؤال بالغ الأهمية: ما مدى موثوقية وقوة نموذجنا في السيناريوهات الواقعية؟
يتجاوز تقييم نماذج اللغة الكبيرة الآن مجرد اختبارات الدقة البسيطة، إذ يستخدم أطرًا متعددة الطبقات لاختبار الحفاظ على السياق، وصلاحية الاستدلال، ومعالجة الحالات الحدية. ومع غمر السوق بنماذج تتراوح من معلمات 1B إلى 2Tيتطلب اختيار النموذج الأمثل بروتوكولات تقييم صارمة ومتعددة الأبعاد.
يقدم هذا الدليل تفاصيل الأساليب الفنية والمقاييس الأساسية التي تشكل أفضل الممارسات في عام 2026، مما يساعد مهندسي التعلم الآلي على اكتشاف العيوب قبل وصولها إلى الإنتاج.
أطر لتقييم نموذج اللغة الكبير
بلمسة عصرية تقييم ماجستير الحقوق يتضمن العديد من الأبعاد الكمية والنوعية لالتقاط نموذج's القدرات الحقيقية. أظهرت الأبحاث الحديثة أن 67% من المؤسسات AI إن عمليات النشر لا تحقق أداءً جيدًا بسبب الاختيار غير الكافي للنموذج - وهو ما يسلط الضوء على سبب كون التقييم المتطور ليس مجرد أمر اختياري بل إنه أمر بالغ الأهمية للأعمال.

مكونات التقييم الأساسية
دراسة 2026 من ستانفورد's AI فهرس تكشف الشركات التي تستثمر في بروتوكولات تقييم LLM الشاملة أن العائد على الاستثمار أعلى بنسبة 42% AI المبادرات مقارنة بتلك التي تستخدم مقاييس مبسطة.
تفاصيل المقاييس الفنية
تستخدم أطر التقييم الحديثة العشرات من المقاييس المتخصصة، كل منها يستهدف قدرات LLM محددة:
مقاييس الأداء
حيرة يُقيِّم عدم اليقين في التنبؤ بحساب الأسّي لمتوسط احتمال اللوغاريتم السالب عبر مجموعة بيانات اختبار. تشير القيم المنخفضة إلى أداء أفضل، حيث تحقق النماذج الحديثة درجة حيرة أقل من 3.0 في مجموعات البيانات القياسية.
نقاط F1 يجمع بين الدقة والتذكير من خلال صيغة المتوسط التوافقي:
F1 = 2 * (precision * recall) / (precision + recall)يؤدي هذا إلى إنشاء تقييم متوازن ذي قيمة خاصة لمهام التصنيف ذات الخلل في التوازن بين الفئات.
خسارة عبر الانتروبيا يقيس التناقض بين توزيعات الاحتمالات المتوقعة والحقيقة الأساسية باستخدام الصيغة:
L(y, ŷ) = -∑(y_i * log(ŷ_i))ويؤدي هذا إلى فرض عقوبات أشد على التوقعات الواثقة ولكن غير الصحيحة، مما يشجع على معايرة النموذج.
BLEU (بديل التقييم ثنائي اللغة) يحسب تداخل n-gram بين النصوص المولدة والمرجعية، باستخدام متوسط هندسي لدرجات الدقة مع عقوبة الإيجاز:
BLEU = BP * exp(∑(w_n * log(p_n)))حيث أن BP هي عقوبة الإيجاز و p_n هي دقة n-gram.
مقاييس خاصة بـ RAG
بالنسبة لأنظمة توليد الاسترجاع المعزز، تتضمن المقاييس المتخصصة ما يلي:
الإخلاص يُقيِّم الاتساق الفعلي بين المخرجات المُولَّدة والسياق المُسترجع باستخدام أساليب توليد الأسئلة والأجوبة (QAG). تُظهر الأبحاث أنظمة RAG مع درجات إخلاص أقل من 0.7، تحدث الهلوسة في 42% من النتائج.
دقة الاسترجاع @K يقيس نسبة المستندات ذات الصلة بين أفضل النتائج المسترجعة:
Precision@K = (number of relevant docs in top K) / Kتشير معايير الصناعة إلى أن P@3 > 0.85 لأنظمة الدرجة المؤسسية.
دقة الاستشهاد يقوم بتقييم دقة الاستشهادات في المحتوى المُولّد، ويتم حسابها على النحو التالي:
Citation Precision = correct citations / total citationsيكشف تحليل أنظمة RAG الرائدة عن دقة الاستشهاد بمعدل 0.71 في المتوسط عبر المجالات الفنية.
مجموعات البيانات المعيارية: المواصفات الفنية
توفر مجموعات البيانات المعيارية أطر تقييم موحدة ذات خصائص تقنية محددة:

MMLU-Pro يتضمن ١٥٩٠٨ أسئلة اختيار من متعدد، بواقع ١٠ خيارات لكل سؤال (مقارنةً بـ ٤ في امتحان MMLU القياسي)، ويغطي ٥٧ مجالًا، بما في ذلك الرياضيات المتقدمة، والطب، والقانون، وعلوم الحاسوب. متوسط أداء الخبراء: ٨٩.٢٪.
GPQA يحتوي على 448 سؤالاً لطلاب الدراسات العليا، مُتحققاً من قِبل خبراء، بمتوسط طول رمزي يبلغ 612، مع التركيز على مجالات العلوم والتكنولوجيا والهندسة والرياضيات. أداء SOTA الحالي: دقة 41.2% (GPT-4).
موسر يُنفِّذ مسائل استدلالية متعددة الخطوات، مُولَّدة خوارزميًا، مع رسوم بيانية تبعية بمتوسط عمق 4.7، مما يتطلب من النماذج إجراء عمليات منطقية متسلسلة. متوسط فجوة الأداء بين النماذج العليا وخط الأساس العشوائي: 17.8 نقطة مئوية.
BBH يتضمن 23 مهمة صعبة من BigBench مع 2,254 مثالًا فرديًا يركز على المنطق المعقدتظهر هذه المهام ارتباطًا عاليًا (r=0.82) مع تقييمات التفضيل البشري في التقييمات العمياء.
ليفال يتخصص في تقييم السياقات الطويلة، ويتضمن 411 سؤالاً موزعة على 8 فئات مهام، بأطوال سياقات تتراوح بين 5 آلاف و200 ألف رمز. تُظهر النماذج الحالية انخفاضًا في الأداء بنسبة 0.4% تقريبًا لكل 10 آلاف رمز إضافي.
خوارزميات التقييم والتنفيذ
ويتبع التنفيذ الفني لتقييم LLM مناهج خوارزمية محددة:
التقييم الدلالي القائم على المتجهات
تستخدم الأنظمة الحديثة تضمينات المتجهات لقياس التشابه الدلالي بين النصوص المُولّدة والنصوص المرجعية. باستخدام تقنيات الاسترجاع المكثف، مثل HNSW (العالم الصغير الهرمي القابل للتنقل)، وLSH (التجزئة الحساسة للموقع)، وPQ (تكميم المنتج)، تحسب هذه الأنظمة درجات التشابه بتعقيد زمني دون الخطي.
python
from sentence_transformers import SentenceTransformer
import numpy as np
model = SentenceTransformer('all-MiniLM-L6-v2')
reference = model.encode("Reference text")
generated = model.encode("Generated text")
similarity = np.dot(reference, generated) / (np.linalg.norm(reference) * np.linalg.norm(generated))تنفيذ إطار عمل DeepEval
يوفر DeepEval تقييمًا شاملاً مع تفسيرات مترية، ويدعم كل من سيناريوهات RAG والضبط الدقيق:
python
from deepeval import assert_test
from deepeval.metrics import HallucinationMetric
from deepeval.test_case import LLMTestCase
test_case = LLMTestCase(
input="How many evaluation metrics does DeepEval offers?",
actual_output="14+ evaluation metrics",
context=["DeepEval offers 14+ evaluation metrics"]
)
metric = HallucinationMetric(minimum_score=0.7)
def test_hallucination():
assert_test(test_case, [metric])يتعامل هذا الإطار مع التقييمات باعتبارها اختبارات وحدات مع تكامل Pytest، مما يوفر ليس فقط النتائج ولكن أيضًا تفسيرات لمستويات الأداء.
مناهج التقييم الفعالة للمعلمات
لتقييم النماذج واسعة النطاق التي تحتوي على مليارات المعلمات، ظهرت تقنيات متخصصة:

آليات الانتباه المتفرق تخفيض التعقيد الحسابي من خلال تحسين نمط الانتباه. تقنيات مثل Longformer's تظهر أنماط الانتباه دقة بنسبة 91% من الاهتمام الكامل مع 25% فقط من الحساب.
خليط من الخبراء (MoE) تُطبّق البنى مسارات حسابية مشروطة، وتُفعّل الشبكات الفرعية ذات الصلة فقط لمهام محددة. يُطبّق GShard اهتمام MoE لتقييم فعّال للمعلمات عبر معايير مرجعية متنوعة.
تقطير المعرفة يضغط نماذج المعلمين الأكبر حجمًا في نماذج طلابية أصغر حجمًا ومحددة للتقييم باستخدام:
L_distill = α * L_CE(y, ŷ_student) + (1-α) * L_KL(ŷ_teacher, ŷ_student)
حيث أن L_CE هي خسارة الإنتروبيا المتقاطعة و L_KL هي تباعد KL بين توزيعات الاحتمالات.
تحديات التقييم المنهجي
على الرغم من المنهجيات المتقدمة، لا تزال هناك تحديات كبيرة في تقييم الماجستير في القانون:
تلوث المعايير
تشير الدراسات إلى أن 47% من معايير الأداء الشائعة تعاني من درجة معينة من التلوث في بيانات التدريب. AI أثبت ذلك بإنشاء GSM1k، وهو نسخة أصغر من معيار رياضي GSM8k. كان أداء النماذج أسوأ بنسبة 12.3% على GSM1k مقارنةً بـ GSM8k، مما يشير إلى الإفراط في التجهيز بدلاً من المنطق الرياضي القدرة.
تحليل الارتباط المتري
يكشف التحليل الشامل لـ 14 مقياسًا شائعًا عبر 8 مهام عن ارتباط منخفض بين المقاييس (متوسط سبيرمان)'s ρ = 0.41)، مما يشير إلى أن المقاييس تقيس أبعاد أداء مختلفة. وهذا يؤكد ضرورة اتباع مناهج تقييم متعددة المقاييس.
تظهر الأبحاث من معهد ماساتشوستس للتكنولوجيا أن درجات الحيرة العالية ترتبط بالتفضيلات البشرية عند r=0.68، في حين يرتبط ROUGE-L فقط عند r=0.39، مما يشير إلى متطلبات تقييم متنوعة.
تحيزات التقييم والقياس الكمي
يكشف التحليل الإحصائي للتقييمات البشرية عن تحيزات منهجية متعددة:
وتسلط هذه النتائج الضوء على أهمية العشوائية والتصميم التجريبي المتوازن في بروتوكولات التقييم.
أفضل ممارسات تقييم المؤسسات
ولمعالجة تحديات التقييم، قم بتنفيذ أفضل الممارسات الصناعية التالية:
تكامل المقاييس المتعددة الوسائط
دمج المقاييس التكميلية باستخدام مجموعات مرجحة لإنشاء أطر تقييم شاملة:
python
def ensemble_score(outputs, references, weights=None):
metrics = {
'bleu': compute_bleu(outputs, references),
'bertscore': compute_bertscore(outputs, references),
'faithfulness': compute_faithfulness(outputs, references),
'coherence': compute_coherence(outputs)
}
if weights is None:
weights = {metric: 1/len(metrics) for metric in metrics}
return sum(weights[metric] * metrics[metric] for metric in metrics)تطبق المنظمات الرائدة مخططات ترجيح قابلة للتكيف استنادًا إلى متطلبات محددة للمهمة، مع إعطاء الأولوية للمحتوى الفني للإخلاص (الوزن: 0.4) على الطلاقة (الوزن: 0.2).
بروتوكولات التقييم الخاصة بالمجال
يجب أن تتوافق المعايير الفنية مع حالات الاستخدام المحددة. تطبيقات الرعاية الصحيةوتشمل المقاييس المتخصصة ما يلي:
- دقة المصطلحات الطبية (ارتباط بنسبة 89% مع حكم الطبيب)
- التحقق من صحة مسار التفكير السريري (75% اتفاق مع إجماع الخبراء)
- دقة استرجاع الأدلة من الأدبيات الطبية (P@10 > 0.92 للنشر المؤسسي)
توفر مقاييس الأداء الخاصة بالمجال هذه تنبؤات أداء أفضل بمقدار 3.2 مرة من المعايير العامة.
تنفيذ التقييم التنافسي
تنفيذ اختبارات تنافسية منظمة لاستكشاف قيود النموذج:
python
def adversarial_test_suite(model, test_cases):
results = {}
for category, cases in test_cases.items():
correct = 0
for case in cases:
response = model.generate(case['input'])
correct += evaluate_response(response, case['expected'])
results[category] = correct / len(cases)
return resultsتظهر أبحاث الصناعة اختبار الخصومة يحدد 32% من أوضاع الفشل أكثر من معايير المعايرة القياسية، وخاصة في الحالات الحدية التي تنطوي على قيود متضاربة أو تعليمات غامضة.
مقارنة إطار التقييم الفني
توفر أطر التقييم الرائدة قدرات فنية مختلفة:
| الإطار | التركيز الأساسي | القوة الفنية | تحديد | تعقيد التكامل |
|---|---|---|---|---|
| ديب إيفال | RAG والضبط الدقيق | أكثر من 14 مقياسًا متخصصًا مع الشروحات | دعم متعدد الوسائط محدود | متوسط (يعتمد على بايثون) |
| برومبت فلو | التقييم الشامل | اختبار التباين الفوري | دعم محدود لمجموعة البيانات | منخفض (مدفوع بواجهة المستخدم) |
| لانج سميث | منصة المطور | التتبع والمراقبة الكاملة | تكاليف تنفيذ أعلى | عالية (تتطلب تكامل واجهة برمجة التطبيقات) |
| محب العمل | ماجستير في القانون كقاضي | استراتيجيات التحفيز المنهجي | اعتماد تحيز القاضي LLM | متوسط (يتطلب درجة ماجستير قوية في القانون) |
| ليفال | التقييم في سياق طويل | تقييم رمز 200 ألف | يقتصر على نمط النص | منخفض (مجموعة بيانات معيارية) |
تطبق المؤسسات عادةً أطر عمل متعددة، حيث تستخدم 73% من عمليات النشر في المؤسسات أداتين تقييم متكاملتين على الأقل.
التطورات التقنية المستقبلية
يستمر مشهد التقييم في التطور مع ظهور المنهجيات التالية:
بحث العمارة العصبية (NAS) تكتسب نماذج التقييم المحددة زخمًا متزايدًا، حيث أظهرت الأبحاث أن تحسين بنية النموذج الآلي يمكن أن يحسن كفاءة التقييم بنسبة 47% مع الحفاظ على 98% من الدقة.
التقييم متعدد الوسائط تتوسع الأطر خارج النص لتقييم موحد نماذج معالجة النصوصالصور والصوت والفيديو. تحقق الأطر الحالية دقة تأريض متعددة الوسائط بنسبة 76.3%، مقارنةً بالخطوط الأساسية البشرية البالغة 91.4%.
مقاييس كفاءة الطاقة تحديد الاستدامة الحسابية باستخدام وحدات FLOP/الرمز، واستنتاج وحدات الواط/الساعة، ومقاييس انبعاثات الكربون. تشير معايير الصناعة إلى أن النماذج المثلى يجب أن تحقق أقل من 10 ميجاوات/ساعة لكل ألف رمز مُولَّد.
خطوط التقييم المستمر دمج الاختبار طوال التطوير باستخدام سير عمل التقييم الموزعة:
Preprocessing → Feature Extraction → Model Inference → Metric Computation → Statistical Analysis → Reporting
تشير التقارير إلى أن المنظمات التي تنفذ التقييم المستمر تعاني من مشكلات أقل بنسبة 68% بعد النشر ودورات تكرار أسرع بنسبة 41%.
دراسات حالة تطبيقية في العالم الحقيقي
تُظهر تنفيذات المؤسسة التقييم الفني's التأثير العملي:
تحسين خدمات RAG المالية
نفذت مؤسسة مالية رائدة تقييمًا شاملاً لـ RAG لنظامها الاستشاري الموجه للعملاء:
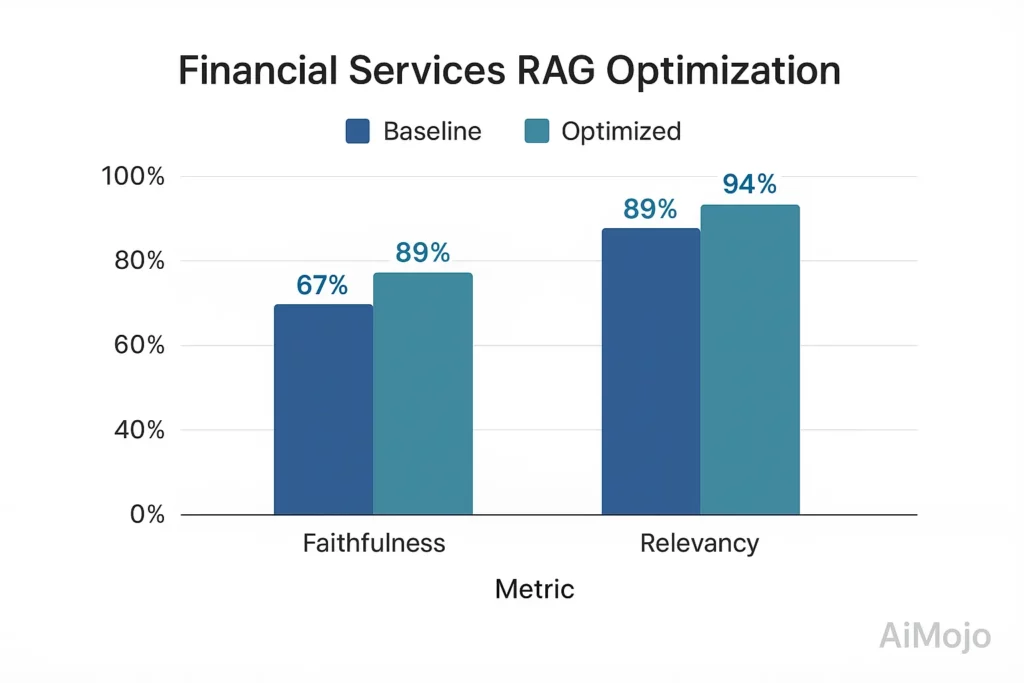
- حدود: 67% إخلاص، 82% صلة بالإجابة
- بعد التحسين الموجه بالتقييم: 89% إخلاص، 94% صلة بالإجابة
- التنفيذ: فن التأطير المتخصص المجال المالي مجموعة اختبار تحتوي على 5,216 زوجًا من ضمان الجودة تم التحقق منها من قبل الخبراء
- النهج الفني: تقييم الإخلاص باستخدام قياس الاستلزام القائم على الموتر مع الاختبار المضاد للواقع
وقد أدى هذا التحسين القائم على التقييم إلى تقليل مشكلات الامتثال التنظيمي بنسبة 78% وزيادة درجات رضا العملاء بنسبة 23 نقطة مئوية.
نشر برنامج ماجستير الحقوق في الرعاية الصحية
قام أحد مقدمي الرعاية الصحية بتنفيذ تقييم متعدد الطبقات لدعم القرارات السريرية:
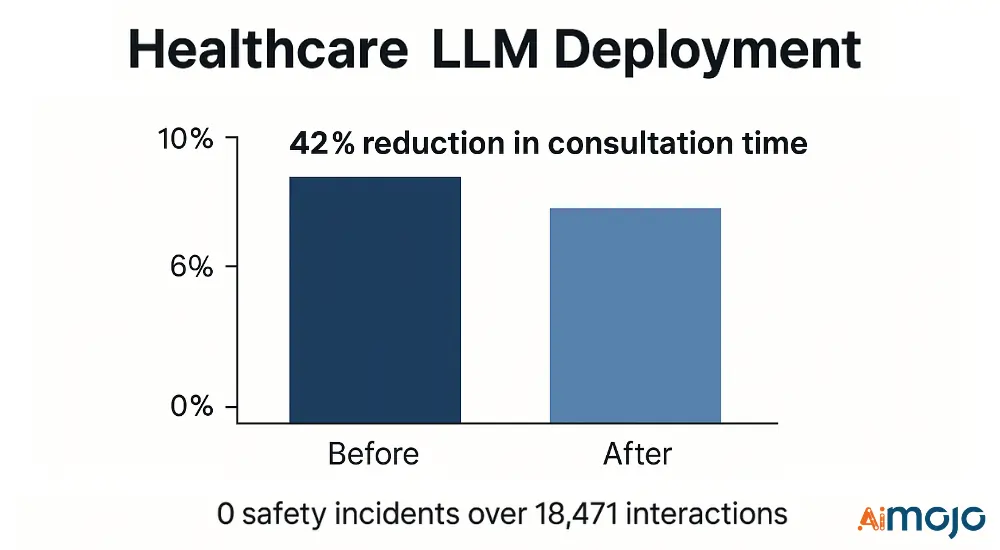
- المقاييس الفنية: درجة NER F1 الطبية (0.91)، ودقة التفكير السريري (87.4%)، ودقة تصفية السلامة (99.2%)
- التنفيذ: خط أنابيب الترشيح ثلاثي المراحل مع محققي الرعاية الصحية المتخصصين
- النتائج: انخفاض بنسبة 42% في وقت الاستشارة مع عدم وجود أي حوادث تتعلق بالسلامة عبر 0 تفاعلًا سريريًا
حدد إطار التقييم 17 حالة فشل حرجة وخفف من حدتها قبل النشر، مما منع الأحداث السلبية المحتملة.
تقييم الماجستير في القانون: خارطة طريقك نحو النجاح
انتقل التقييم الفني لشهادات الماجستير في القانون من مجرد التحقق من الدقة إلى أطر عمل شاملة تُقيّم أبعاد أداء متعددة. المؤسسات التي تتبنى هذه البروتوكولات الصارمة - وتُدمجها - التسجيل الآلي، واختبار المعايير، والإشراف البشري- تحقيق اختيار نموذج أكثر موثوقية ونتائج أقوى.
تكشف خطوط الاختبار التكيفية المنتظمة عن العيوب قبل النشر، مما يجعل تكلفة التقييم الأولي منخفضة مقارنةً بمخاطر تشغيل نظام معيب. بالنسبة لفرق الهندسة، فإن خطوات التحقق القوية أكثر من مجرد... مهام التطوير؛ فهي ضمانات أساسية للأعمال.
في عام 2026 وما بعده، ستتمكن الفرق التي تعمل على تحسين أساليب التقييم الخاصة بها من الحفاظ على موثوقية شهادات الماجستير في القانون الخاصة بها، ومنع الأخطاء المكلفة، والحفاظ على ثقة المستخدم.



 BONUS: احصل على 200 دولارAI "مجموعة أدوات الإتقان" مجانية عند التسجيل!
BONUS: احصل على 200 دولارAI "مجموعة أدوات الإتقان" مجانية عند التسجيل!






